
 English
EnglishTrở lại với chủ đề bài viết về Data mining, ở 2 phần trước BigDataUni đã giới thiệu dến các bạn khái niệm, tầm quan trọng, lợi ích, thách thức và đặc biệt là ứng dụng của Data mining trong nhiều lĩnh vực khác nhau. Phần cuối của chủ đề Data mining lần này, BigDataUni sẽ phân tích về các quy trình, kỹ thuật và thuật toán của Data mining, hay tìm hiểu làm cách Data mining khai thác giá trị, những thông tin hữu ích từ dữ liệu?
Dành cho các bạn chưa xem các phần trước:
Tổng quan về Data mining (Phần 1): Data mining là gì?
Tổng quan về Data mining (Phần 2): Ứng dụng Data mining trong các lĩnh vực

Đầu tiên, BigDataUni sẽ nói về quy trình của Data mining, yếu tố cốt lõi để đánh giá và quyết định sự hiệu quả, thành công của các dự án Data mining. Các bước trong quy trình sắp được phân tích dưới đây có thể áp dụng trong tất cả hệ thống Data mining ở mọi tổ chức thuộc nhiều lĩnh vực khác nhau.
Quá trình của Data mining cũng gần giống với các quá trình khai thác dữ liệu Big Data cũng như Data Analytics, bắt đầu từ việc xác định mục đích, mục tiêu khai thác (trong lĩnh vực kinh tế gọi là mục tiêu kinh doanh) , thu nhập dữ liệu cần thiết (ở đây BigDataUni sẽ không nói đến các vấn đề về kỹ thuật công nghệ, phần mềm thu thập), xử lý dữ liệu ban đầu như tìm hiểu tổng quan, tổng hợp dữ liệu, làm sạch dữ liệu, chuyển đổi dữ liệu, chuẩn bị dữ liệu, tiếp đến là giai đoạn phân tích, mô hình hóa, và sau cùng đánh giá kết quả thu được, áp dụng chúng vào thực tế thông qua việc đề xuất và đưa ra các chiến lược, cải cách mới.
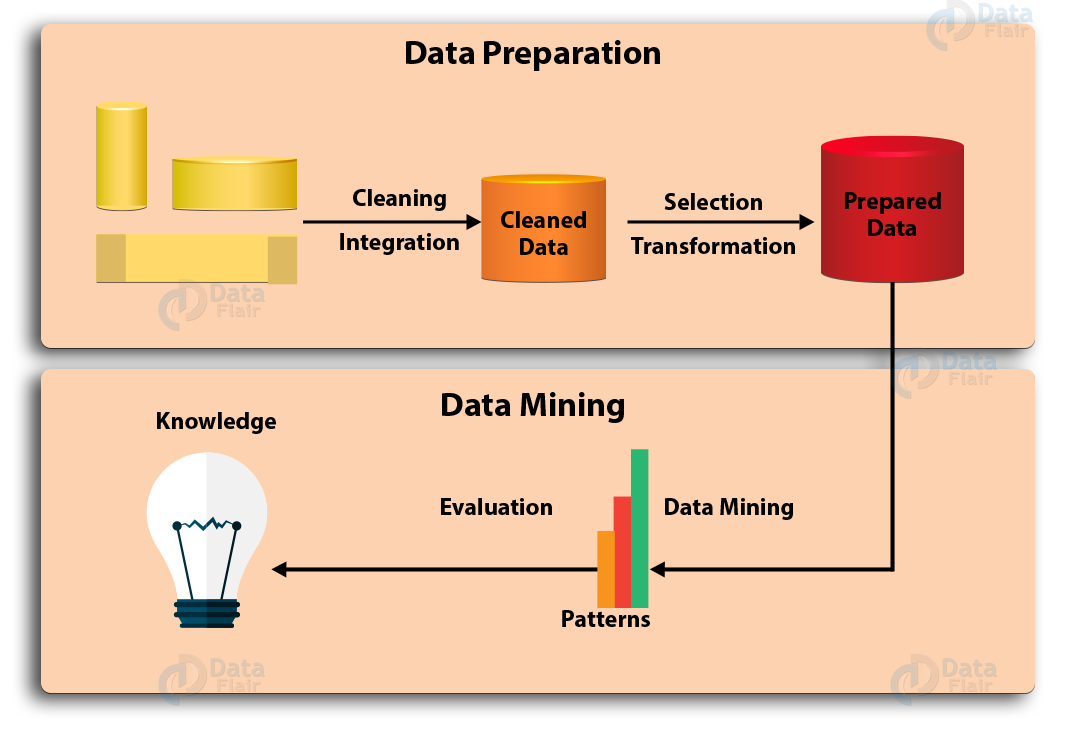
Quy trình Data mining (nguồn hình Data-Flair)
Nếu chia theo 2 giai đoạn là giai đoạn chuẩn bị dữ liệu (Data preparation) và giai đoạn phân tích, khai thác dữ liệu (Data mining), thì quá trình gồm những bước sau: (quá trình dưới đây còn được gọi là quá trình khai phá tri thức trong cơ sở dữ liệu KDD – Knowledge Discovery in Database)
- Data cleaning
Data cleaning thuộc giai đoạn Data preparation còn gọi là “làm sạch” dữ liệu, là bước đầu tiên mà mỗi nhà phân tích phải thực hiện sau khi thu thập được dữ liệu. Mục đích của bước này là loại bỏ các dữ liệu “nhiễu”, dữ liệu không liên quan, không đầy đủ thông tin – được xem là những vấn đề luôn hiện hữu trong mọi bộ dữ liệu. Ví dụ công việc cụ thể trong Data cleaning là xử lý các “missing value”, hay “missing data”. Giả sử dữ liệu khách hàng A cung cấp đầy đủ thông tin về tuổi, tên, giới tính, nghề nghiệp, lịch sử ngày, thời gian giao dịch trong tháng,.. nhưng không có thông tin về sản phẩm đã mua, số tiền cụ thể đã chi do không có giá trị tại ô quan sát. Suy ra dữ liệu khách hàng A không phù hợp để phân tích, phải được tách riêng để điều tra nguyên nhân tại sao lại có “missing value”. Kết quả của bước Data cleaning là bộ dữ liệu được làm sạch, không còn tác nhân gây ảnh hưởng đến kết quả phân tích ở các bước sau.
2. Data integration
Data integration hay còn gọi là tổng hợp, tích hợp dữ liệu. Dữ liệu mà mỗi tổ chức, công ty phải thu thập đến từ nhiều nguồn khác, không đồng nhất, và có nhiều định dạng khác nhau. Quá trình Data integration mục tiêu là lưu trữ dữ liệu từ nhiều nguồn khác nhau trong một hệ cơ sở dữ liệu, một nguồn dữ liệu nhất định, dưới dạng các bảng tính, tệp dữ liệu,..để hỗ trợ quản lý và phân tích trong tương lai. Ví dụ chúng ta có 3 file excel về dữ liệu khách hàng trong quý 1 năm 2019 gồm tháng 1 đến tháng 3 tương ứng mỗi file excel, vậy khi phân tích chúng ta phải tích hợp cả 3 vào 1 file excel duy nhất sao cho thuận tiện (nếu dùng phần mềm phân tích như IBM SPSS Modeler thì có sẵn tính năng tích hợp). Đây là quá trình phức tạp, và không đơn giản. Các chuyên gia thường sử dụng “metadata” hay còn gọi là “siêu dữ liệu” nhằm giảm bớt sai sót trong quá trình tích hợp. Metadata là loại dữ liệu dùng để mô tả các dữ liệu khác, như mô tả tính chất, loại biến dữ liệu, thông tin mà dữ liệu đó cung cấp,…
Ví dụ dữ liệu về 1 học sinh trong 1 lớp học như sau: Học sinh A: Tên “Nguyễn Văn A” ; Tuổi “15”; Giới tính “Nam”; Quê quán “Tp.HCM”; Điểm TBHK “8.5” Các thông tin trong ngoặc kép là dữ liệu thu thập thông thường. Còn Tên, Tuổi, Giới tính, Quê Quán, Điểm TBHK (trong các bảng tính được gọi là tên của các cột dữ liệu) chính là metadata vì nó miêu tả tính chất dữ liệu trong dấu ngoặc kép. Trong quá trình Data integration, metadata sẽ tổng hợp các thông tin chung về dữ liệu và dùng làm cơ sở kiểm soát đặc điểm của các dữ liệu thu thập, lấy ví dụ ở trên:
| Thông tin thu thập | Ngày thu thập | Loại dữ liệu | Nguồn thu thập |
| Tên | 7/9/2018 | Nominal | Hồ sơ học sinh |
| Tuổi | 7/9/2018 | Continuous | Hồ sơ học sinh |
| Giới tính | 7/9/2018 | Nominal | Hồ sơ học sinh |
| Quê Quán | 7/9/2018 | Nominal | Hồ sơ học sinh |
| Điểm TBHK | 12/1/2019 | Continuous | Bảng điểm tổng kết |
| Xếp loại | 12/1/2019 | Ordinal | Bảng điểm tổng kết |
Một trong những vấn đề khác phải đối mặt là sự dư thừa của dữ liệu do các dữ liệu sau khi thu thập, lưu trữ tại các bảng tính có thể bị trùng lặp, để hạn chế tối đa vấn đề này, các nhà phân tích phải đi đến bước tiếp theo là Data selection.
- Data selection
Data selection là việc chọn ra những dữ liệu liên quan đến giai đoạn phân tích, hay chọn ra những dữ liệu có thể có giá trị phân tích, được lấy từ cơ sở dữ liệu. Các dự án data mining thường thu thập và phân tích một khối lượng lớn dữ liệu, hơn nữa do quá trình tích hợp dữ liệu ở bước trên cũng khiến cho khối lượng dữ liệu phải phân tích là rất nhiều, sẽ ảnh hướng đến tốc độ hệ thống Data mining và kết quả thu được sau cùng có thể không chính xác. Ngoài việc loại bỏ các dữ liệu trùng lặp, dữ liệu không liên quan, quy trình Data selection còn có nhiệm vụ chọn ra những dữ liệu có tiềm năng (nhiều nhà phân tích còn gọi đây là giai đoạn chọn mẫu) đem lại thông tin hữu ích chuẩn bị cho các giai đoạn tiếp theo. Kết quả của Data selection sẽ ảnh hưởng đến tất cả các bước tiếp theo của quá trình Data mining.
4. Data transformation
Data transformation là quá trình chuyển đổi dữ liệu, hợp nhất dữ liệu theo các loại biến, định dạng khác nhau để phù hợp và dễ dàng cho việc phân tích, bao gồm các công việc về chuẩn hóa dữ liệu, khái quát và tổng hợp dữ liệu theo biến, định dạng phù hợp. Ví dụ dữ liệu thực trạng khách hàng có đang sử dụng dịch vụ hay không: có 2 trường hợp “Còn sử dụng dịch vụ”, “Đã rời dịch vụ” để thuận tiện cho quá trình xây dựng model, thuật toán phân tích, các chuyên gia thường chuyển đổi thành biến Flag (hay trong thống kê gọi là biến thay phiên) tức gán chuyển đổi “Còn sử dụng dịch vụ” thành giá trị 1, “Đã rời dịch vụ” thành giá trị 0; hoặc 1, hoặc chuyển đổi theo True – T và False – F. Ví dụ cột dữ liệu về “điểm trung bình học kỳ” của 3000 ngàn học sinh trong 1 trường THPT là biến số, biến định lượng, vậy nếu muốn đánh giá học lực của các học sinh chúng ta phải tạo cột dữ liệu mới với biến thứ bậc hoặc biến định danh có giá trị “Giỏi”, “Khá”, “Trung bình”, “Kém”, “Yếu” được đặt ra bằng cách phân theo điều kiện của mức điểm trung bình.
Ví dụ khác, phân loại khách hàng theo mức chi tiêu cho các sản phẩm của công ty, chúng ta cũng tạo cột dữ liệu mới “Loại khách hàng” dựa trên điều kiện phân loại từ cột dữ liệu “Chi tiêu sản phẩm dịch vụ” chứa thông tin về số tiền khách hàng bỏ ra khi mua sản phẩm. Ví dụ điều chỉnh dữ liệu thời gian đồng nhất theo ngày/tháng/năm để tránh nhầm lẫn, làm tròn các số thập phân, rút gọn số hàng triệu, trục triệu để thuận tiện cho việc phân tích Sau khi dữ liệu được thu thập, làm sạch, tổng hợp, chọn lọc và chuyển đổi phù hợp thì đã sẵn sàng để đưa vào phân tích và khai thác.
5. Data mining
Quá trình khai thác sẽ bao gồm các công việc xây dựng thuật toán, phương pháp, các model phân tích khác nhau như Classification, Association, Clustering, Regression,… mục đích phát hiện, trích xuất các thông tin hữu ích, giá trị tiềm năng từ những mẫu dữ liệu, quy luật và xu hướng dữ liệu.
6. Pattern evaluation
Đánh giá mẫu dữ liệu, hay còn gọi là đánh giá thông tin thu được từ quá trình khai thác, xác định mức độ chính xác, khả năng đem lại giá trị thực sự, để trả lời cho câu hỏi “ mẫu dữ liệu/ thông tin thu được có cần quan tâm để phát triển chiến lược, triển khai vào thực tế không?” Ví dụ cụ thể của bước này là xây dựng các giả thuyết và tiến hành kiểm định, dựa trên mức độ tin cậy và kết quả kiểm định để xem xét. Nếu kết quả phân tích không hợp lý, có sai sót, cần quay kiểm tra lại các bước ở trên, còn nếu kết quả phân tích đã hợp lý, độ tin cậy cao thì tiếp tục bước sau cùng dưới đây.
7. Knowledge representation
Bước sau cùng của quy trình chính là trình bày kết quả thu được đến các cấp quản lý, nhà điều hành để họ hiểu về ý nghĩa, mục đích khai thác dữ liệu và nên áp dụng những kiến thức từ Data vào thực tế như thế nào. Công việc chính của knowledge representation là thể hiện kết quả bằng các công cụ trực quan hóa, sử dụng đồ thị, bảng, biểu đồ để dễ dàng diễn giải kết quả đến người xem.
Bên trên là các bước tổng quát của một quá trình Data mining điển hình. Tiếp theo, BigDataUni giới thiệu đến các bạn một hệ quy trình các bước Data mining được coi là quy chuẩn, tiêu chuẩn quốc tế, được áp dụng trong tất cả các ngành và lĩnh vực khác nhau. Đó là quy trình CRISP – DM (Cross-Industry Standard Process for Data Mining).
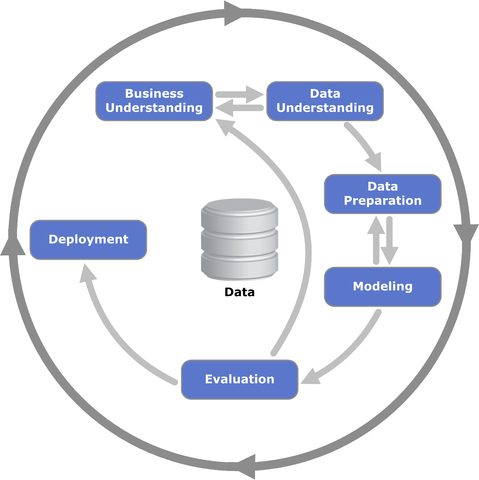
Quy trình CRISP-DM (nguồn hình es.wikipedia.org)
{kind=link}
Mỗi công ty, tổ chức thuộc bất kỳ ngành nghề, lĩnh vực riêng biệt, hoặc từng bộ phận, phòng ban chức năng trong các công ty, trước đây triển khai các hoạt động Data mining một cách không hiệu quả, mơ hồ, áp dụng những quy trình, phương pháp không hợp lý, đặc biệt thường không có một hệ thống Data mining chuẩn hóa, luôn thay đổi liên tục rất tốn kém và mất thời gian.
Nhận thấy được vấn đề, các tập đoàn công nghệ, công ty chuyên về tư vấn giải pháp phân tích như IBM, NCR, Daimler AG, Teradata đã nghiên cứu và phát triển CRISP-DM. Hiện nay, phần mềm hỗ trợ khai thác Data mining hoàn chỉnh và hiệu quả nhất theo mô hình CRISP-DM chính là IBM SPSS Modeler.
CRISP – DM gồm 6 giai đoạn (bước) chính như sau:
- Business understanding / Research understanding phase
Đầu tiên, chúng ta phải xác định nhu cầu của việc triển khai Data mining là gì, cụ thể là mục tiêu trong lĩnh vực kinh doanh hay bất kỳ hoạt động nghiên cứu nào ở các lĩnh vực khác và tìm hiểu liệu Data mining sẽ cung cấp thông tin cho chúng ta như thế nào, mục đích khi áp dụng Data mining là gì? Khi đã xác định được chính xác nhu cầu, và mục đích, chúng ta sẽ có thể quyết định được nguồn lực xây dựng hệ thống Data mining như lựa chọn phần mềm, công cụ Data mining, sau đó phát triển các kế hoạch, dự án Data mining cho từng chiến lược, giai đoạn cụ thể, tiếp theo là thiết lập các tiêu chí đánh giá hệ thống Data mining dựa trên những mục đích, nhu cầu đã xác định trước. Ngoài ra, còn phải tìm hiểu các điều kiện bên trong và bên ngoài tổ chức có thể tác động đến dự án Data mining như các cơ hội, lợi thế và các hạn chế, thách thức ví dụ như rà soát lại hoạt động thu thập và phân tích dữ liệu hiện tại của tổ chức hay thực trạng nguồn dữ liệu tổ chức đang khai thác. Đối chiếu mục đích Data mining, mục tiêu kinh doanh, nghiên cứu với từng cơ hội, thách thức để thiết lập lại sao cho hợp lý và khả thi hơn. Kết thúc giai đoạn này, chúng ta sẽ có một kế hoạch hoàn chỉnh vừa đạt được mục đích Data mining vừa đạt được mục tiêu kinh doanh và nghiên cứu.
2. Data understanding phase
Những bước đầu tiên trong giai đoạn Data understanding là xác định các loại dữ liệu, các nguồn dữ liệu khác nhau và tiến hành thu thập, tổng hợp, tích hợp dữ liệu, sử dụng metadata như đã nói ở quy trình Data mining đầu tiên (ví dụ ở tệp dữ liệu A, cột đầu tiên để là “Mã số khách hàng”, tệp dữ liệu B lại để tên”Mã khách hàng”, khi tích hợp lại phải đổi tên cột bên tệp B theo tệp A). Tiếp theo dùng các phương pháp phân tích để mô tả ban đầu và làm quen với bộ dữ liệu, xây dựng các báo cáo, truy vấn dữ liệu, lập các bảng, biểu đồ hay còn gọi là các công cụ trực quan hóa để khám phá các thuộc tính của dữ liệu, đảm bảo dữ liệu sẽ mang lại giá trị phân tích đối chiếu với các mục tiêu ở giai đoạn Business understanding, và tìm hiểu tổng quan các thông tin hữu ích tiềm ẩn có thể đạt được thông qua bộ dữ liệu.
Sau cùng là đánh giá chất lượng của bộ dữ liệu bằng cách trả lời những câu hỏi như: “những dữ liệu cần phân tích đã thu thập đủ chưa?”, “Có missing value tại các cột dữ liệu hay không?” Nếu bộ dữ liệu thực sự chưa đạt yêu cầu, chưa đầy đủ, hay dữ liệu không liên quan đến mục tiêu kinh doanh, mục đích nghiên cứu thì chúng ta phải quay lại giai đoạn 1 Business understanding để tìm hiểu kỹ hơn, xác định lại các vấn đề đã gặp. Đây là giai đoạn theo các chuyên gia là tốn nhiều thời gian nhất trong quy trình CRISP-DM, thành quả của giai đoạn này sẽ giúp chúng ta có một bộ dữ liệu hoàn chỉnh cuối cùng để tiến hành xây dựng các mô hình hay còn gọi là model tập trung phân tích và khai thác thông tin.
3. Data preparation phase
Data preparation gồm các bước tương tự như Data cleaning, Data integration, Data selection, Data transformation như đã nói ở quá trình Data mining đầu tiên nên ở đây chúng tôi sẽ không nhắc lại ví dụ. Select: chọn lọc ra các dữ liệu cần phân tích ví dụ như chọn mẫu, chọn các biến, các cột, dòng dữ liệu có thể liên quan với mục tiêu, cần thiết để phân tích nghiên cứu, sự cân đối của bộ dữ liệu, tránh trường hợp khối lượng dữ liệu quá lớn đưa vào model sẽ làm chậm tốc độ phân tích, ảnh hưởng đến toàn quá trình, đặc biệt loại ra các dữ liệu dư thừa, trùng lặp. Clean: làm sạch bộ dữ liệu. Dữ liệu sau khi chọn cần được kiểm tra để tìm ra và loại bỏ dữ liệu “bị nhiễu” , dữ liệu không hợp lý,… đặc biệt là xử lý missing value, thêm giá trị vào các dữ liệu chứa missing value (filling in missing value) hay thay đổi missing value bằng các biến giả định phù hợp để chuẩn bị đưa vào model phân tích. Transform, construct: chuyển đổi, cấu trúc bộ dữ liệu.
Điển hình là điều chỉnh cột dữ liệu theo biến mới, theo điều kiện phân tích, thay đổi giá trị trong từng cột dữ liệu sao cho phù hợp hơn, hay xây dựng các cột dữ liệu mới với loại biến, giá trị mới. Integrate, format: tích hợp, và điều chỉnh bộ dữ liệu. Quá trình tích hợp cũng cần xây dựng các điều kiện phù hợp để hạn chế sai sót, tránh việc bỏ sót các dữ liệu quý giá. Điều chỉnh dữ liệu nhằm tạo ra bộ dữ liệu gọn hơn, dễ quan sát hơn, tránh bị nhầm lẫn.
- Modelling
Sau khi có một bộ dữ liệu hoàn chỉnh và đầy đủ, chúng ta sẽ tiến hành chọn ra, thiết lập các model dựa trên các thuật toán phù hợp với mục đích phân tích và nghiên cứu. Các thuật toán kỹ thuật trong Data mining điển hình như Association Rules, Clustering, Classification, Outlier Detection, Prediction,..sẽ được chúng tôi trình bày tổng quát sau khi giới thiệu xong CRISP-DM. Các model sẽ tiến hành phân tích dữ liệu và cung cấp các kết quả là những thông tin hữu ích có giá trị. Để đánh giá mức độ chính xác của kết quả thì khi áp dụng model các chuyên gia khuyến khích kiểm tra, thử nghiệm model bằng các bộ dữ liệu tương đương. Kết quả nhận được sau khi chạy các model cần được xem xét cẩn thận, nếu kết quả bất hợp lý, hay thông tin cung cấp không phù hợp với thực tế, hay bị sai lệch quá nhiều, thì chúng ta phải quay lại bước Data preparation để kiểm tra dữ liệu chọn ra đã đúng chưa?, các dữ liệu nhiễu đã bị loại bỏ chưa?, dữ liệu đã được chuyển đổi, điều chỉnh hợp lý chưa? Nếu kết quả đã được kiểm chứng, thì đến giai đoạn tiếp theo đánh giá, đo lường chi tiết dựa trên mục đích kinh doanh, nghiên cứu.
5. Evaluation
Kiểm tra, đánh giá kết quả có được từ model với mục tiêu nghiên cứu và kinh doanh. Đối chiếu kết quả với những mục tiêu đề ra ban đầu trong bước Business Understanding/ Research Understanding, để xem liệu kết quả, thông tin từ phân tích có hữu ích, có góp phần đề xuất các chiến lược kinh doanh, các ý tưởng nghiên cứu khác khả thi hay không? Đây cũng là cơ sở đánh giá sau cùng sự hiệu quả của các bước còn lại trong quy trình CRISP-DM và toàn hệ thống Data mining.
6. Deployment
Bước cuối cùng là triển khai kết quả thành các chiến lược, giải pháp cụ thể, trình bày kết quả bằng các công cụ trực quan hóa như các đồ thị, biểu đồ, các báo cáo,.. để các nhà quản lý có thể nắm được, hiểu rõ, và trao đổi dễ dàng với các chuyên gia phân tích.
Ở giai đoạn này, các nhà quản lý và chuyên gia ngoài việc bàn luận về chiến lược hoạt động còn bàn luận về các cách thức cải thiện, phát triển hệ thống Data mining trong tương lai đặc biệt là thiết lập các model, quy trình Data mining chuẩn hóa đã được kiểm chứng để phục vụ cho những lần nghiên cứu, phân tích sắp tới.
Tiếp theo là một phần quan trọng không kém mà BigDataUni muốn gửi đến các bạn trong phần 3 bài viết lần này, đó chính là các phương pháp phân tích sử dụng phổ biến trong Data mining. Lưu ý, chúng tôi sẽ mô tả lợi ích, ứng dụng của các phương pháp một cách tổng quát nhất và không đi vào giới thiệu các thuật toán, công thức toán học sử dụng trong các phương pháp được trình bày dưới đây vì tính chất phức tạp của chúng, mong các bạn thông cảm, nếu có cơ hội BigDataUni sẽ viết một bài riêng về các thuật toán sử dụng trong Data mining. 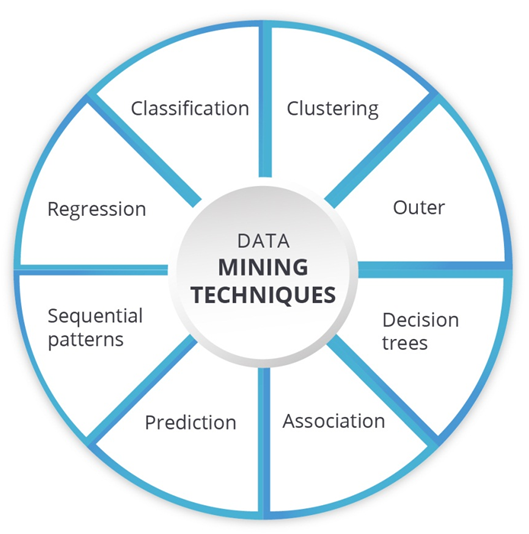
Xét về phương pháp phân tích, thì Data mining có những phương pháp chính sau:
- Classification analysis
Phương pháp phân tích phân loại giúp chúng ta phân loại các dữ liệu khác nhau, đối tượng nghiên cứu khác nhau theo các lớp (class) khác nhau dựa trên các yếu tố, tính chất tương đồng, và thông tin thể hiện sự liên quan giữa các dữ liệu với nhau. Ngoài việc sử dụng những thuật toán, công thức toán học đặc thù thì việc phân tích dữ liệu cần đối chiếu với metadata (đã giới thiệu ở bước Data Integration tại quy trình Data mining đầu tiên). Classification analysis và Clustering analysis (phân tích phân cụm mà chúng tôi sắp nói đến ở tiếp theo sau đây) có điểm chung là phân loại dữ liệu theo các lớp (class), các cụm (cluster) đều dựa trên những điểm tương đồng, sự liên quan, giống nhau giữa các dữ liệu. Còn điểm khác là: với Classification chúng ta phải sử dụng thuật toán để tìm ra các điểm tương đồng, để phân loại dữ liệu; còn Clustering thì chúng ta thường biết trước các đặc điểm cần tập trung để phân loại dữ liệu. Ví dụ các chuyên gia sử dụng Classification analysis để tìm ra tính chất của các email spam, email chứa mã độc, virus, và tiến hành phân loại chúng để chuẩn bị các giải pháp cảnh báo người dùng, và loại bỏ.
2. Clustering analysis
Clustering analysis là phân tích phân cụm, hỗ trợ khám phá ra các nhóm dữ liệu, các phân cụm (cluster); phân nhóm các đối tượng nghiên cứu vào những cluster khác nhau. Các đối tượng trong cùng 1 cluster đều chứa các điểm chung, điểm tương đồng nhau. Phương pháp này giúp chúng ta nắm được tính chất, đặc điểm của đối tượng nghiên cứu trong bộ dữ liệu một cách rõ ràng hơn. Clustering analysis được các chuyên gia sử dụng để phân loại khách hàng, phân khúc khách hàng theo những đặc điểm về khách hàng đã xác định từ trước ví dụ sử dụng Clustering để phân khúc khách hàng dựa theo điểm tín dụng (credit scores) trong ngành tài chính ngân hàng, hay phân khúc khách hàng trong ngành viễn thông, ngành bán lẻ dựa trên mô hình RFM (Recency-Frequency-Monetary Value) để xác định nhóm khách hàng chi tiêu nhiều, đến nhóm khách hàng chi tiêu thấp, khách hàng sử dụng dịch vụ thường xuyên đến khách hàng không sử dụng dịch vụ,… để đánh giá tổng quát CLV (customer life time value).
3. Association Rules analysis
Phân tích luật kết hợp là quá trình phân tích các biến dữ liệu, đối tượng nghiên cứu để tìm ra các khả năng kết hợp, luật kết hợp giữa chúng. Để mô tả cách thức, và thuật toán sử dụng trong Association Rules thì khá phức tạp nên chúng tôi chỉ giải thích đơn giản thông qua ví dụ cụ thể. Association Rules được sử dụng thường xuyên trong ngành bán lẻ và ngành thương mại điện tử, đặc biệt được dùng để xây dựng hệ thống khuyến nghị – Recommendation Engine, và các chiến lược marketing hướng cá nhân hóa (personalization), các chiến lược bán hàng cross-selling, hay up-selling,…nếu các bạn có theo dõi các bài viết trước về Data mining hay về chủ đề E-commerce thì BigDataUni đã từng đề cập. Ví dụ khách hàng mua các sản phẩm sữa, phô mai thì khả năng khách hàng mua sản phẩm ly cốc với tỷ lệ là bao nhiêu %, độ tin cậy là bao nhiêu? Tương tự khách hàng mua Laptop thì có khả năng mua headphone, mouse hay không? Các luật kết hợp được khai pháp sẽ giúp ích rất nhiều cho các chiến lược marketing và bán hàng.
4. Anomaly/ Outlier Detection analysis
Phân tích để phát hiện các dữ liệu bất thường, dữ liệu ngoại lệ và qua đó tìm ra các thông tin hữu ích về đối tượng nghiên cứu bằng cách giải thích và tìm hiểu nguyên nhân vì sao xuất hiện các dữ liệu bất thường ấy. Phương pháp này yêu cầu khả năng bao quát, phân tích, quan sát toàn bộ dữ liệu. Các dữ liệu ngoại lệ ví dụ như dữ liệu có giá trị cao thấp bất thường về lượng, các dữ liệu bất hợp lý, sai lệch quá mức cho phép,.., hay các dữ liệu “null” hay “missing value” cũng được coi là dữ liệu ngoại lệ. Khai phá dữ liệu ngoại lệ cũng giống như khai phá các quy luật bất thường, không có quy tắc của đối tượng nghiên cứu trong bộ dữ liệu. Phương pháp được sử dụng để ngăn chặn tội phạm công nghệ thông tin như tin tặc, hacker khi phát hiện sự thâm nhập hệ thống bất thường, hay phát hiện hành vi gian lận, tội phạm tài chính khi thấy được sự bất thường trong thói quen chi tiêu, giao dịch của khách hàng để đưa ra các thông báo kịp thời, hay phương pháp còn được dùng để dự báo xu hướng tiêu dùng khách hàng tại các thời điểm trong năm. Ngoài ra, Outlier detection giúp các chuyên gia loại bỏ dữ liệu nhiễu, dữ liệu sai lệch, dữ liệu ngoại lệ ngay trong chính model Data mining mục đích thu được kết quả phân tích sau cùng một cách chính xác, hợp lý nhất.
5. Prediction analysis
Phương pháp phân tích dự báo không chỉ được sử dụng trong Data mining mà còn được sử dụng trong hầu hết các dự án Big Data, Business Intelligence, Machine Learning và AI. Phân tích dữ liệu lịch sử, quá khứ để đưa ra các dự báo trong tương lai, và có thể sử dụng kết hợp các phương pháp đã được nói ở trên để dự báo xu hướng, hành vi của đối tượng nghiên cứu thông qua việc tìm ra các quy luật ẩn chứa bên trong bộ dữ liệu. Để hiểu thêm về Predictive analysis, mời các bạn theo dõi thêm bài viết “Lợi ích Predictive Analytics trong thương mại điện tử” của BigDataUni. Ví dụ phân tích dự báo khả năng rời dịch vụ của khách hàng (churn risk), phân tích dự báo xu hướng mua hàng của khách hàng vào các ngày lễ hay đặc biệt là phân tích các yếu tố có thể tác động đến khả năng mua hàng của khách hàng, các yếu tố ảnh hưởng đến doanh thu của công ty để đưa ra các dự báo trong tương lai, thậm chí trong thực tại.
- Sequential/Frequent patterns analysis
Phương pháp phân tích này nhằm tìm ra các mẫu dữ liệu (data pattern), các dữ liệu giống nhau, có sự tương đồng (similarity), xuất hiện thường xuyên (frequency) trong bộ dữ liệu và có quy luật nhất định. Ví dụ thông qua dữ liệu lịch sử giao dịch của khách hàng chúng ta sẽ tìm ra:
- Frequent Item Set: tức giỏ hàng khách hàng sẽ quan tâm, các sản phẩm liên quan khách hàng sẽ mua, hay các sản phẩm kết hợp được mua cùng lúc. Ví dụ bánh mì và sữa thường được mua cùng lúc. Điểm này gần giống với Association Rules đã nói ở trên, khác biệt ở chỗ phương pháp này chỉ tìm ra chính xác các luật kết hợp thông thường chứ không phát hiện được các luật kết hợp bất thường khác như Association Rule ví dụ thông qua Association Rule chúng ta phát hiện thêm khách hàng có thể mua sữa cùng với mua ly, cốc, tỷ lệ là 70%.
- Frequent Subsequence: quy luật mua hàng thông thường ví dụ khách hàng mua Laptop có mua kèm theo mouse, headphone hay không.
- Regression analysis
Phân tích hồi quy được sử dụng trong thống kê và Data mining để phân tích, xác định, tìm ra các mối tương quan, mối quan hệ giữa các biến dữ liệu trong bộ dữ liệu; tính độc lập, hay phụ thuộc giữa các biến phân tích và biến mục tiêu nghiên cứu. Các thuật toán hồi quy riêng biệt, đặc thù được áp dụng theo từng biến dữ liệu khác nhau. Ví dụ hồi quy tuyến tính (linear regression) dùng cho phân tích biến liên tục (continuous) với một hay nhiều biến đầu vào là biến độc lập; hồi quy logistic (logistic regression) dùng cho biến định tính (định danh hay biến thứ tự – categorical). Regression analysis được dùng để tìm kiếm thông tin về sự tác động của những yếu tố khác nhau đến mục tiêu nghiên cứu và các dự báo về đối tượng nghiên cứu trong tương lai.
8. Decision trees technique
Đây là phương pháp quan trọng nhất, được sử dụng nhiều nhất trong tất cả các trường hợp phân tích, khai thác dữ liệu bằng Data mining. Phương pháp cây quyết định có ưu điểm trực quan, dễ nhìn, dễ giải thích, dễ nắm bắt. Mỗi nhánh trên cây quyết định được xem là câu trả lời cho một câu hỏi bất kỳ, và để đưa ra quyết định sau cùng thì một nhà quản lý có hàng loạt rất nhiều câu hỏi khác nhau cần được giải đáp. Nếu xét trong bộ dữ liệu thì chúng ta có thể hiểu đơn giản, gốc cây là biến mục tiêu cần nghiên cứu, mỗi nhánh cây là một biến dữ liệu bất kỳ, các nhánh cây thể hiện mối quan hệ giữa các biến dữ liệu với nhau và với biến mục tiêu, quá trình phân nhánh dựa trên những điều kiện, hệ số đo lường, tính toán nhất định. Cách thức để xây dựng một cây quyết định, cũng như thuật toán, công thức toán học áp dụng khá phức tạp nên BigDataUni sẽ không đề cập trong bài viết này mà chỉ giới thiệu ví dụ đơn giản cho các bạn nắm được tổng quát
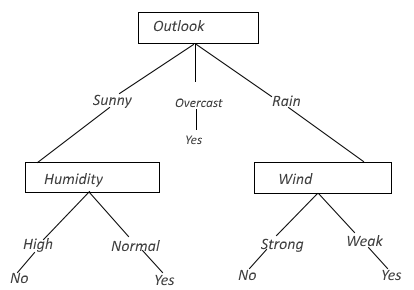
Ví dụ để tổ chức một trận bóng đá chúng ta phải xét đến yếu tố thời tiết, quang cảnh (outlook) nơi diễn ra trận bóng. Nếu thời tiết dự báo nhiều mây, thoáng mát (overcast) thì chắc chắn sẽ tổ chức trận đấu. Nếu thời tiết dự báo có nắng, thì ta xét tiếp độ ẩm (humidity) vì nó ảnh hưởng đến sức khỏe và thể lực cầu thử, nếu độ ẩm cao thì không thể tổ chức, còn bình thường thì sẽ tổ chức. Tiếp tục, nếu thời tiết dự báo có mưa, thì ta phải xét đến yếu tố gió vì sẽ ảnh hưởng đến tốc độ di chuyển của cầu thủ và bóng, nếu gió yếu thì sẽ tổ chức trận đấu, ngược lại thì không.
Để có thể tạo một cây quyết định hoàn chỉnh thì chúng ta phải thu thập và phân tích tất dữ liệu liên quan, xây dựng các điều kiện, hệ số đo lường, tính toán thích hợp để phân nhánh chính xác.
Tóm lại các phương pháp sử dụng trong Data mining được phân tích ở trên mục đích là khai phá những thông tin hữu ích từ bộ dữ liệu như:+ Cách phân loại dữ liệu, mô tả dữ liệu theo các lớp dữ liệu + Khai phá các mẫu dữ liệu thường xuyên xuất hiện, các dữ liệu tương đồng nhau + Khai phá luật kết hợp + Khai phá mối tương quan+ Khai phá nhóm dữ liệu
Đến đây là kết thúc bài viết cuối cùng của chủ đề Data mining, mong thông qua các bài viết về Data mining các bạn sẽ hiểu được tổng quát về tầm quan trọng, lợi ích, ứng dụng, quy trình và phương pháp chính của Data mining. Mời các bạn theo dõi những bài viết sắp tới của BigDataUni về những chủ đề mới lạ, thú vị hơn trong lĩnh vực Big Data và Data Analytics.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm lâu năm trong lĩnh vực Big Data và đặc biệt là Data mining sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”. Nếu các bạn có bất kỳ thắc mắc nào xin đừng ngần ngại liên hệ chúng tôi tại mục liên hệ hoặc comment trực tiếp dưới bài viết.