
 English
EnglishỞ bài viết về Data preparation chúng ta đã cùng tìm hiểu Data preparation là gì, lợi ích, cũng như tầm quan trọng của chuẩn bị dữ liệu. Trong chủ đề về Data cleaning, một task trong Data preparation, phần 1 về Missing values, BigDataUni sẽ trình bày đến các bạn missing value là gì, các loại missing value quan trọng cần nắm. Trước khi đi vào nội dung trọng tâm, chúng ta cùng tìm hiểu một số tiêu chuẩn trong chất lượng dữ liệu, là các tiêu chí cần bám sát khi triển khai Data preparation nói chung và Data cleaning nói riêng

Điểm lại một số tiêu chuẩn trong chất lượng dữ liệu
Data preparation là bước không thể coi nhẹ và dĩ nhiên không thể bỏ qua ở bất kỳ quy trình phân tích và khai phá dữ liệu nào, nhưng để thực hiện bước này hiệu quả, một chuyên gia lĩnh vực dữ liệu cần phải xác định những tiêu chuẩn hay yêu cầu về chất lượng của dữ liệu và lấy đó làm cơ sở cho giai đoạn Data preparation. Dưới đây là một số tiêu chuẩn cần quan tâm:
- Tính chính xác của dữ liệu
Tính chính xác của dữ liệu là khả năng dữ liệu có thể miêu tả một sự vật hay hiện tượng nào đó trong thế giới thực, cũng có thể hiểu là mức độ chính xác của thông tin mà dữ liệu cung cấp. Dữ liệu ngoại lệ – là một yếu tố đánh giá tính chính xác của dữ liệu – xuất hiện có thể do nhiều nguyên nhân khác nhau nhưng có một vấn đề phải xác định chính là dữ liệu ngoại lệ có đúng với thực tế hay không.
- Tính đầy đủ của dữ liệu
Tính đầy đủ của dữ liệu trả lời cho câu hỏi “Dữ liệu phải thu thập theo nhu cầu đã đầy đủ chưa?”, hiểu đơn giản tức là tất cả các thành phần, yếu tố trong dữ liệu đều có mang giá trị– values – không có các trường hợp “missing values”, hay “null values”.
- Khối lượng dữ liệu
Khối lượng dữ liệu có đủ để tiến hành phân tích hay có đáp ứng được các yêu cầu phân tích hay khối lượng dữ liệu có đủ để thể hiện được các đặc tính của đối tượng nghiên cứu một cách tin cậy hay không? Kể cả lúc xây dựng mô hình, đối với dữ liệu training có đủ hay không? Chọn mẫu phân tích có đủ hay chưa? Có cần bổ sung thêm dữ liệu ở các nguồn khác hay không? Là một số câu hỏi để kiểm tra về yêu cầu của khối lượng dữ liệu.
- Tính nhất quán của dữ liệu
Tính nhất quán hiểu đơn giản là không có sự mâu thuẫn giữa cùng một đối tượng dữ liệu trong các tập dữ liệu khác nhau. Càng ít mâu thuẫn, càng ít sự khác biệt về thông tin, giá trị cung cấp bởi cùng một đối tượng dữ liệu giữa nhiều tập dữ liệu khác nhau thì tính nhất quán càng được gia tăng. Tính nhất quán còn xét về sự đồng nhất về thuộc tính dữ liệu, format của dữ liệu.
- Tính vẹn toàn của dữ liệu
Một tập dữ liệu không đảm bảo tính vẹn toàn được coi là tập dữ liệu thiếu thông tin, thiếu giá trị tại các ô quan sát, dữ liệu bên trong không thể sử dụng vì bị sai lệch, bị sửa đổi, dữ liệu bị trùng lặp, bị lỗi,… cần kiểm tra cấu trúc dữ liệu, đảm bảo cấu trúc dữ liệu không thay đổi so với cấu trúc được chuẩn hóa trước đó, và không phát sinh lỗi khi chuyển đổi, tích hợp, hay tổng hợp từ nhiều tập dữ liệu khác nhau.
- Tính hợp lệ của dữ liệu
Tính hợp lệ của dữ liệu liên quan đến cách dữ liệu được thu thập, chuyển đổi (Data transformation). Dữ liệu được coi là hợp lệ, có hiệu lực sử dụng nếu nó đạt yêu cầu về định dạng, về loại dữ liệu, về biến, về giá trị, thông tin dữ liệu cung cấp nằm trong phạm vi phù hợp, dữ liệu có phù hợp để áp dụng các thuật toán phân tích hay xây dựng model hay không?
- Tính độc nhất
Tính độc nhất của dữ liệu liên quan đến việc dữ liệu không có bị trùng lặp, dữ liệu được xác định và nhập vào các cơ sở dữ liệu, tập dữ liệu hay được ghi lại một lần duy nhất. Nói đơn giản dữ liệu có bị “duplicate” hay không?
- Tính liên quan và tính kịp thời
Tính liên quan có nghĩa là dữ liệu thu thập phải liên quan đến mục tiêu kinh doanh, mục tiêu nghiên cứu của tổ chức, có hữu ích cho các chiến lược, sáng kiến trong tương lai. Tính kịp thời, đúng lúc của dữ liệu liên quan đến việc dữ liệu có cung cấp, mô tả thông tin là những sự kiện xảy ra gần đây hay không, nói cách khác dữ liệu về một sự kiện, về một hiện tượng, đối tượng nghiên cứu nào đó phải được thu thập càng sớm càng tốt khi nó vừa xuất hiện, vì dữ liệu qua thời gian sẽ không còn chính xác, giảm giá trị, không còn phù hợp để sử dụng trong các bối cảnh hiện tại hay tương lai
Các bạn có thể thấy chỉ mới một vài tiêu chuẩn về chất lượng dữ liệu cũng đủ biết công việc Data preparation hay Data preprocessing phức tạp và tốn nhiều thời gian, công sức như thế nào. Về định dạng, tính chất của loại dữ liệu, biến dữ liệu, khối lượng dữ liệu,… thông qua các phương pháp chọn mẫu, tổng hợp, chuyển đổi dữ liệu,… những chuyên gia phân tích có thể thực hiện, xử lý dựa trên kinh nghiệm, kiến thức chuyên môn của mình sao cho dữ liệu sẽ ở trạng thái tốt nhất trước khi phân tích. Nhưng có một yếu tố khách quan mà những chuyên gia không thể tự mình thay đổi và điều chỉnh, chỉ biết làm thế nào để mô hình phân tích không bị ảnh hưởng bởi chính yếu tố này, đó là thông tin dữ liệu cung cấp, cụ thể là dữ liệu bị missing value/ null value thiếu giá trị, không đủ giá trị, giá trị dữ liệu bị khuyết,…, và dữ liệu có giá trị ngoại lệ, thông tin dữ liệu cung cấp có dấu hiệu bất thường, không phù hợp với thực tế được thể hiện rõ hay phải qua xác định, được gọi là outlier.
Missing values và outlier có thể ảnh hưởng, làm sai lệch kết quả phân tích, cần loại bỏ, hay có thể giữ lại (có những thuật toán phân tích không bị ảnh hưởng bởi missing value, nên missing value ở những trường hợp này có thể không cần chú ý đến) hay phải xử lý chúng như thế nào mới tốt nhất là một trong các câu hỏi “đau đầu” nhất trong Data preparation. Ở phần 1, phần 2 Data cleaning, BigDataUni sẽ trình bày trước về missing values
Data cleaning là gì?
Data cleaning hay làm sạch dữ liệu là quy trình chuẩn bị dữ liệu trước khi phân tích thông qua xử lý hay loại bỏ những dữ liệu không chính xác, không đầy đủ, không phù hợp về định dạng, bị trùng lắp, không có giá trị, không đủ thông tin, không liên quan,…- những dữ liệu có thể ảnh hưởng đến kết quả phân tích sau cùng. Mục đích chính của Data cleaning hướng đến không chỉ đơn thuần là loại bỏ dữ liệu, tạo không gian để thêm vào dữ liệu mới thay thế, mà phải tìm cách tăng tối đa độ chính xác của dữ liệu trong khi cố gắng hạn chế tối đa việc loại bỏ dữ liệu. Ngoài ra, Data cleaning xây dựng một bộ dữ liệu đầy đủ tiêu chuẩn, lấy đó làm cơ sở tham chiếu cho các dự án nghiên cứu dữ liệu hỗ trợ chiến lược, hoạt động kinh doanh, tạo điều kiện để các công cụ phân tích được ứng dụng hiệu quả, tài sản dữ liệu được tiếp cận và truy vấn dễ dàng, mang lại nhiều thông tin hữu ích, và giá trị.
Data cleaning có rất nhiều phương pháp khác nhau từ cơ bản đến nâng cao, chuyên sâu phụ thuộc và mục tiêu phân tích, tính chất ban đầu bộ dữ liệu, các yêu cầu liên quan, các quy trình xử lý dữ liệu trước đó. Data cleaning có thể được thực hiện thủ công hay có thể được tự động hóa nhờ vào các phần mềm, công cụ phân tích dữ liệu.
Missing values và cách thức xử lý
Dữ liệu bị missing là dữ liệu không chứa giá trị, dữ liệu không có sẵn hay không cung cấp thông tin và có thể có giá trị phân tích. Chúng ta giả sử dữ liệu đầu vào của một mô hình thuật toán là một bảng dữ liệu, mỗi dòng là một đối tượng quan sát, được mô tả bởi những giá trị ở các cột còn được gọi là các biến hay các thuộc tính (attribute), bao gồm những biến độc lập và một biến phụ thuộc – biến mục tiêu. Ví dụ trong bảng dữ liệu dự báo rủi ro tín dụng dưới đây, các bạn có thể thấy tại một số ô không có thông tin, giá trị cụ thể, ví dụ tại đối tượng thứ 4 (ID = 4) cột độ tuổi không có giá trị “#N/A” – “Not available” thường thấy trong excel, ở đối tượng thứ 6, cột độc thân không có thông tin, bị thay vào là dấu “?”, ở đối tượng thứ 7, cột Sở hữu BĐS, ô bị để trống, ở đối tượng thứ 3 thì ghi là “Không có thông tin”. Đặc biệt tại cột thu nhập chúng ta có 2 ô giá trị 0 tại đối tượng 12 và 8, đối tượng 5 lại là “#N/A”, như vậy câu hỏi đặt ra là 0 tức không có thông tin hay 0 cho thấy thu nhập của các đối tượng này là không có? Đi tìm hiểu nguyên nhân dẫn đến missing value là một nhiệm vụ không hề đơn giản, hơn nữa qua bảng dữ liệu các bạn có thể thấy chất lượng dữ liệu kém khi quy ước thể hiện missing values không thống nhất, không có tính nhất quán chỗ thì #N/A, chỗ “?”, chỗ để trống,…Nếu không xử lý thì chắc chắn 100% dữ liệu dưới đây không thể phân tích. Với ví dụ này chắc các bạn cũng hiểu được missing values là vấn đề gì, và như thế nào.
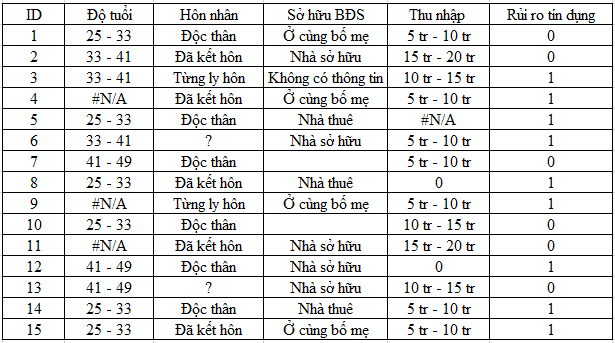
Nguyên nhân dẫn đến missing values thì khó có thể kể hết, đến từ nhiều phía, từ người cung cấp thông tin ví dụ là chính khách hàng, những người được khảo sát,…, từ phía người thu thập thông tin ví dụ nhân viên nhập liệu nhập sai dữ liệu, nhân viên khảo sát ghi nhận không đủ thông tin,… từ phía hệ thống ví dụ hệ thống dữ liệu bị lỗi, tương tự như các công cụ, phần mềm gặp vấn đề,…Đối với mục đích phân tích dữ liệu, và thường sử dụng nguồn dữ liệu lớn thì chắc không có ai bỏ công sức để đi tìm lại dữ liệu bị mất nếu chúng chỉ chiếm tỷ lệ nhỏ. Nhưng ở góc độ đánh giá kết quả phân tích thì dù tỷ lệ nhỏ thì vẫn có ảnh hưởng nhất định.
Điều mà các chuyên gia phân tích thường quan tâm khi họ phải xử lý missing values đó chính là loại missing values, hay xác định cơ chế missing values – data missingness mechanism. Mục đích của việc này là xem xét áp dụng cách thức xử lý missing values phù hợp cho từng loại missing values, từ các phương pháp loại bỏ (deleting/ removing) cho đến thêm vào giá trị mới (imputing).
Data missingness mechanism là các giả định về nguyên nhân tại sao dữ liệu bị missing, bao gồm có 3 loại chính:
- Missing Completely At Random (MCAR)
MCAR xuất hiện khi các missing value được phân phối ngẫu nhiên trên tất cả các quan sát, tức là mỗi quan sát đều có khả năng bị missing value ngẫu nhiên như nhau. Cơ chế, nguyên nhân dẫn đến missing value hay chính các missing value không liên quan đến các giá trị ở bất kỳ biến nào trong tập dữ liệu, missing hay không missing, và nói cách khác không liên quan đến các biến, ngay cả biến được xác định hay chưa được xác định trong tập dữ liệu, không liên quan đến các thông tin có hay không có trong tập dữ liệu. Tập dữ liệu có missing value là MCAR thì không có yếu tố nào khiến một đối tượng quan sát có khả năng bị missing value hơn các đối tượng còn lại.
Ví dụ trong một nghiên cứu định lượng ở lĩnh vực kinh tế, xã hội, MCAR có thể được xác định bằng cách chia tập dữ liệu về các câu trả lời khảo sát thành hai phần dữ liệu có và không có missing values, sau đó sử dụng phương pháp kiểm định t-test trong thống kê để tìm ra sự khác biệt về trung bình trong thu nhập, tuổi tác, giới tính và các biến quan trọng khác giữa 2 phần dữ liệu nếu hai phần dữ liệu không khác biệt đáng kể ở bất kỳ biến nào trong mô hình, bao gồm cả biến phụ thuộc, thì trường hợp này gọi là MCAR. Một phương pháp khác để xác định MCAR có tên gọi là Little’s MCAR test được đặt tên bởi chính chuyên gia tìm ra nó, Little, Roderick J A tác giả của cuốn sách nổi tiếng “Statistical Analysis with Missing Data”.
Trong phần mềm SPSS, Little’s MCAR test được triển khai sử dụng kiểm định Chi-square – chi bình với H0: missing values là loại MCAR, nếu giá trị p-value < 0.05, tức loại bỏ H0, missing values không phải MCAR và ngược lại. Ở phần 2 tới chúng tôi sẽ giải thích kỹ hơn và đi vào ví dụ cụ thể.
Nếu dữ liệu bị thiếu là MCAR trong một tập dữ liệu đủ lớn, các quan sát có giá trị bị thiếu có thể được loại bỏ (theo phương pháp Listwise hoặc Pairwise deletion) mà có thể không làm sai lệch các kết quả phân tích. Nguyên nhân dẫn đến MCAR có thể ví dụ như khách hàng vô tình nhập thiếu một thông tin nào đó, hay nhân viên nhập liệu vô tình quên nhập dữ liệu tại một quan sát bất kỳ.
Đối với missing value dạng MCAR, thì loại bỏ là phương pháp sử dụng chính để xử lý, điều này có thể ví von, nếu chúng ta gặp MCAR, thì chúng ta đã “gặp may” khi không cần bỏ nhiều thời gian, công sức “bận tâm” đến nó, chỉ cần sử dụng dữ liệu có giá trị cụ thể để phân tích, nhưng việc bắt gặp MCAR được coi là hiếm khi, không thường xuyên. Hơn nữa, phương pháp loại bỏ nếu gặp trường hợp tỷ lệ missing value quá lớn thì có thể khiến bộ dữ liệu không đạt yêu cầu về lượng, đơn giản, dữ liệu sẽ không đủ để phân tích hoặc bất chấp đưa vô phân tích sẽ mang lại kết quả không chính xác.
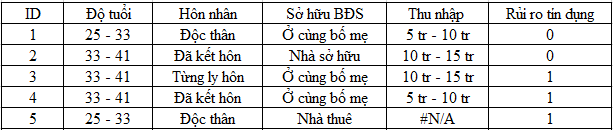
Các bạn nhìn thử ví dụ trên, ở cột thu nhập có 1 ô bị missing, giả sử qua bảng trên chúng ta thử kết luận 50% có thu nhập từ 5 – 10 triệu và 50 % có thu nhập từ 10 – 15 triệu, tức là một người có thể tỷ lệ 50% có thu nhập trên 10 triệu và 50% dưới 10 triệu. Khi chúng ta kết luận như vậy, một đối tượng có hay không có missing value sẽ không liên quan đến những giá trị còn lại, thì trường hợp này là MCAR. Ví dụ đơn giản cho các bạn hình dung được vấn đề, nhưng trong thực tế, ở mỗi cột có thể có nhiều missing value, và một đối tượng có thể thiếu dữ liệu tại nhiều cột, nên xác định MCAR theo cách này là không khả thi, không phù hợp với thực tế.
Các đối tượng có missing value nếu là MCAR, ngẫu nhiên hoàn toàn, thì chúng ta không thể dự báo được, tức không có cơ sở xác định đối tượng nào là có missing value bằng những phương pháp tính toán mà phải thông qua xác định bằng thủ công, bằng “mắt thường”, hay nhờ vào tính năng mô tả dữ liệu, khám phá dữ liệu của các phần mềm phân tích dữ liệu
- Missing At Random (MAR)
Điểm khác biệt chính giữa MCAR và MAR chính là ở MAR, missing value có thể không ngẫu nhiên ở tất cả các quan sát, các đối tượng trong tập dữ liệu, nghĩa là mỗi quan sát có thể khác nhau về khả năng bị missing nhưng nếu xét trong các tập dữ liệu nhỏ, các mẫu nhỏ lẻ (sub-sample data) thì có thể missing value là ngẫu nhiên hoàn toàn. Ví dụ, thành phố Hồ Chí Minh thu thập số liệu về mức lương cơ bản trung bình năm của người dân tất cả các phường thuộc quận Bình Thạnh nhưng các số liệu bị missing ngẫu nhiên ở các phường, thì đây là trường hợp MCAR. Nhưng nếu chỉ có một phường cụ thể có dữ liệu missing ngẫu nhiên ở một số hộ gia đình, thì trường hợp này là MAR.
Một cách giải thích quan trọng hơn về MAR: cơ chế, nguyên nhân dẫn đến missing value hay chính các missing value trong 1 biến bất kỳ có một mối liên hệ có hệ thống đối với những dữ liệu có giá trị cụ thể (observed data) hay với những biến xuất hiện trong tập dữ liệu, hay với những thông tin được đề cập trong tập dữ liệu, và không có liên hệ với chính biến có missing values đó.
Yếu tố khác biệt khác giữa MAR và MCAR chính là chúng ta có thể dự báo các missing value ở những đối tương quan sát dựa trên những dữ liệu có giá trị cụ thể còn lại trong tập dữ liệu.
Quay lại với ví dụ này, các bạn có thể dự báo đự missing value tại biến thu nhập ở đối tượng thứ 5 không, dựa vào các suy luận về độ tuổi, tình trạng hôn nhân, sở hữu BĐS, hay cả biến mục tiêu là rủi ro tín dụng không? Nếu được thì trường hợp missing value ở đây là MAR. Giả sử chúng ta thấy đối tượng 1 có độ tuổi từ 25-33 và độc thân thì thu nhập 5 – 10 tr, trong khi phần lớn từ 33 – 41 tuổi có thu nhập từ 10 – 15 tr, thì có thể dự báo đối tượng 5 thu nhập có thể từ 5 – 10 tr.
Lưu ý, mặc dù chúng ta có thể dự báo được giá trị bị missing nhưng không thể xác định được mối liên hệ giữa cơ chế missing value và các giá trị cụ thể trong tập dữ liệu.
Đối với MAR, các phương pháp xử lý sẽ phức tạp hơn nhiều bao gồm các cách thức “impute” giá trị mới thay thế missing value và cả những kỹ thuật phân tích chuyên sâu áp dụng riêng cho MAR. Tuyệt đối không loại bỏ missing value trong trường hợp MAR vì nó có thể khiến chúng ta đánh mất những thông tin hữu ích.
Những giả định về MAR được xem là an toàn hơn MCAR, vì đơn giản chúng ta có thể sẽ không bỏ qua những thông tin giá trị cho dù chúng bị missing, chúng ta vẫn có cách tìm lại được với tỷ lệ chính xác nhất định thông qua dự báo, hay ước lượng. Tránh nhầm lẫn: missing value được giả định là MCAR thì không được giả định là MAR. MCAR và MAR vẫn là 2 cơ chế khác biệt nhau hoàn toàn.
Vì MAR cho thấy có mối liên hệ giữa missing values với những thành phần khác, nên việc xác định MAR là phức tạp không hề đơn giản. Ví dụ ở trên chỉ giúp các bạn hình dung MAR là gì chứ trong thực tế tập dữ liệu thường rất lớn và rất nhiều biến thì xác định theo cách trên hoàn toàn không khả thi.
Có ý kiến cho rằng có thể sử dụng Little MCAR test để xác định, nếu là MCAR, thì không thể là MAR và ngược lại. Nhưng có vấn đề khác là ngoài MCAR và MAR chúng ta còn dạng thứ 3 mà chúng tôi sắp trình bày dưới đây chính là MNAR (Missing not at random), chúng ta phải phân biệt tiếp MAR và MNAR.
Một hướng tiếp cận khả thi khác chính là chúng ta có thể lập một biến giả (biếm dummy) từ các biến có missing value, ví dụ biến cân nặng có missing value, chúng ta sẽ lập biến dummy đặt tên Can_nang_MV có 2 giá trị 0: không có missing value, tức đối tượng này có giá trị tại cột thu nhập và 1: có missing value, tức đối tượng này không có giá trị tại cột thu nhập. Ví dụ thường thì phụ nữ sẽ không ít cung cấp thông tin về cân nặng so với đàn ông, thì tỷ lệ missing value sẽ cao hơn đàn ông, lúc này có mối liên hệ giữa Can_nang_MV và giới tính.
Chúng ta sẽ sử dụng phương pháp kiểm định t để xem các biến có liên hệ với nhau hay không. Nếu có thì có thể xem là MAR.
- Missing not at random (MNAR)
MNAR hay còn gọi là non – ignorable (không thể phớt lờ) là trường hợp nguyên nhân missing value phụ thuộc hoàn toàn vào chính giá trị bị missing, phụ thuộc vào chính biến bị missing, nói cách khác biến bị missing chính là nguyên nhân dẫn đến các giá trị bị mất, và thường không phụ thuộc vào các giá trị khác ở các biến trong tập dữ liệu (observed data), không thể được dự báo dựa trên chính các dữ liệu còn lại, có thể có mối liên hệ với những yếu tố, biến, nguyên nhân dẫn đến missing không đề cập trong dữ liệu. Giải thích đơn giản cho các bạn hiểu, MNAR xảy ra có thể ví dụ do người cung cấp thông tin, khách hàng, người làm khảo sát từ chối tiết lộ những thông tin cá nhân, nhạy cảm, hay không mong muốn.
Lý do gọi đây non – ignorable vì chúng ta cần phải có thông tin chính xác do không có cơ sở để dự báo missing value. MCAR và MAR còn được gọi là ignorable, do chúng ta có thể sử dụng những kỹ thuật, phương pháp để dự báo hay tối thiểu hạn chế tác động của missing value đến kết quả phân tích.
Vì đây là MNAR, dữ liệu bị missing hoàn toàn không phải ngẫu nhiên, và có chủ đích do đó không thể sử dụng các phương pháp xử lý missing value thông thường như MAR, MCAR vì chúng không phù hợp, mà còn phải dựa vào kinh nghiệm của người làm phân tích, kinh nghiệm của người làm nghiên cứu, đặc biệt là phải xây dựng những mô hình, giải pháp xử lý đặc thù đã được kiểm chứng cho các trường hợp này. Ở bài viết phần 2 chúng ta sẽ chỉ tập trung vào các phương pháp áp dụng cho MAR, và MCAR.
Như vậy đến đây kết thúc phần 1 bài viết về missing value, ở phần 2 chúng tôi sẽ giải thích lại lần nữa để các bạn phân biệt rõ 3 khái niệm trên, cũng như giới thiệu cách xác định MCAR với ví dụ cụ thể.
TÀI LIỆU THAM KHẢO
https://blogs.oracle.com/datascience/3-methods-to-handle-missing-data
https://towardsdatascience.com/how-to-handle-missing-data-8646b18db0d4
www.theanalysisfactor.com/missing-data-mechanism
www.displayr.com/different-types-of-missing-data/
“Little’s Test of Missing Completely at Random” – Cheng Li Northwestern University
“Missing values analysis & data imputation” G. David Garson & Statistical Associates Publishing
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.