
 English
EnglishTrở lại với chủ đề bài viết về phân tích dự báo – Predictive analytics, ở phần 1, BigDataUni đã giới thiệu đến các bạn thế nào là phân tích dự báo, phân biệt nó với Data analytics, Descriptive analytics (phân tích mô tả) và Prescriptive analytics (phân tích đề xuất), còn phần 2 lần này chúng tôi sẽ đi vào trình bày một cách tổng quan về bản chất, cách thức vận hành, quy trình, và các thuật toán hay kỹ thuật phân tích được sử dụng trong Predictive analytics. Dành cho các bạn nào chưa đọc phần 1: Tổng quan về Predictive analytics (P.1) Nhưng trước khi đi vào bàn luận nội dụng chính của bài viết, chúng ta cùng tìm hiểu sơ qua về Predictive modeling (mô hình dự báo), Data mining (khai phá dữ liệu) vì 2 thuật ngữ này có liên quan đến Predictive analytics.

Mối quan hệ giữa Predictive modeling và Data mining với Predictive analytics
Phân tích dự báo là nền tảng để xây dựng các mô hình dự báo được sử dụng hỗ trợ trong các hoạt động kinh doanh hàng ngày ở mỗi tổ chức. Nhắc lại định nghĩa về Predictive analytics ở phần 1 của MathWorks – công ty chuyên cung cấp các phần mềm tin học tính toán ví dụ nổi tiếng như MATLAB: “Phân tích dự báo sử dụng dữ liệu cùng với kỹ thuật phân tích, thống kê và học máy để tạo ra một mô hình dự báo để dự báo các sự kiện trong tương lai. Thông thường, dữ liệu lịch sử được sử dụng để xây dựng một mô hình toán học để nắm bắt các xu hướng quan trọng. Mô hình dự báo đó sau đó được sử dụng trên dữ liệu hiện tại để dự báo điều gì sẽ xảy ra tiếp theo hoặc để đề xuất các hành động cần thực hiện để đạt được kết quả tối ưu.”
Mô hình dự báo liên quan đến việc chạy các thuật toán trên bộ dữ liệu để đưa ra những dự báo về các đối tượng nghiên cứu trong tương lai và quá trình này được lặp đi lặp lại sao cho mô hình được “đào tạo” sẽ mang lại các thông tin giá trị, phù hợp, chính xác nhất để mang vào sử dụng trong các hoạt động kinh doanh hàng ngày ở các tổ chức.
Các bạn có thể hiểu đơn giản như sau, ví dụ lần đầu khi triển khai Predictive analytics, một công ty thu thập nguồn dữ liệu khổng lồ từ khách hàng và sử dụng các công cụ phân tích dự báo để dự báo hành vi mua hàng của khách hàng trong tương lai, và kết quả dự báo chỉ gần chính xác so với thực tế, vẫn còn nhiều điểm chưa phù hợp. Lần thứ hai, công ty thay đổi trong cách lựa chọn thuật toán, kỹ thuật phân tích, hay xem xét lại các yếu tố nghiên cứu có thể tác động đến kết quả dự báo, và kết quả dự báo đã chính xác hơn nhưng chưa hẳn đã chính xác tuyệt đối, lúc này công ty có thể xây dựng một mô hình dự báo dựa trên các thuật toán, các yếu tố liên quan đã được kiểm chứng (chứ không phải thực hiện lại một quy trình phân tích dự báo mới) và đưa vào sử dụng cho các lần kế tiếp. Với dữ liệu khách hàng luôn thay đổi và phức tạp, tương tự các phương pháp phân tích, kỹ thuật dự báo cũng đổi mới, thì mô hình dự báo phải luôn được “đào tạo”, được nâng cấp sao cho phù hợp nhất, tối ưu nhất để đưa vào sử dụng.
Theo chúng tôi, Predictive modeling và Predictive analytics khác biệt rõ nhất chính là ở quy trình vận hành. Ví dụ ở phân tích dự báo, khi mỗi lần triển khai một dự án khai thác dữ liệu thì mỗi công ty luôn phải đầu tiên xác định mục tiêu nghiên cứu, mục đích sử dụng phân tích dự báo, còn ở Predictive modeling thì không, các mục tiêu đã được xác định từ trước và được sử dụng cho các lần tiếp theo; tương tự như cách thức thu thập, chuẩn bị dữ liệu cho giai đoạn phân tích, thì ở Predictive analytics, mỗi lần triển khai chúng ta phải tìm hiểu cách thức nào hiệu quả nhất, còn Predictive modeling thì quy trình thu thập, chuẩn bị dữ liệu gần như được chuẩn hóa nếu mô hình đó đã tối ưu.
Nói tóm lại, nếu muốn triển khai Predictive analytics (ví dụ đã thử nghiệm trước đó) ở các lần tiếp theo, thì mỗi công ty cần xây dựng một mô hình cụ thể, quá trình này gọi là Predictive modeling. Ví dụ, các bạn có thể thấy giả sử mà mỗi ngày Đài khí tượng Thủy văn phải lặp đi lặp lại việc tạo ra một quy trình dự báo thời tiết mới mà không dùng mô hình dự báo trước đó thì chừng nào chúng ta mới nhận được tin dự báo thời tiết trong ngày, và các ngày sắp tới.
Do đó, ở phần sau của bài viết, khi BigDataUni giới thiệu về cách thức triển khai phân tích dự báo, hay quy trình phân tích dự báo, các bạn sẽ thấy bước “thiết lập mô hình”. Theo các chuyên gia, việc xây dựng, đánh giá, phát triển các mô hình sẽ quyết định sự thành công, năng lực của mỗi công ty trong việc đưa ra dự báo về khách hàng, thị trường kinh doanh trong tương lai.
Bên cạnh Predictive modeling, chúng ta cũng tìm hiểu sơ qua về Data mining (khai phá dữ liệu) vì các quy trình và thuật toán trong Data mining được sử dụng như bước khởi đầu trong phân tích dự báo. Ở phần 1 bài viết, các bạn có thể thấy thuật ngữ Data mining xuất hiện bên trong những khái niệm về Predictive analytics.
Để chứng minh luận điểm trên, chúng ta hãy xem qua trích dẫn trong cuốn sách “Applied Predictive Analytics: Principles and Techniques for the Professional Data Analyst” của tác giả Dean Abbott, xuất bản bởi John Wiley & Sons, Inc.
“The Cross-Industry Standard Process Model for Data Mining (CRISP-DM) describes the data-mining process in six steps… The CRISP-DM name itself calls out data mining as the technology, but the same process model applies to predictive analytics and other related analytics approaches, including business analytics, statistics, and text mining.”
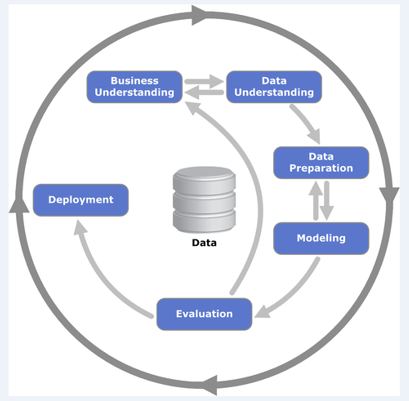
Data mining được triển khai bởi một quy trình tiêu chuẩn quốc tế, được nhiều tổ chức kiểm chứng, gọi là CRISP-DM. CRISP-DM gồm 6 bước như hình dưới đây, và quy trình này có thể được dùng cho Predictive analytics và phân tích kinh doanh, thống kê. Theo tác giả của cuốn sách, bước “Modeling” của CRISP-DM, chính là bước thiết lập mô hình dự báo (Predictive model), mô hình phân tích mô tả (Descriptive model).
Ngoài ra, theo định nghĩa của SAS – công ty chuyên cung cấp các phần mềm, giải pháp lưu trữ và phân tích dữ liệu toàn cầu – Data mining là công tụ để hỗ trợ dự báo: “Data mining là quá trình tìm kiếm các chi tiết bất thường (anomalies), các mẫu, mô hình, quy luật của dữ liệu và mối tương quan giữa các tập dữ liệu lớn để dự đoán kết quả, thiết lập các dự báo. Bằng cách áp dụng một loạt các kỹ thuật khác nhau, thông tin có được từ Data mining sẽ hỗ trợ tăng doanh thu, cắt giảm chi phí, cải thiện mối quan hệ khách hàng, giảm rủi ro,..”
Để hiểu rõ về Data mining, cũng như quy trình CRISP-DM, mời các bạn tham khảo các bài viết của BigDataUni về Data mining:
Tổng quan về Data mining (P.1): Data mining là gì
Tổng quan về Data mining (P.2) Ứng dụng của Data mining
Tổng quan về Data Mining (P.3) Quy trình và phương pháp
Những quan điểm về Predictive modeling và Data mining, cũng như mối liên hệ của chúng với Predictive analytics được chúng tôi trình bày ở trên gửi đến các bạn để tránh các bạn bị nhầm lẫn, thắc mắc khi các bạn tìm kiếm tài liệu hay tìm hiểu sâu hơn về Predictive analytics.
Lưu ý rằng: lĩnh vực khoa học dữ liệu là rất rộng, có nhiều mảng, khía cạnh khác nhau, và ý kiến của nhiều chuyên gia đôi khi cũng khác nhau, do đó chúng ta cũng không thể khẳng định tuyệt đối ví dụ như bên trong quy trình phân tích dự báo phải có Predictive modeling, hoặc Predictive modeling là một công cụ khai thác dữ liệu hoàn toàn khác biệt với Predictive analytics, hoặc quy trình Data mining có thể sử dụng cho Predictive analytics ở bất kỳ trường hợp nào.
Để trình bày bài viết với góc độ khách quan, BigDataUni sẽ cố gắng giới thiệu đầy đủ những nhận định về bản chất, quy trình, các kỹ thuật khác nhau trong Predictive analytics.
Bản chất của Predictive analytics
Predictive analytics kết hợp sức mạnh từ một loạt các phương pháp bao gồm Data mining, thống kê, Machine learning, các công thức toán học khác. Các tổ chức sử dụng phân tích dự báo để phân tích dữ liệu hiện tại và lịch sử để phát hiện các xu hướng và dự báo những sự kiện sẽ xảy ra tại một thời điểm cụ thể trong tương lai, dựa trên việc tìm hiểu các yếu tố có thể tác động, hay mối liên hệ của chúng đến đối tượng dự báo.
Nói cách khác, nền tảng của phân tích dự báo chính là khả năng nó có thể mô hình hóa hầu hết mọi thứ. Giả định rằng có một mối quan hệ nguyên nhân và kết quả giữa các tham số dữ liệu (đối tượng nghiên cứu), tức là khi một số tham số dữ liệu thay đổi (nguyên nhân), sẽ có một thay đổi tương ứng với các tham số dữ liệu khác (kết quả). Các bạn cùng BigDataUni tìm hiểu qua ví dụ dưới đây để nắm được một phần bản chất của phân tích dự báo. Những mô hình dự báo sẽ được xây dựng dưới một công thức ví dụ như sau:
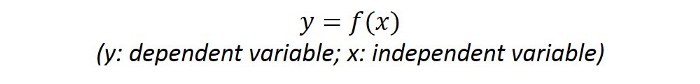
Các yếu tố nguyên nhân là biến x: biến độc lập, và kết quả dự báo là biến y: biến phụ thuộc vào x. Lấy ví dụ tìm hiểu về mối liên hệ giữa sản lượng sản xuất một sản phẩm A (biến x) và giá sản phẩm A đó trên thị trường (biến y). Dùng công thức của thuật toán tương quan (Correlation) và hồi qui (Regression), chúng ta tìm được phương trình y = – 0.0741x + 37.708
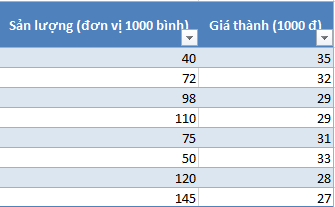
Dữ liệu lấy từ sách “Nguyên lý thống kê ứng dụng trong kinh tế” của Đại học Kinh tế TP.HCM
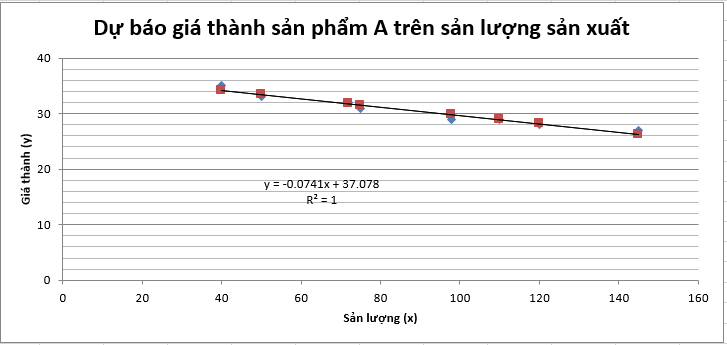
Biểu đồ thể hiện phương trình hồi quy vẽ trong phần mềm Excel
Dựa vào phương trình, chúng ta sẽ dễ dàng dự báo giá thành sản phẩm A nếu sắp tới sản lượng sản xuất có thể giảm hoặc tăng. Ví dụ sản lượng dự báo tăng lên 150000 vậy giá thành sẽ là 25.963 đồng
Đây chỉ mới là một cách thức dự báo, ví dụđơn giản của Predictive analytics. Các thuật toán tương quan và hồi qui chính là kĩ thuật phân tích có trong Data mining và thống kê (Statistics), lần nữa dẫn chứng cho các khái niệm của phân tích dự báo giới thiệu trong phần 1.
Một mô hình dự báo dĩ nhiên không thể đơn giản như vậy, thực tế cho thấy cũng vậy, giá thành một sản phẩm không chỉ dựa vào sản lượng sản xuất mà còn dựa vào nhiều yếu tố khác như khả năng chi trả của khách hàng, mục tiêu lợi nhuận của công ty, chi phí kinh doanh. Mô hình sẽ rất phức tạp không chỉ có mỗi biến x, mà sẽ xuất hiện thêm x(1) đến x(n). Như chúng tôi đã nói ở đầu bài viết, mô hình dự báo không thể hoàn hảo ngay từ đầu, phải được “đào tạo”, cải thiện sao cho hợp lý nhất để đưa vào sử dụng.
Lấy những trường hợp thực tế về một số mô hình dự báo như: Mô hình dự báo giá cổ phiếu dựa trên doanh thu của công ty, lợi nhuận của công ty, giá cổ phiếu trong quá khứ, giá cổ phiếu của đối thủ cạnh tranh, các yếu tố thị trường khác. Mô hình dự báo khả năng thanh toán nợ của khách hàng dựa trên điểm tín dụng (credit score), thu nhập hàng tháng của khách hàng, nghề nghiệp, tuổi tác, tình trạng hôn nhân, v.v. Ngoài ra còn có mô hình dự báo khả năng khách hàng rời dịch vụ, mô hình dự báo khả năng hỏng hóc của thiết bị, máy móc, v.v. Nếu xét về loại kết quả dự báo, thì chúng ta có thể có:
- Dự đoán kết quả dạng định tính: Ví dụ dự báo khách hàng sẽ rời dịch vụ (Có / Không)?
- Dự đoán khả năng xảy ra sự cố, rủi ro: Ví dụ xác suất (%) khách hàng vỡ nợ là gì?
- Dự đoán một giá trị hữu hình: Ví dụ số tiền thực tế khách hàng sẽ vay là bao nhiêu?
Một số nhận định khác về bản chất của Predictive analytics như theo tài liệu Havard Business Review “Predictive Analytics in Practice”, một quy trình phân tích dự báo hiệu quả cần phải có 3 thành phần sau:
- Data – thách thức phổ biến nhất mà các tổ chức luôn đối mặt khi đang cố gắng thực hiện phân tích dự báo đó chính là thiếu dữ liệu đáng tin cậy, dữ liệu chất lượng.
- Statistics (thống kê) – phân tích hồi quy (Regression), ước lượng mối quan hệ giữa các biến khác nhau, là công cụ chính cần sử dụng để phân tích dự báo.
- Assumptions (giả định) – mọi mô hình dự báo đều có một giả định đằng sau nó, và điều quan trọng là phải biết giả định đó là gì và theo dõi, kiểm tra xem nó có đúng không. Giả định cơ bản trong phân tích dự báo chính là: “Tương lai sẽ tiếp tục bắt chước quá khứ.”
Các công ty có thể thu thập đầy đủ dữ liệu liên quan, phát triển đúng loại mô hình thống kê và theo dõi các giả định của họ một cách cẩn thận thường sẽ đưa ra các dự báo chính xác hơn về tương lai.
Theo Talend và SAS, các công ty chuyên cung cấp các giải pháp dữ liệu, phân tích dự báo là một loại “ma thuật”, nhưng nó bắt nguồn từ khoa học thống kê, và những thuật toán tiên tiến khác mà chúng tôi sẽ trình bày ở các phần sau. Cốt lõi mô hình dự báo liên quan đến việc cung cấp thông tin về các biến cụ thể trong một tập dữ liệu lớn, tính toán các trọng số, dùng chúng để tìm ra xác suất của một sự kiện nào đó xảy ra trong tương lai. Predictive analytics sử dụng các kết quả đã biết để phát triển (hoặc đào tạo) một mô hình có thể được sử dụng để dự đoán các giá trị cho những dữ liệu khác nhau hoặc dữ liệu mới.
Bên cạnh mô hình phân tích hồi quy (Regression), thì Predictive analytics còn có mô hình phân loại (Classification). Nếu Regression model dự báo một con số cụ thể ví dụ một khách hàng sẽ tạo ra bao nhiêu doanh thu trong năm tới, thì Classification model sẽ dự báo giữa có hoặc không, giữa 0 và 1, như dự báo biến nhị phân ví dụ khách hàng có rời dịch vụ hay không (có hoặc không), điểm tín dụng của khách hàng như thế nào (tốt hay xấu), tương tự loại dự báo mà chúng tôi vừa trình bày ở trên.
Còn theo Datamation, là tổ chức cung cấp các tin tức, nghiên cứu, review về những giải pháp công nghệ mới như I.oT, Big Data, AI,…, cho rằng Predictive analytics là lĩnh vực nghệ thuật và khoa học tạo ra các hệ thống và mô hình dự đoán. Những mô hình này, với sự điều chỉnh theo thời gian, có thể đưa ra một kết quả dự báo với xác suất xảy ra trong tương lai cao hơn nhiều so với phỏng đoán đơn thuần.
Phân tích dự báo được sử dụng như một thuật ngữ bao hàm các loại phân tích liên quan khác. Chúng bao gồm các (Descriptive analytics) phân tích mô tả, cung cấp cái nhìn sâu sắc về những gì đã xảy ra trong quá khứ; và phân tích đề xuất (Prespective analytics), được sử dụng để cải thiện tính hiệu quả của các quyết định trong tương lai. Như vậy chúng ta đã tìm hiểu sơ qua về bản chất của phân tích dự báo, phần tiếp theo chúng ta sẽ cùng đi vào bàn luận về quy trình phân tích dự báo.
Quy trình phân tích dự báo
Mục đích của chủ đề bài viết là giới thiệu “tổng quan” về Predictive analytics nên ở phần này chúng tôi sẽ không đi vào chi tiết cụ thể ở từng bước (điều mà các trang web cung cấp những tài liệu hướng dẫn về lĩnh vực Data science thường làm) ví dụ như làm sạch dữ liệu, xử lý missing values bằng cách nào mà chúng tôi chỉ trình bày một cách chung nhất, nhưng đầy đủ về những quy trình khác nhau của phân tích dự báo. Nếu có dịp, BigDataUni sẽ cung cấp một bài viết riêng về một case study cụ thể sử dụng phân tích dự báo và thể hiện chi tiết từng bước, mong các bạn thông cảm.
Các công ty thường tìm ra các cơ hội, sáng kiến kinh doanh thông qua việc xác định vấn đề và tìm kiếm giải pháp. Sau khi một vấn đề kinh doanh được xác định, những giải pháp sẽ được đề xuất và đem ra so sánh để sao cho tổ chức tìm ra được giải pháp tốt nhất. Giải pháp ấy sẽ được triển khai vào thực tế, và nếu có vấn đề khác xảy ra, thì quy trình này sẽ được lặp lại để tìm ra giải pháp tốt hơn. Đây chính là cách mà mỗi công ty mở rộng và phát triển.
Chúng ta xem xét tương tự cho quá trình phân tích dự báo. Giả sử một công ty muốn bắt đầu một dự án khai thác nguồn dữ liệu nào đó, thì đầu tiên họ phải xác định vấn đề kinh doanh, mục tiêu họ mong muốn. Ví dụ công ty đó nhận thấy rằng mình cần dự báo được hành vi mua hàng của khách hàng thông qua phân tích dữ liệu. Vậy thì mục tiêu khai thác dữ liệu của công ty đã cụ thể hơn. Đó chính là phải tạo ra một mô hình dự báo hành vi khách hàng. Vấn đề kinh doanh đã được xác định, tiếp theo công ty cần xây dựng các bước hành động, giải pháp.
Để xây dựng mô hình, các nhà phân tích sau đó phải xác định những dữ liệu nào sẽ được sử dụng, họ cần xem xét loại dữ liệu nào có khả năng đưa vào phân tích và có đem lại kết quả dự báo chính xác, giúp cải thiện mô hình hay không? Nguồn dữ liệu có dồi dào, sẵn có hay không? Việc tiếp cận, và thu thập những dữ liệu ấy có dễ dàng hay không? Sau khi dữ liệu được thu thập, bước tiếp theo là chuẩn bị dữ liệu để phân tích. Các nhà phân tích tiếp tục chuẩn hóa và làm sạch dữ liệu, nhiệm vụ bao gồm xử lý các giá trị bị thiếu, loại bỏ các giá trị ngoại lệ của dữ liệu khả năng tác động xấu đến kết quả dự báo và tiến hành tổ chức lại dữ liệu để bắt đầu cho giai đoạn phân tích. Tiếp đến ở giai đoạn phân tích, các nhà phân tích sẽ sử dụng nhiều công cụ, phương pháp, thuật toán một cách thích hợp để chạy thử nghiệm trên một bộ dữ liệu mẫu mục đích tạo ra các mô hình dự báo khác nhau.
Sau khi được “đào tạo” trên dữ liệu mẫu, các mô hình sẽ được áp dụng cho tập dữ liệu đầy đủ và được đánh giá để xem mô hình nào phù hợp nhất và mức độ tạo ra kết quả phân tích mà công ty mong muốn.
Nhiệm vụ cuối cùng là đưa mô hình đã chọn áp dụng vào các quy trình kinh doanh để hỗ trợ cho việc ra quyết định và hoạch định chiến lược. Và nếu khi triển khai mô hình dự báo ấy, mà công ty tiếp tục gặp nhiều vấn đề kinh doanh hoặc công ty muốn phát triển, nâng cao năng lực dự báo của mình, thì quá trình phân tích dự báo phải bắt đầu lại ở điểm xuất phát, để tìm ra được những mô hình mới tốt hơn.
Các bạn hãy quay lại xem đoạn văn thứ 2 trong phần này, các bạn sẽ thấy điểm giống nhau giữa quá trình Predictive analytics và cách một công ty phát triển như thế nào (so sánh 2 dòng gạch chân). Điểm giống nhau ấy chính là các quá trình sẽ được lặp đi lặp lại như một vòng luẩn quẩn liên tục tiếp diễn (còn gọi là “Virtuous cycle”) sao cho công ty phải đạt được những kết quả, giải pháp tốt hơn trước đó.
Tóm lại cho các bạn dễ hiểu, một quy trình phân tích dự báo “không chỉ” hay nói cách khác là “không thể” dừng lại cho đến khi nó tìm ra được một mô hình dự báo tối ưu nhất nhưng trong thực tế không có một mô hình nào là hoàn hảo. Vì dữ liệu ngày nay luôn thay đổi như cách con người chúng ta thay đổi, tương tự như môi trường kinh doanh, xu hướng phát triển công nghệ, v.v nên nếu công ty giữ nguyên một mô hình dự báo thì chắc chắn nó sẽ không còn phụ hợp để đưa vào sử dụng trong thực tế hoặc tương lai.
Tiếp theo chúng ta cùng đi qua một số quy trình mẫu của phân tích dự báo.
Như ở đầu bài viết chúng tôi có đề cập về quy trình CRISP-DM của Data mining có thể áp dụng cho Predictive analytics, nguyên nhân vì bản chất của phân tích dự báo là đi tìm những thông tin có giá trị ẩn chứa bên trong dữ liệu lịch sử để làm cơ sở đưa ra kết quả dự báo. CRISP-DM gồm 6 bước:
- Business understanding: xác định mục tiêu kinh doanh, mục đích phân tích dự báo
- Data understanding: hiểu rõ dữ liệu nào cần thu thập, dữ liệu liên quan có khả năng đưa ra kết quả dự báo.
- Data preparation: bao gồm việc thu thập, làm sạch, tích hợp, chọn lọc, chuyển đổi dữ liệu để chuẩn bị cho quá trình phân tích
- Modeling: sau khi đã có dữ liệu, tiếp theo thiết lập mô hình dựa trên các thuật toán phù hợp với mục đích phân tích dự báo và nghiên cứu, ví dụ Regression, Classification model, v.v.
- Evaluation: thử nghiệm, đánh giá, cải thiện độ hiệu quả của mô hình dự báo, ví dụ phân chia bộ dữ liệu thành “Training data set”, dùng để huấn luyện mô hình, và “Test data set” để kiểm chứng mô hình trước khi đưa vào sử dụng.
- Deployment: đưa vào triển khai mô hình dự báo trong các hoạt động kinh doanh nếu mô hình dự báo đã được kiểm chứng về độ hiệu quả. Bước này bao gồm cả trình bày các kết quả dự báo dưới các báo cáo, các “dashboard”, để các cấp quản lý cùng bàn luận với nhân viên và đề xuất các chiến lược hoạt động
Theo Wikipedia (English ver.) và PAT Research thì quy trình phân tích dự báo gồm các bước sau:
- Define project: xác định dự án thông qua xác định mục tiêu kinh doanh, xác định phạm vi dự án, xác định tập dữ liệu nào sẽ khai thác, ví dụ công ty phải tự trả lời các câu hỏi như “chúng ta muốn dự báo cái gì?”, “mức độ chính xác mà mình mong muốn từ kết quả dự báo?”, “dữ liệu nào thật sự cần thiết để phân tích?” hay “chúng ta phải triển khai quy trình từng bước như thế nào?”
- Data collection: thu thập dữ liệu phục vụ phân tích dự báo.
- Data analysis: là quá trình kiểm tra, làm sạch và mô hình hóa dữ liệu với mục tiêu khám phá thông tin hữu ích, đi đến kết luận.
- Statistics: tìm kiếm các mối quan hệ giữa những đối tượng, các biến trong dữ liệu để làm cơ sở xây dựng các mô hình dự báo, sử dụng các phương pháp kiểm định, thống kê mô tả cho phép xác nhận các giả định, giả thuyết và kiểm tra chúng.
- Modeling: xây dựng các mô hình dự báo chính xác về các sự kiện tương lai bằng các áp dụng nhiều thuật toán Data mining, Machine learning, thống kê v.v cùng với các công cụ, phần mềm khác để đánh giá và chọn ra được mô hình tốt nhất.
- Deployment: triển khai mô hình, đưa ra các giải pháp để áp dụng những kết quả phân tích, kết quả dự báo vào quy trình ra quyết định hàng ngày và báo cáo cụ thể để xem xét mức độ thành công, hiệu suất của mô hình dự báo.
- Model monitoring: giám sát, đánh giá tính hiệu quả của mô hình trong thực tế và tiến hành điều chỉnh, cải thiện, đảm bảo mô hình đem lại kết quả như mong đợi của tổ chức.
Theo IBM, quy trình phân tích dự báo có thể gom gọn thành 5 bước sau:
- Xác định kết quả kinh doanh mong đợi: công ty cần xác định câu hỏi nào cần được hoặc có thể được trả lời bằng cách sử dụng phân tích dự báo. Nếu không được xác định mục đích chạy phân tích dự báo thì giống như ném phi tiêu trong bóng tối. Ngoài ra cũng cần xác định các đối tượng nguyên nhân (biến độc lập) rất có thể sẽ ảnh hưởng đến kết quả, đối tượng dự báo (biến phụ thuộc).
- Xác định dữ liệu cần thiết để đào tạo mô hình: phân tích dự báo yêu cầu dữ liệu từ nhiều nguồn, vì vậy các nhà phân tích phải xác định nguồn dữ liệu hiện tại. Nếu các nguồn dữ liệu hiện tại không đủ, họ phải có được dữ liệu từ các nguồn khác để đảm bảo rằng các mô hình có thể được đào tạo chính xác.
- Xác định các loại phân tích: xác định các kỹ thuật phân tích khác nhau và lựa chọn sao cho phù hợp tùy thuộc vào số lượng và loại dữ liệu có sẵn ví dụ như thống kê, Machine learning, Data mining, và những phương pháp tinh vi khác.
- Xác thực kết quả dự báo: dữ liệu đào tạo không thích hợp, phương pháp phân tích, thuật toán sử dụng không chính xác hay giả định đưa ra không hợp lý là một số nguyên nhân có thể dẫn đến dự báo sai. Các nhà khoa học dữ liệu cần hợp tác chặt chẽ với các nhà phân tích và các cấp quản lý để đảm bảo rằng các mô hình dự đoán có ý nghĩa, đem lại giá trị kinh doanh.
- Kiểm tra, cải thiện mô hình dự báo: các mô hình dự báo cần phải được điều chỉnh liên tục để cải thiện độ chính xác. Nếu một mô hình thất bại, các nhà phân tích phải xác định nguyên nhân tại sao và xây dựng, đào tạo lại mô hình.
Chắc đến đây các bạn đã nắm được cơ bản về tính chất và quy trình tổng quan của Predictive analytics. Chúng ta cùng đến phần cuối cùng và quan trọng không kém của bài viết đó chính là các phương pháp, kỹ thuật hay thuật toán dùng trong phân tích dự báo.
Kỹ thuật phân tích hay thuật toán được sử dụng trong phân tích dự báo
Theo SAS, thì có 3 kỹ thuật phân tích phổ biến nhất để xây dựng mô hình dự báo đó chính là:
- Decision Trees
Cây quyết định, là một dạng Classification model mà chúng tôi đề cập ở phía trên bài viết, và là một phương pháp có trong Data mining. Lý thuyết cây quyết định giúp chúng ta hiểu được con đường, hành trình ra quyết định của một ai đó ví dụ như dự báo hành vi mua hàng, dự báo khả năng rời dịch vụ của khách hàng. Cây quyết định được xây dựng trông giống như một cái cây thật. Cây quyết định có ba phần chính: nút gốc, là điểm bắt đầu, cùng với các nút phụ và nhánh lá. Các nút gốc và lá sẽ đặt câu hỏi. Các nhánh kết nối các nút gốc và lá, mô tả dòng chảy từ câu hỏi đến câu trả lời cuối cùng. Các câu trả lời có thể đơn giản như “có” và “không.”. Quá trình phân nhánh, hay quá trình ra quyết định ở từng bước đều được dựa trên những điều kiện, hệ số đo lường, tính toán nhất định. Phương pháp cây quyết định có ưu điểm trực quan, dễ nhìn, dễ giải thích, dễ nắm bắt.
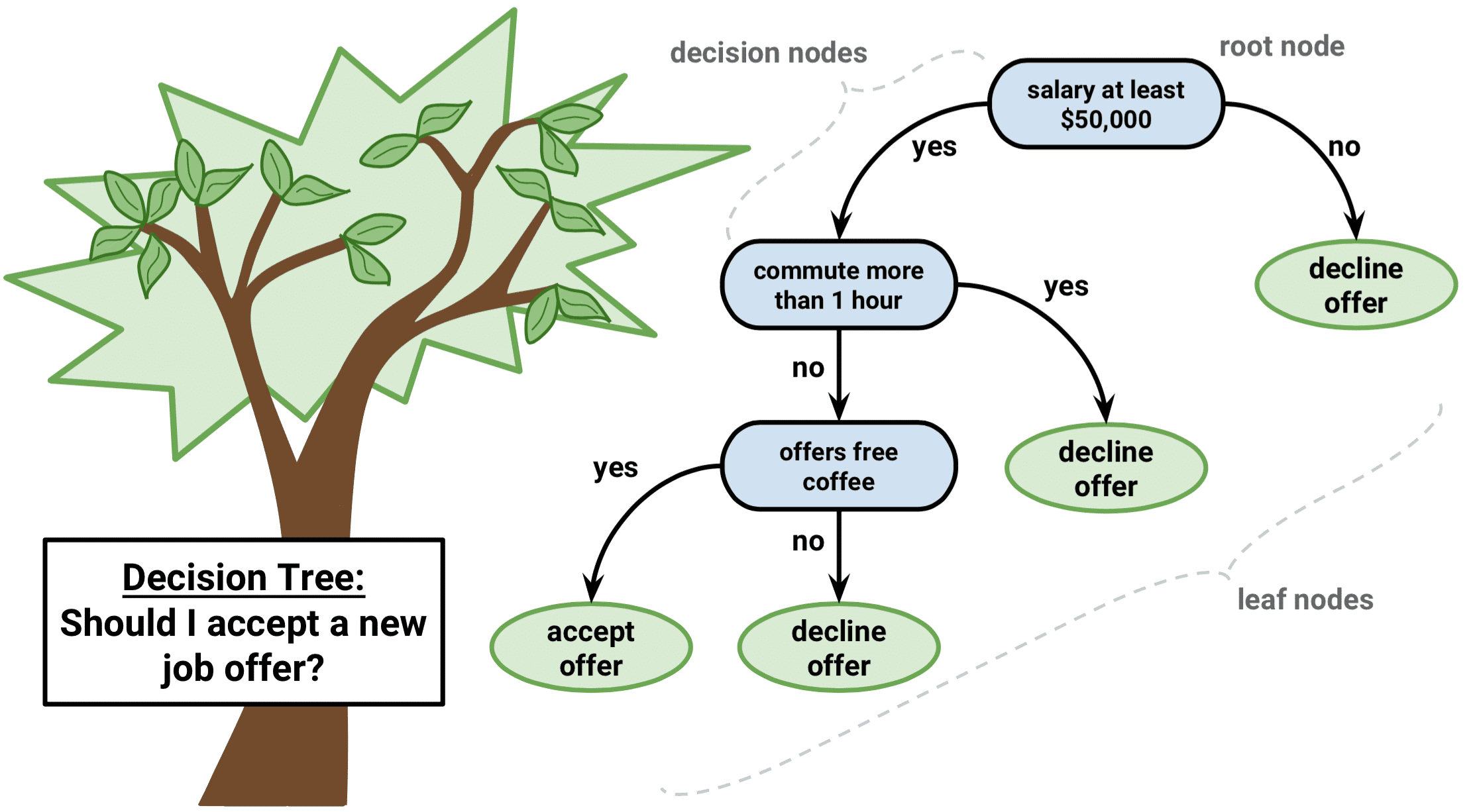
Ảnh: ví dụ về cây quyết định
- Regression
Phương pháp phân tích hồi quy gồm nhiều loại khác nhau như Linear regression, Non-linear regression, Logistic regression, Quantile regression,… Phân tích hồi quy là một phương pháp được sử dụng phổ biến nhất trong thống kê và Data mining để phân tích, xác định, tìm ra, định lượng các mối tương quan, mối quan hệ giữa các biến dữ liệu trong bộ dữ liệu; tính độc lập, hay phụ thuộc giữa các biến phân tích và biến mục tiêu nghiên cứu, giữa đối tượng dự báo và các đối tượng ảnh hưởng, giữa biến nguyên nhân, và biến kết quả dự báo. Các bạn có thể xem lại ví dụ ở đầu bài viết để hiểu thêm.
Các thuật toán hồi quy riêng biệt, đặc thù được áp dụng theo từng biến dữ liệu khác nhau. Ví dụ hồi quy tuyến tính (Linear hay multi linear regression) dùng cho phân tích biến liên tục (continuous variable) với một hay nhiều biến đầu vào là biến độc lập; hồi quy logistic (Logistic hay multi logistic regression) dùng cho dự báo kết quả của biến định tính (định danh hay biến thứ tự – categorical, hoặc biến thay phiên – binary). Regression được dùng để tìm kiếm thông tin về sự tác động của những yếu tố khác nhau đến mục tiêu nghiên cứu và các dự báo về đối tượng nghiên cứu trong tương lai. Regression được sử dụng nhiều trong lĩnh vực đầu tư, lĩnh vực tài chính và những lĩnh vực kinh doanh khác.
- Neural network
Mạng lưới thần kinh là các kỹ thuật tinh vi có khả năng mô hình hóa các mối quan hệ cực kỳ phức tạp. Neural network được sử dụng phổ biến trong lĩnh vực khoa học, công nghệ khác nhau nhờ vào tính năng ưu việt của nó. Sức mạnh của Neural network đến từ khả năng xử lý các mối quan hệ phi tuyến (là trường hợp khó xác định được mối quan hệ giữa các biến, đối tượng) trong bộ dữ liệu, thích hợp khi công ty thu thập và phân tích khối lượng lớn dữ liệu. Theo SAS, Neural network còn được sử dụng để kiểm chứng các phát hiện, kết quả từ các phương pháp hồi quy và cây quyết định, hay các kết quả dự báo. Neural network hoạt động dựa trên phương pháp Pattern Recognition của Machine learning và một số quy trình khác của AI (trí tuệ nhân tạo) để mô hình hóa các tham số. Neural network vận hành tốt cho trường hợp không có công thức toán học nào thể hiện sự liên quan giữa các biến đầu vào và đầu ra, trường hợp tầm quan trọng của dự báo lớn hơn việc giải thích các đối tượng dữ liệu hoặc trường hợp công ty có rất nhiều dữ liệu để đào tạo mô hình gọi là “training data set” (Neural network tự học các mối quan hệ giữa biến đầu vào và kết quả đầu ra thông qua việc huấn luyện). Neural network ban đầu được phát triển bởi các nhà nghiên cứu, những người đang cố gắng bắt chước hoạt động sinh lý, hoạt động thần kinh của não bộ con người.
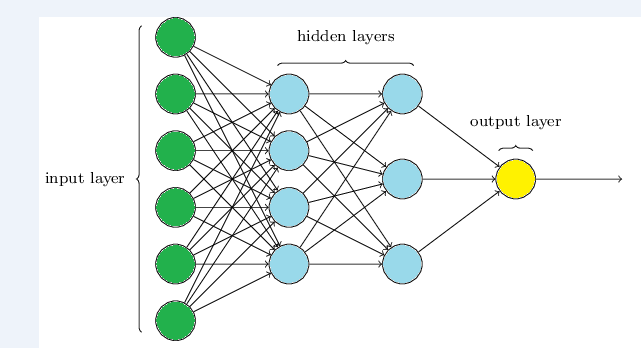
Hình minh họa mô hình Neural network Ngoài ra còn một số phương pháp phân tích dự báo khác như:
- Naïve Bayes (phương pháp Bayes)
- Gradient boosting
- k-Nearest Neighbor (kNN – thuật toán k láng giềng gần nhất)
- Partial least squares (phương pháp bình phương tối thiểu)
- Principle Component Analysis (PCA – phân tích thành phần chính)
- Support vector machine (SVM)
- Time series (phương pháp dãy số thời gian)
- Survial analysis (phân tích sống sót)
- Classification and regression trees (CART)
- Random Forest
- Genetic Algorithm (thuật toán di truyền)
- Clustering Techniques (kỹ thuật phân cụm)
- Association Rule Mining (khai phá sự kết hợp)
Các bạn có thể search thêm trên Goolge về từng phương pháp để tìm hiểu thêm nhé. Như vậy đến đây đã kết thúc phần 2 bài viết về phân tích dự báo. Mong các bạn tiếp tục ủng hộ các bài viết sắp tới của chúng tôi.
Nguồn tham khảo:
Tài liệu Havard Business Review “Predictive Analytics in Practice”
Tài liệu “Applied Predictive Analytics: Principles and Techniques for the Professional Data Analyst”
https://www.ibm.com/blogs/business-analytics/predictive-analytics-101-will-happen-next
/https://www.talend.com/resources/what-is-predictive-analytics/
https://www.sas.com/en_us/insights/analytics/predictive-analytics.html#dmhistory
https://en.wikipedia.org/wiki/Predictive_analytics
https://www.predictiveanalyticstoday.com/what-is-predictive-analytics/
villanovau.com/resources/bi/power-of-predictive-analytics/
https://www.mathworks.com/discovery/predictive-analytics.html#predictive-analytics-with-matlab
https://dzone.com/articles/introduction-to-predictive-analytics-and-predictiv
https://www.datamation.com/big-data/predictive-analytics-techniques.html
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.