
 English
EnglishTrở lại với chủ đề về các thuật toán cây quyết định Decision trees, như vậy qua các bài viết trước chúng ta đã tìm hiểu về tổng quan thuật toán cây quyết định là gì, làm quen với các dạng thuật toán CART (phân 2 nhánh) sử dụng công thức Goodness of Split, Gini Index và C4.5 (phân nhiều hơn 2 nhánh) sử dụng công thức Entropy kết hợp với Information gain. Trong bài viết lần này chúng ta sẽ cùng đi qua một số kiến thức quan trọng khác bao gồm giới thiệu cơ bản về nguyên tắc Stopping với các phương pháp Pruning (ngắt cành) nâng cao tính hiệu quả của mô hình (tránh vấn đề Overfitting), và một vài những ưu điểm, khuyết điểm của các thuật toán cây quyết định nói chung.
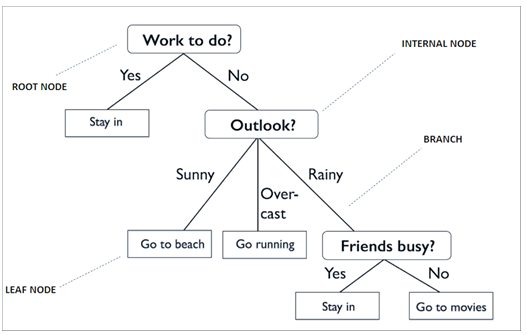
(Nguồn hình Towardsdatascience)
Riêng về phần áp dụng thuật toán cây quyết định cho biến mục tiêu là biến định lượng liên tục (continuous variable) hay còn gọi là Regression task/ Regression tree sẽ được chúng tôi trình bày ở bài viết sắp tới cũng là phần cuối cùng của chủ đề Decision trees. Các bạn có thể tham khảo lại các bài viết trước thông qua các link dưới đây.
Lưu ý quan trọng nếu những bạn chưa có kiến thức gì về Decision trees, cũng như Classification trong Data mining sẽ khó tiếp thu những nội dụng trong bài viết này. Thuật toán Cây quyết định (P.1): Classification & Regression tree (CART)
Thuật toán Cây quyết định (P.2): Classification & Regression tree (Gini index)
Thuật toán Cây quyết định (P.3): C4.5 (Entropy)
Trước khi đi vào giới thiệu cơ bản và tổng quan về các phương pháp Stopping & Pruning (ngừng phân nhánh, ngắt cành) chúng ta cùng điểm qua một số ưu điểm và khuyết điểm của thuật toán cây quyết định.
Ưu điểm & khuyết điểm của thuật toán cây quyết định
Decision trees là một trong những phương pháp Data mining, cụ thể Classification được sử dụng nhiều nhất trong các dự án nghiên cứu dữ liệu, là phương pháp Supervised learning – học có giám sát hiệu quả nhất vì các đặc điểm của nó và được ứng dụng trong mọi khía của các lĩnh vực khác nhau từ kinh tế đến xã hội, không chỉ riêng khoa học dữ liệu, và là mảng kiến thức quan trọng mà bất kỳ chuyên gia phân tích nào phải có.
Tuy nhiên cũng giống như các công cụ phân tích khác, Decision trees có các ưu điểm và khuyết điểm mà chúng ta phải quan tâm, nhìn lại lần nữa, và lấy đó làm cơ sở để áp dụng vào các dự án khai thác dữ liệu sao cho phù hợp, và hiệu quả.
Ưu điểm:
- Thuật toán Decision trees đơn giản, trực quan, không quá phức tạp để hiểu ngay lần đầu tiên, khác với các thuật toán ví dụ như Artificial Neural network không thể hiện rõ quy luật phân loại. Đồng thời bộ dữ liệu training không nhất thiết phải quá lớn để tiến hành xây dựng mô hình phân tích.
- Một số thuật toán cây quyết định có khả năng xử lý dữ liệu bị missing và dữ liệu bị lỗi mà không cần áp dụng phương pháp như “imputing missing values” hay loại bỏ. Bên cạnh đó Decision trees ít bị ảnh hưởng bởi các dữ liệu ngoại lệ (outliers)
- Thuật toán cây quyết định là phương pháp không sử dụng tham số, “nonparametric”, nên không cần phải có các giả định ban đầu về các quy luật phân phối như trong thống kê, và nhờ đó kết quả phân tích có được là khách quan, “tự nhiên” nhất.
- Thuật toán cây quyết định có thể giúp chúng ta phân loại đối tượng dữ liệu theo biến mục tiêu có nhiều lớp, nhiều nhóm khác nhau (multi-class classification) đặc biệt nếu biến mục tiêu là dạng biến định lượng phức tạp.
- Thuật toán cây quyết định có thể áp dụng linh hoạt cho các biến target, biến mục tiêu là biến định tính (classification task) ví dụ phân loại khách hàng theo “rủi ro tín dụng” và “không rủi ro tín dụng” như ví dụ ở 2 bài viết trước, và cả định lượng (regression task) ví dụ ước lượng xác suất khách hàng có rủi ro tín dụng
- Thuật toán cây quyết định mang lại kết quả dự báo có độ chính xác cao, dễ dàng thực hiện, nhanh chóng trong việc huấn luyện, không cần phải chuyển đổi các biến vì kết quả sẽ như nhau với bất kể loại biến dữ liệu biến đổi ra sao.
- Dựa trên quy luật ra quyết định (Decision rule) để xây dựng nên thuật toán cây quyết định rất dễ diễn giải hay giải thích đến người nghe, người xem – những người muốn hiểu rõ về kết quả phân tích nhưng không có kiến thức gì về khoa học dữ liệu.
- Thuật toán cây quyết định vẫn nói lên được mối liên hệ giữa các biến, các thuộc tính dữ liệu một cách trực quan nhất mặc dù không thể hiện được rõ mối quan hệ tuyến tính, hay mức độ liên hệ giữa chúng như phương pháp phân tích hồi quy (regression analysis) có được.
- Ngoài kinh tế, tài chính, thuật toán cây quyết định có thể được ứng dụng trong lĩnh vực y tế, nông nghiệp, sinh học.
Khuyết điểm:
- Thuật toán cây quyết định hoạt động hiệu quả trên bộ dữ liệu đơn giản có ít biến dữ liệu liên hệ với nhau, và ngược lại nếu áp dụng cho bộ dữ liệu phức tạp.
- Cụ thể, thuật toán cây quyết định khi được áp dụng với bộ dữ liệu phức tạp, nhiều biến và thuộc tính khác nhau có thể dẫn đến mô hình bị overfitting, quá khớp với dữ liệu training dẫn đến vấn đề không đưa ra kết quả phân loại chính xác khi áp dụng cho dữ liệu test, và dữ liệu mới.
- Đối với thuật toán cây quyết định khi có sự thay đổi nhỏ trong bộ dữ liệu có thể gây ảnh hưởng đến cấu trúc của mô hình. Nghĩa là khi chúng ta điều chỉnh dữ liệu, cách thức phân nhánh, ngắt cây sẽ bị thay đổi, có thể dẫn đến kết quả sẽ khác so với ban đầu, phức tạp hơn. Các chuyên gia gọi đây là vấn đề “high variance” – giá trị phương sai cao.
- Thuật toán cây quyết định chỉ áp dụng cho biến định tính (classification tree) nếu phân loại sai có thể dẫn đến sai lầm nghiêm trọng ví dụ một người có khả năng bị đột quỵ lại được phân loại là không thì vô tính đặt người này vào tình thế nguy hiểm. Còn đối với thuật toán cây quyết định áp dụng cho biến định lượng (regression tree), thì chỉ phân loại đối tượng, hay dự báo theo phạm vi giá trị (range) được tạo ra trước đó, vì vậy đây cũng là một hạn chế khi khả năng có nhiều phạm vi giá trị khác mà thuật toán chưa xét đến.
- Thuật toán cây quyết định có khả năng “bias” hay thiên vị nếu bộ dữ liệu không được cân bằng. Nói đơn giản, khi bộ dữ liệu được phân ra thành các nhóm theo các đặc trưng khác nhau nào đó, mà số lượng quan sát trong mỗi nhóm là quá chênh lệch hay khác biệt rõ rệt về đặc trưng, lúc này có thể dẫn đến mô hình bị “bias”, phân nhánh đơn giản, chỉ xét đến các giá trị tiêu biểu, và nguy cơ “Underfitting” (không rà soát hết các khả năng phân loại dữ liệu). Tuy nhiên khi mô hình quá phức tạp, mọi biến dữ liệu đều có khả năng phân nhánh và làm cơ sở phân loại các đối tượng dữ liệu, thì lúc này “bias” ở mức thấp nhưng nguy cơ không thể áp dụng được dữ liệu mới.
- Thuật toán cây quyết định yêu cầu bộ dữ liệu training và test phải được chuẩn bị hoàn hảo, chất lượng tốt phải được cân đối theo các lớp, các nhóm trong biến mục tiêu, ví dụ có sự chênh lệch không quá lớn giữa số lượng đối tượng dữ liệu thuộc lớp A của biến mục tiêu và số lượng đối tượng dữ liệu thuộc lớp B của biến mục tiêu. Ngoài ra biến mục tiêu phải có các giá trị “rời rạc” dễ nhận biết, không được quá đa dạng, và phải cụ thể để quá trình phân loại diễn ra dễ dàng hơn cho thuật toán.
- Thuật toán cây quyết định được hình thành trên các cách thức phân nhánh tại mỗi một thời điểm bất kỳ, ở một node hay biến dữ liệu bất kỳ và chỉ quan tâm duy nhất vào việc phân nhánh sao cho tối ưu tại thời điểm ấy, chứ không xét đến toàn bộ mô hình phải được thiết lập hiệu quả ra sao. Do đó sẽ có trường hợp các bạn cảm thấy việc phân nhánh dễ dàng, cứ thế tiếp tục cho đến khi không còn đối tượng dữ liệu để phân loại nhưng khi kết thúc nhìn lại sao mô hình lại quá cồng kềnh, phức tạp. Lúc này thì không thể tìm ra nguyên nhân. Đây cũng chính là khuyết điểm nữa của Decision trees.
- Thuật toán cây quyết định không “hỗ trợ” kỹ thuật hay khả năng “truy vấn ngược” mà chỉ phân nhánh liên tục dựa trên các công thức phân nhánh cho đến khi thấy được kết quả sau cùng nên chúng ta khó phát hiện được các lỗi ở đâu nếu có sai sót.
Vẫn còn rất nhiều ưu điểm khuyết điểm khác mà chúng tôi không thể trình bày hết trong bài viết này. Các bạn nếu muốn tìm hiểu thêm thì đơn giản là hãy thử thực hành xây dựng mô hình Decision trees cho các bộ dữ liệu khác nhau và tiến hành kiểm tra, đánh giá, các bạn sẽ thấy được vấn đề.
Tiếp theo chúng ta cùng đến với phần quan trọng khác, là phương pháp và là mảng kiến thức không thể thiếu khi xây dựng thuật toán cây quyết định. Đó chính là Stopping Criteria, yếu tố ngừng phân nhánh với Pruning method, phương pháp “ngắt cành” sao cho thuật toán Decision trees mang lại kết quả phân loại tối ưu hơn, mô hình hiệu quả hơn.
Stopping criteria (Pruning method)
Giải thích lại tại sao phải áp dụng 2 phương pháp này.
Nếu xây dựng thuật toán cây quyết định trên bộ dữ liệu phức tạp, và sử dụng các công thức như Gini index, hay Entropy mà chúng tôi đã đề cập ở bài viết trước, và ngay trên phần các khuyết điểm thì cây quyết định luôn hướng đến kết quả phân loại sau cùng, phân loại hết thì mới ngưng, cố gắng tìm ra các node, các tập con “pure” nhất đến khi nào không thể phân loại được tiếp. Nhưng điều này sẽ dẫn đến khả năng cao thuật toán đang cố gắng “thỏa mãn” bộ dữ liệu training, “follow” đến từng biến và thuộc tính trong dữ liệu training, xem xét tất cả mối liên hệ giữa chúng và biến mục tiêu, do đó khi áp dụng cho bộ dữ liệu test hay “unseen data”, dữ liệu mà mô hình không thể thấy được giá trị của biến mục tiêu, mô hình sẽ không thể phân loại chính xác. Thuật ngữ quen thuộc có thể coi là “Overfitting”, mô hình được xây dựng quá khớp với dữ liệu training.
Ngược lại trong trường hợp bộ dữ liệu không cân bằng như đã giải thích ở phần khuyết điểm, hay một số nguyên nhân khác khiến cho mô hình Decision trees quá đơn giản, phân nhánh ít, chiều sâu của cây giảm thì nguy cơ cao mô hình bị “Underfitting” là khá cao, nghĩa là mô hình có thể đã bỏ qua một số khả năng, quy luật phân loại đối tượng dữ liệu theo biến mục tiêu mà đáng lẽ ra phải được khai phá. Vì vậy, chúng ta không thể thực hiện xây dựng mô hình Decision trees một cách vội vã, hoặc tùy tiện phân nhánh hay ngắt cành với mong muốn có được kết quả phân tích như mong đợi. Việc hạn chế các vấn đề “Overfitting” và “Underfitting” là công việc mà có lẽ mỗi chuyên gia phân tích dữ liệu phải quan tâm khi tiến hành thiết lập mô hình Decision trees
Cần lưu ý rằng thứ nhất mục đích của quá trình phân tích dữ liệu hay huấn luyện mô hình phân tích là để làm sao khi áp dụng cho bộ dữ liệu thực tế chúng đem lại kết quả chính xác nhất chứ không phải tập trung vào dữ liệu training, thứ hai là không phải phương pháp Stopping criteria hay Pruning lúc nào cũng đem lại hiệu quả, do đó bất kể mô hình nào thì chúng ta cũng phải sử dụng các phương pháp đánh giá (Classification evaluation method) để kiểm tra và đưa ra những điều chỉnh kịp thời.
Lưu ý trong bài viết này chúng tôi gộp chung Stopping criteria hay Stopping rules với Pruning method để diễn giải tốt hơn, và trong thực tế, ở một số giáo trình về Data mining, các tác giả – là những nhà phân tích dữ liệu, thường đưa Pruning method vào trong Stopping criteria vì cho rằng chúng có cùng một đích khi cả 2 phương pháp đều hướng đến tối ưu mô hình cây quyết định. Tuy nhiên cũng có một số giáo trình tách riêng 2 thuật ngữ này để giải thích khi cho rằng Stopping criteria áp dụng trước và trong khi xây dựng mô hình còn Pruning thì áp dụng sau khi đã thiết lập xong mô hình. Cả 2 hướng tiếp cận đều đúng, nên việc trình bày như thế nào không quan trọng bằng cách chúng ta hiểu được vấn đề như thế nào, cần dùng phương pháp nào cho mô hình.
Phương pháp Stopping criteria có thể kể đến đơn giản như các phương pháp hạn chế kích thước hay chiều sâu của cây quyết định bao gồm giới hạn, hay cung cấp số lượng tập con, hay số lượng mẫu (sample) tối thiểu cho một lần phân nhánh từ một node, giới hạn chiều sâu tối đa của cây quyết định, giới hạn tối đa số node cuối cùng, những node không có phân nhánh tiếp theo (terminal node) hay giới hạn tối đa số thuộc tính được dùng để phân nhánh.
Giới thiệu đến các bạn một số nguyên tắc ngừng phân nhánh thông dụng được tham khảo từ một số tài liệu Data mining:
- Khi tất cả các quan sát đều nằm trong một leaf node và cùng mang một giá trị bất kì của biến mục tiêu.
- Khi mô hình cây quyết định đạt chiều sâu tối đa đã được quy định trước đó (theo kinh nghiệm, kiến thức, hay các phương pháp tính toán mà các chuyên gia có thể sử dụng)
- Số lượng các trường hợp (số quan sát) xuất hiện trong các terminal leaf (các node thể hiện kết quả phân loại), thấp hơn số lượng các trường hợp tối thiểu trong node phân nhánh (parent node) được quy định từ trước. Nghĩa là khi xuất hiện trường hợp thấp hơn thì ngừng phân nhánh.
- Số lượng các quan sát ở các terminal leaf thấp hơn số lượng tối thiểu được quy định trước đó, hoặc không vượt quá một tỷ lệ nhất định theo kích thước của mỗi class – tổng số quan sát trong class đó. Nghĩa là khi xuất hiện trường hợp thấp hơn thì ngừng phân nhánh.
- Khi một node được phân nhánh, số lượng các quan sát trong một hoặc nhiều node con (child nodes) ít hơn số lượng các quan sát tối thiểu đặt ra ban đầu. Nghĩa là khi xuất hiện trường hợp thấp hơn thì ngừng phân nhánh.
- Số lượng các thuộc tính dữ liệu, các giá trị của biến, của node phân nhánh được dùng để xác định cách thức phân nhánh đạt giới hạn ban đầu, đạt tối đa.
Các nguyên tắc Stopping trên có thể khiến các bạn khó hiểu, nhưng đều hướng đến yêu cầu xác định trước một ngưỡng giá trị nào đó (threshold), và khi các node, các phân nhánh đạt ngưỡng giá trị này thì cây quyết định sẽ dừng phát triển thêm. Tóm lại chúng ta có thể thiết lập các ngưỡng giá trị và lấy đó làm cơ sở để Stopping:
- Tối thiểu kích thước mẫu hay số lượng quan sát có trong node phân nhánh.
- Tối thiểu kích thước mẫu hay số lượng quan sát có trong leaf node
- Tối đa số lượng thuộc tính dùng để phân nhánh
- Tối đa chiều sâu của cây quyết định
Các nguyên tắc trên có thể sẽ khó hiểu, các bạn có thể tham khảo thêm ví dụ dưới đây để hiểu rõ thêm.
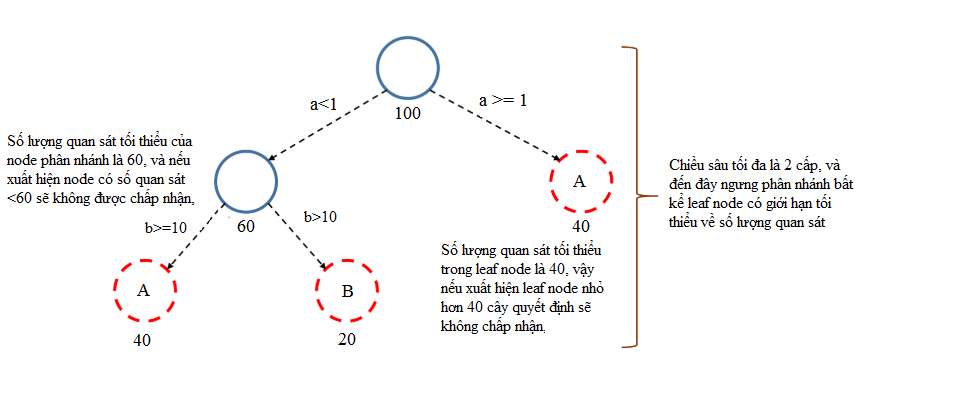
Nguyên nhân tại sao lại xác định được ngưỡng giá trị như vậy thì đó còn phụ thuộc vào nhiều yếu tố từ các phương pháp tính toán, từ kinh nghiệm của các nhà phân tích có được.
Tiếp theo về phương pháp Pruning. Pruning là phương pháp giảm kích thước của cây quyết định bằng cách giảm các “section”, các phần không hợp lý trong mô hình cây quyết định, giảm tính phức tạp của quy luật phân loại được khai phá. Pruning thì có 2 phương pháp chính là Pre-pruning (ngắt cành trước khi cây quyết định được hoàn thành, còn gọi là early-stopping) và Post-pruning (ngắt cành sau khi mô hình cây quyết định được hoàn thành). Pre-pruning hiểu đơn giản là ngừng phân nhánh tiếp cho cây quyết định khi nhận thấy thông tin không còn đáng tin cậy, còn Post – pruning là loại bỏ những leaf node, những phân nhánh không cần thiết sau khi thiết lập xong mô hình, để tối ưu hiệu quả cho mô hình cho đến khi không thể tối ưu hơn thì ngừng việc loại bỏ.
Phương pháp Stopping có thể làm giảm hiệu suất của cây quyết định mặc dù nó cố gắng hạn chế khả năng overfitting, nhưng vẫn có nguy cơ underfitting như ví dụ ở trên, khi cây quyết định phân nhánh quá đơn giản. Pruning là phương pháp khá linh hoạt nó cho phép ngắt cây, dừng phân nhánh trong lúc thực hiện xây dựng cây quyết định (gần giống nguyên lý hoạt động của Stopping criteria) hoặc sau khi xây dựng xong cây quyết định như một cách thức “tỉa, chỉnh sửa lại cành”. Đầu tiên là phương pháp Pre-pruning, tối ưu cây quyết định trước nó được hoàn thành. Nguyên tắc để áp dụng Pre-pruning như sau:
- Ngừng phân nhánh nếu tất cả các quan sát nằm trong cùng một phân lớp
- Ngừng phân nhánh nếu tất cả các giá trị của biến dữ liệu là như nhau
Một số quy tắc “khắt khe” hơn:
- Ngừng phân nhánh nếu số quan sát trong node thấp hơn giá trị tối thiểu, ngưỡng xác định trước đó (giống stopping rule)
- Ngừng phân nhánh nếu node không cải thiện mức độ đồng nhất lấy kết quả từ các công thức như Gini index hay Entropy mà chúng tôi giới thiệu ở các bài viết trước.
- Ngừng phân nhánh nếu cách phân phối của các quan sát trong class độc lập với các thuộc tính, các biến của dữ liệu (sử dụng kiểm định chi bình phương trong thống kê để kiểm tra). Quy tắc và cách thức thực hiện khá phức tạp các bạn có thể tham khảo thêm các tài liệu bên ngoài để biết thêm chi tiết. Ở đây chúng tôi chỉ giới thiệu thêm đến các bạn.
- Ngừng phân nhánh nếu sai số tổng quát (Generalized errors) đã thấp hơn ngưỡng giá trị cho trước. Generalized errors là giá trị được ước tính từ kết quả kiểm thử mô hình so với kết quả từ quá trình huấn luyện.
Về phương pháp Post – pruning, tức phân nhánh sau khi cây quyết định được hình thành, và chọn ra những phần (subtrees) trên mô hình để tiến hành điều chỉnh. Cụ thể phương pháp pruning bao gồm các bước sau:
- Xây dựng cây quyết định hoàn chỉnh cho bộ dữ liệu training, phân loại hết các đối tượng trong tập dữ liệu này theo biến mục tiêu đã cho.
- Ước tính độ hiệu quả của cây quyết định lúc này sử dụng các phương pháp đánh giá mô hình phân loại hay những phương pháp khác.
- Chọn ra các subtree không hiệu quả và xác định phương thức điều chỉnh “subtree raising” hay “subtree replacement”.
- Sử dụng các phương pháp ước tính độ hiệu quả kết hợp với các phương pháp ở bước 2 để đánh giá mô hình sau khi điều chỉnh, đây chính là cơ sở để xem xét liệu pruning có hiệu quả hay không. Lưu ý các phương pháp đánh giá ở bước này khác với bước 2.
- Tiếp tục review kết quả và điều chỉnh cho đến khi mức độ hiệu quả được ước tính là cao nhất.
Xét về cách thức điều chỉnh thì Post-pruning có 2 loại:
- Subtree replacement: còn gọi là phương pháp bottom-up, thu gọn cây quyết định từ dưới lên tức là loại bỏ hay gộp chung một phần các node và phân nhánh lại thành một nhánh duy nhất nếu Generalized error được cải thiện, và nhãn của phân nhánh này sẽ là giá trị hay thuộc tính mà nhiều quan sát có chung nhất.
Các bạn cùng xem qua ví dụ dưới đây để hiểu rõ hơn:
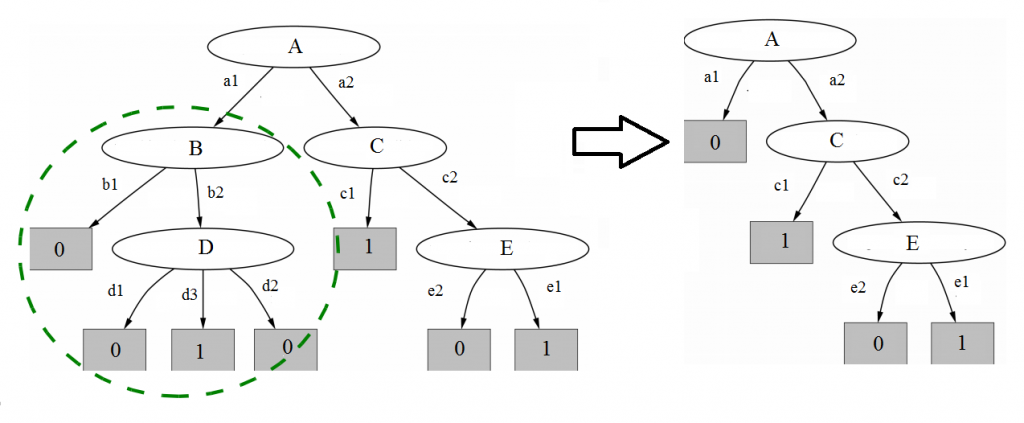
- Subtree raising: còn gọi là phương pháp top-down, điều chỉnh cây quyết định theo hướng từ trên xuống tức loại bỏ một node phân nhánh, đưa các quan sát trong node này xuống với node phân nhánh phía dưới. Hoặc theo cách giải thích khác thì phương pháp này xóa bỏ các node và phân nhánh thừa, thay vào đó lấy những phần subtree có các phân nhánh xuất hiện phổ biến trong cây quyết định, tức bên trên có phân nhánh b1, b2 từ node B, và các ở node phân nhánh phía dưới có xuất hiện lại tương tự các phân nhánh này thì chúng ta có thể rút gọn lại. Các bạn xem một trong số cái ví dụ về Subtree raising dưới đây để hiểu rõ hơn.
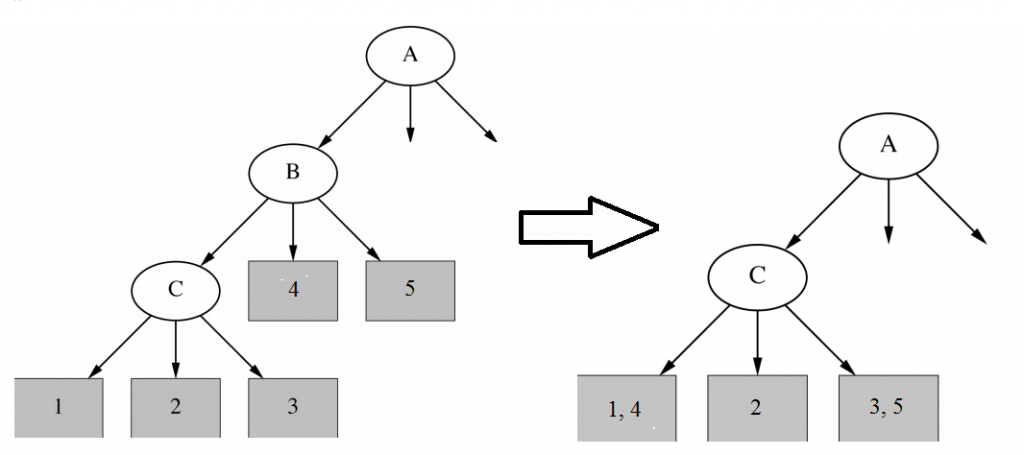
Tóm lại đơn giản là subtree replacement tức là các phương pháp rút gọn mô hình cây quyết định theo hướng từ dưới lên, còn subtree raising là các phương pháp rút gọn mô hình cây quyết định theo hướng từ trên xuống.
Phần quan trọng tiếp theo và cũng là sau cùng của bài viết đó chính là dựa trên những cơ sở yếu tố nào mà chúng ta thực hiện phương pháp pruning? Trong Data mining chúng ta có các phương pháp có thể đánh giá tổng quan độ hiệu quả của mô hình cây quyết định sau khi pruning phổ biến dưới đây. Các phương pháp dựa trên cơ sở xác định mức độ phức tạp của mô hình (complexity) dẫn đến mức độ sai sót khi phân loại là như thế nào, và mô hình cây quyết định nào có độ sai sót thấp nhất sẽ được chọn.
- Generalized errors, sai sót tổng quát, là giá trị được ước tính từ kết quả kiểm thử mô hình so với kết quả từ quá trình huấn luyện. Mô hình cây quyết định sau khi pruning có Generalized errors càng thấp chứng tỏ phương pháp pruning hiệu quả, và mô hình này khả năng sẽ được chọn để phân loại cho dữ liệu thật.
- Resubstitution errors là phương pháp đánh giá xem bộ dữ liệu training có đại diện tốt cho tổng thể dữ liệu hay không dựa trên mô hình cây quyết định đã được xây dựng. Resubstitution errors là cơ sở để tính toán và ước lượng Generalized errors, tương tự nếu chỉ số này thấp thì pruning càng thể hiện độ hiệu quả. Generalized errors xét trên bộ dữ liệu test, và Resubstitution errors xét trên dữ liệu training.
- Phương pháp Occam’s Razor, dựa trên cơ sở mô hình nào ít phức tạp sẽ tốt hơn sẽ ít bị overfitting, là phương pháp chọn ra các mô hình nào đơn giản hơn. Trong phương pháp này 2 mô hình cây quyết định với cùng Generalized errors, thì mô hình nào đơn giản hơn sẽ được chọn
- Optimistic approach: là phương pháp ước lượng Generalized errors bằng cách lấy thẳng giá trị của Resubstitution errors của dữ liệu training làm giá trị ước lượng. Đây là hướng tiếp cận lạc quan cho rằng tỷ lệ sai sót của mô hình áp dụng cho dữ liệu training sẽ giống như khi áp dụng cho dữ liệu test.
- Pessimistic approach: là hướng tiếp cận bi quan, cho rằng nếu chỉ dựa trên việc áp dụng dữ liệu training thì không đủ cơ sở để đánh giá hiệu quả của toàn bộ mô hình. Công thức như sau
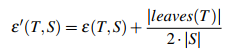
Với e(T,S) là Resubstitution errors và e’(T,S) là Generalized errors, leaves(T) là số node lá có trong mô hình cây quyết định, S là kích thước mẫu.
- Reduce Error pruning (REP): sử dụng phương pháp validation data set để ước lượng Generalized errors tức chia tập dữ liệu training ra thành 2 phần, một phần để huấn luyện mô hình và một phần để ước lượng sai sót.
- Minimum description length (MDL) dựa trên học thuyết về thông tin Information theory. Ví dụ cho các bạn dễ hiểu giả sử có 2 người A, B được cung cấp một bộ dữ liệu có các giá trị và biến đã biết trước. Người A biết rõ mỗi đối tượng trong tập dữ liệu được phân loại ra sao trong khi người B thì không biết. Người B yêu cầu người A truyền đạt lại thông tin cho mình. Người A lúc này sẽ xây dựng một cây quyết định mà thể hiện rõ nhất mối quan hệ giữa biến mục tiêu và các biến đầu vào. Giả sử mô hình lúc này được mã hóa để truyền đạt thông tin đến người, và thông tin lúc này là “bit”. Nếu mô hình chính xác 100% thì cost truyền đạt thông tin sẽ bằng cost mã hóa. Công thức tổng quát như sau:

Cost chính là số lượng bit cần để mã hóa, giá trị càng thấp sẽ càng tốt. Cost(data/model) là số lượng thông tin cần để mã hóa các sai sót của mô hình, Cost(model) là số lượng thông tin cần để mã hóa tất cả các node, và kể cả điều kiện phân nhánh. Còn rất nhiều phương pháp đánh giá độ hiểu quả của mô hình cây quyết định khi tiến hành pruning như Estimating Statistical Bounds (ESB), Error-Based pruning (MEP), Cost complexity pruning, v.v Các bạn có thể tham khảo thêm ở các tài liệu khác. Như vậy đến đây là kết thúc bài viết phần 4 về Decision trees, ở bài viết cuối cùng phần 5 chúng ta sẽ cùng đi qua cách thức triển khai thuật toán cây quyết định cho biến mục tiêu là biến định lượng liên tục (Regression trees) và Decision rules cơ sở diễn giải mô hình cây quyết định.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.