
 English
EnglishNếu các bạn đã theo dõi các bài viết của Big Data Uni thì chắc cũng đã nắm được tổng quan về Big Data bao gồm khái niệm, lợi ích và ứng dụng của nó trong nhiều lĩnh vực khác nhau. Trong chủ đề bài viết lần này và sắp tới, chúng tôi sẽ không đề cập về những giá trị mà Big Data đem lại mà đi vào trọng tâm một trong những công cụ, quá trình quan trọng nhất đối với mỗi dự án Big Data đó chính là Data mining (hay còn gọi là khai phá dữ liệu).
Ở phần 1 bài viết, chúng tôi sẽ giới thiệu tổng quan về Data mining, khái niệm, tầm quan trọng, lợi ích, thách thức của Data mining – khai phá dữ liệu.
Theo báo cáo của MarketsAndMarkets – một công ty tư vấn và nghiên cứu thị trường toàn cầu – về thị trường Data mining (thị trường Data mining phân theo công cụ, dịch vụ, phân theo từng chức năng kinh doanh như marketing – tiếp thị, quản lý chuỗi cung ứng và logistics, bộ phận kinh doanh, sản xuất, phân theo ngành công nghiệp, quy mô tổ chức, địa lý) dự báo sẽ tăng từ 591.2 triệu USD năm 2018 đến 1.039 triệu USD trong năm 2023.
Đây là minh chứng cho thấy xu hướng tiếp cận Data mining phục vụ cho việc khai thác giá trị từ dữ liệu ở các công ty (không xét đến ngành nghề, lĩnh vực) trên toàn cầu ngày càng mạnh mẽ.

Nguồn hình: towardsdatascience.com
Data mining là gì?
Trước tiên chúng ta tách “Data mining” thành 2 chữ “Data”, và “mining” để phân tích. “Data” đơn giản là nguồn dữ liệu mà mỗi công ty, tổ chức thu thập được đa dạng, từ các nguồn khác nhau. “Mining” trong tiếng Việt có nghĩa là đào đất, đào mỏ để tìm vàng, dầu mỏ, những thứ có giá trị. Nhưng khi “data” và “mining” ghép lại với nhau, chúng ta không thể nói đào dữ liệu để tìm giá trị mà phải nói là “khai phá dữ liệu”, (vì đào bới với khai phá đều có nghĩa là đi tìm những thứ chúng ta chưa từng biết đến). “Data mining” chính là quá trình đi sâu vào bộ dữ liệu để phân tích và tìm kiếm các chi tiết, giá trị ẩn bên trong từng dữ liệu, hay cụ thể là muốn xác định, muốn biết xem dữ liệu cung cấp thông tin gì, thông tin đó có ích không thì chúng ta phải thực hành “Data mining”.
Theo Data-Flair, một trang web cung cấp các khóa học, các kiến thức về Big Data và Data Science, định nghĩa Data mining như sau: “Data mining – khai phá dữ liệu, là một tập hợp, một hệ thống các phương pháp tính toán, thuật toán được áp dụng cho các cơ sở dữ liệu lớn và phức tạp mục đích loại bỏ các chi tiết ngẫu nhiên, chi tiết ngoại lệ, khám phá các mẫu, mô hình, quy luật tiềm ẩn, các thông tin có giá trị trong bộ dữ liệu. Data mining là thành quả công nghệ tiên tiến ngày nay, là quá trình khám phá các kiến thức vô giá bằng cách phân tích khối lượng lớn dữ liệu đồng thời lưu trữ chúng ở nhiều cơ sở dữ liệu khác nhau”
Cũng theo Data- Flair, Data mining là một trong những lợi thế các công ty trong ngành sản xuất, kinh doanh, marketing nếu họ biết cách ứng dụng hợp lý để tăng hiệu quả hoạt động. Do đó, nhu cầu xây dựng một hệ thống Data mining tiêu chuẩn ngày càng cao. Các quy trình, mô hình Data mining phải có độ tin cậy cao và tạo điều kiện để các nhà kinh doanh – những người có thể không nắm rõ kiến thức chuyên môn về khoa học dữ liệu – có thể sử dụng được. Khai thác dữ liệu chính là là trích xuất thông tin từ các bộ dữ liệu khổng lồ. Nói cách khác, khai thác dữ liệu là quy trình khai thác, tiếp thu kiến thức từ dữ liệu. Chính vì vậy Data mining được ứng dụng vào rất nhiều lĩnh vực khác nhau, Big Data Uni sẽ giới thiệu chi tiết ở các bài viết sau.
Còn theo SAS – công ty chuyên cung cấp các phần mềm, giải pháp lưu trữ và phân tích dữ liệu toàn cầu – định nghĩa Data mining cụ thể hơn về ứng dụng của nó: “Data mining là quá trình tìm kiếm các chi tiết bất thường (anomalies), các mẫu, mô hình, quy luật của dữ liệu và mối tương quan giữa các tập dữ liệu lớn để dự đoán kết quả, thiết lập các dự báo. Bằng cách áp dụng một loạt các kỹ thuật khác nhau, thông tin có được từ Data mining sẽ hỗ trợ tăng doanh thu, cắt giảm chi phí, cải thiện mối quan hệ khách hàng, giảm rủi ro,..”
Tương tự như trang Investopedia nói về Data mining: “Data mining là một quá trình được các công ty sử dụng để biến dữ liệu thô thành những thông tin hữu ích. Bằng cách sử dụng các phần mềm chuyên dụng để tìm kiếm các quy luật, các mẫu, thông tin có giá trị, mối tương quan tiềm ẩn trong khối lượng lớn dữ liệu, công ty có thể tìm hiểu thêm về khách hàng của mình để phát triển các chiến lược tiếp thị hiệu quả hơn, tăng doanh số và giảm chi phí.”
Tóm lại, theo Big Data Uni thì Data mining có thể được hiểu một cách tổng quát như sau:
- Data mining là quá trình khám phá và phân tích khối lượng lớn dữ liệu để tìm ra các mẫu dữ liệu và quy tắc có ý nghĩa. Data mining là một trong những lĩnh vực nghiên cứu khoa học dữ liệu, khai thác và sử dụng các dữ kiện, thông tin có giá trị từ dữ liệu để phục vụ đưa ra dự báo, quyết định trong tương lai.
Một điểm quan khác từ các định nghĩa trên, các bạn chú ý sẽ thấy mỗi định nghĩa đều đề cập đến khám phá “các mẫu” dữ liệu, vậy “các mẫu” được nhắc đến là gì?
Các mẫu trong dữ liệu tiếng Anh gọi là “ Data patterns”, là một phần của thống kê mô tả tức là một mẫu từ tổng thể, một mẫu dữ liệu phân tích đang thể hiện điều gì? Cụ thể Data patterns có thể xác định được thông qua các đồ đị đo lường mức độ tập trung, phân tán, biến động, và các giá trị ngoại lệ, bất thường của dữ liệu, chi tiết hơn là việc tính toán các số liệu miêu tả chung về “mẫu dữ liệu” hay “tập dữ liệu” ví dụ số trung bình cộng, mốt, trung vị,..(độ tập trung); phân vị, độ trải giữa, phương sai, độ lệch chuẩn,..(độ phân tán, biến động của dữ liệu) và xác định cụ thể các dữ liệu không liên quan (giá trị ngoại lệ).
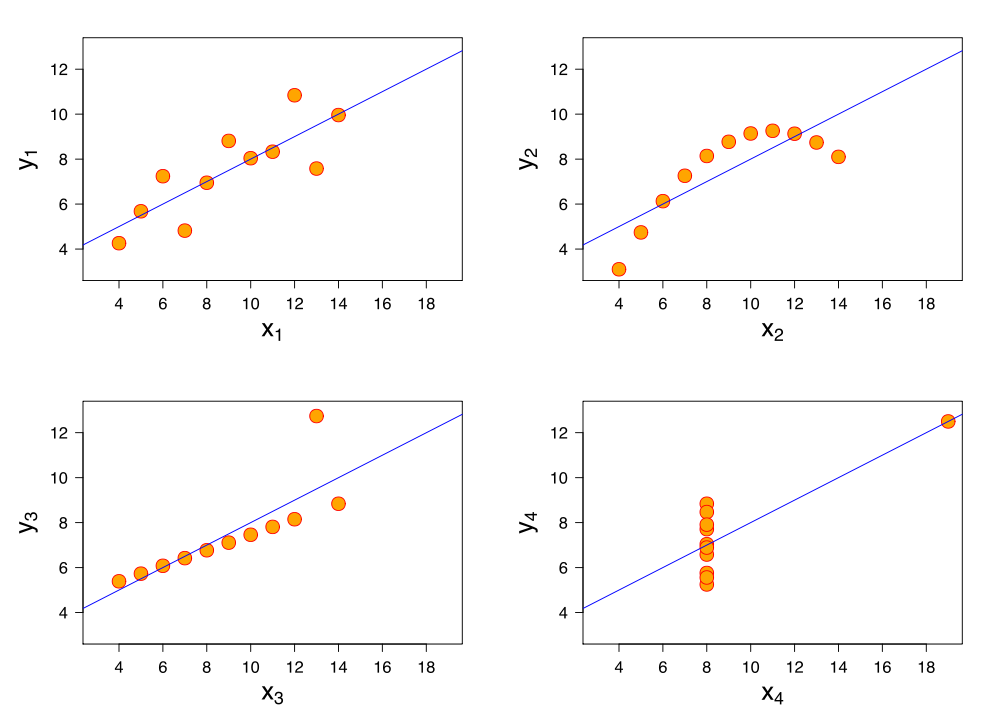
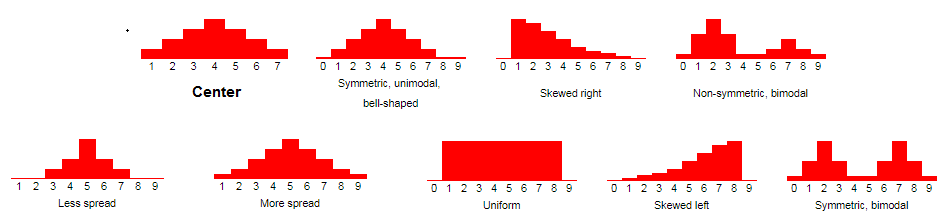
Các ví dụ về data pattern
Data patterns đóng vai trò cực kỳ quan trọng ở những bước đầu tiên của Data mining vì nó cho chúng ta cái nhìn tổng quan về bộ dữ liệu, mục đích của việc thu thập tập dữ liệu này là gì, tập dữ liệu có ý nghĩa phân tích hay không, dữ liệu nào cần quan tâm phân tích để đem lại kết quả dự báo chính xác, dữ liệu nào không liên quan cần loại bỏ để tránh bị “nhiễu thông tin”.,…?
Khái niệm tuy cũ mà mới
Quá trình đào sâu dữ liệu để khám phá các kết nối, mối tương quan giữa dữ liệu và dự đoán xu hướng trong tương lai, theo SAS, đã xuất hiện từ rất lâu. Quá trình đó còn được gọi là “khám phá tri thức trong cơ sở dữ liệu”, thuật ngữ “Data mining” hay “khai phá dữ liệu” mới được biết đến trong những năm 1990. Sự ra đời của Data mining cùng với ba ngành khoa học khác: thống kê (Statistics), trí tuệ nhân tạo (AI-Artificial Intelligence) và học máy (Machine Learning) nhấn mạnh tầm quan trọng, và lợi ích của dữ liệu. Ngày nay, khi Big Data trổi dậy, và tác động đến mọi ngành, lĩnh vực thì các công cụ, phương pháp Data mining ngày càng được biết đến, được ứng dụng rộng rãi, và nhu cầu cải tiến ngày càng cao để có thể bắt kịp khả năng tính toán, tốc độ phân tích, khối lượng dữ liệu, sự đa dạng của Big Data.
Do đó, “what was old is new again”, Data mining tuy cũ nhưng rất mới và lạ lẫm đối với các công ty đang bắt đầu tiếp cận Big Data. Trong những năm vừa qua, sự tiến bộ của công nghệ, kỹ thuật cung cấp các phần mềm với khả năng, tốc độ xử lý thông tin cực kỳ cao cho phép nhiều công ty vượt ra khỏi các công việc thủ công, tẻ nhạt và tốn thời gian để phân tích dữ liệu nhanh chóng, dễ dàng và tự động. Các bộ dữ liệu được thu thập ngày càng phức tạp, nhưng lại chứa đựng nhiều thông tin hữu ích, có giá trị để chúng ta khám phá.
Các công ty bán lẻ, ngân hàng, công ty sản xuất kinh doanh, công ty viễn thông và công ty tài chính,.., đang ứng dụng khai phá dữ liệu để phân tích mọi vấn đề từ tối ưu giá cả, chương trình khuyến mãi, nhân khẩu học đến phân khúc khách hàng, rủi ro, cạnh tranh, marketing đến truyền thông xã hội – ảnh hưởng đến mô hình kinh doanh, mối quan hệ với khách hàng, doanh thu, và hoạt động của toàn bộ tổ chức.
Tại sao Data mining lại trở nên quan trọng?
Số lượng người sử dụng các thiết bị thông minh như smartphone, tablet hay PC, laptop có kết nối Internet để tìm kiếm thông tin, giải trí, trò chuyện, mua sắm,… trên toàn thế giới đang gia tăng với tốc độ tên lửa. Ngoài ra sự xuất hiện của thuật ngữ I.o.T (Internet of Things) miêu tả sự kết nối giữa tất cả các thiết bị với nhau bằng Internet, cho phép trao đổi, truyền tải dữ liệu. I.o.T hỗ trợ con người rất nhiều lĩnh vực không chỉ là vấn đề sinh hoạt trong cuộc sống hàng ngày mà cả công nghiệp, nông nghiệp, bán lẻ đến y tế, xã hội. Các công ty cũng ứng dụng công nghệ I.o.T trong các hoạt động kinh doanh, sản xuất với mục đích tìm kiếm cơ hội gia tăng lợi nhuận, phát hiện sớm các rủi ro. Chính vì những lý do trên mà khối lượng dữ liệu và nhu cầu thu thập, phân tích ngày càng lớn, từ dữ liệu người tiêu dùng, dữ liệu khách hàng đến dữ liệu thị trường, dữ liệu sản xuất,… đa dạng, và phức tạp hơn.
Theo tập đoàn công nghệ Cisco, khối lượng Big Data dự báo trong những năm tới, hay trong năm 2019 có thể đạt 500 Zettabytes một năm. Nguồn dữ liệu Big Data là nguồn lực quan trọng của mỗi tổ chức ngoài nguồn nhân lực và tài chính. Nhưng để tận dụng hiệu quả dữ liệu để đạt được giá trị trong kinh doanh, trong sản xuất,.. thì Data mining là công cụ không thể thiếu, nó giúp chúng ta hiểu được các tập dữ liệu đang thể hiện cái gì, đang cung cấp các thông tin, kiến thức hữu ích nào,…
Lợi ích chính của khai phá dữ liệu

Những lợi ích của Data mining thì rất nhiều nhưng trong bài viết này Big Data Uni sẽ nói một cách tổng quát, còn chi tiết về ứng dụng của Data mining cũng như lợi ích của nó trong từng ngành, lĩnh vực cụ thể sẽ được đề cập ở các bài viết sau. Xét về lợi ích trong quá trình phân tích dữ liệu
+ Chọn lọc, loại bỏ tất cả các dữ liệu không liên quan và dữ liệu trùng lặp trong tập dữ liệu.
+ Xác định các mẫu dữ liệu, dữ liệu có liên quan và dùng các thuật toán phân tích, tận dụng dữ liệu để dự báo kết quả đầu ra ví dụ như xu hướng, hành vi tiêu dùng
+ Với Data mining, chúng ta có thể phân tích khối lượng lớn dữ liệu trong thời gian ngắn và sau đó chuyển đổi dữ liệu đó thành thông tin, kiến thức có ý nghĩa.
Xét về lợi ích sau cùng của Data mining
- Hỗ trợ ra quyết định tự động:
Data mining cho phép các tổ chức liên tục phân tích dữ liệu và tự động hóa cả các quyết định thông thường và quan trọng mà không bị trì hoãn bởi yếu tố con người. Ví dụ các ngân hàng có thể ngay lập tức phát hiện các giao dịch gian lận, yêu cầu xác minh và thậm chí bảo mật thông tin cá nhân để bảo vệ khách hàng chống lại hành vi trộm cắp, tội phạm. Các mô hình tự động của Data mining có thể thu thập, phân tích và xử lý dữ liệu một cách độc lập để hợp lý hóa việc ra quyết định và tăng năng suất hoạt động, tăng lợi nhuận của tổ chức thông qua việc giảm thiểu thời gian, tăng tốc độ các quy trình làm việc, sản xuất, các công việc thông thường hàng ngày.
- Hỗ trợ đưa ra dự báo chính xác:
Dự báo là một quá trình quan trọng trong mỗi tổ chức. Data mining tạo điều kiện lập kế hoạch và cung cấp cho các nhà quản lý dự báo đáng tin cậy dựa trên các xu hướng trong quá khứ và các điều kiện hiện tại. Chuỗi cửa hàng bán lẻ Macy’s của Mỹ thực hiện các mô hình dự báo để dự đoán nhu cầu cho từng loại quần áo tại mỗi cửa hàng và định tuyến hàng tồn kho phù hợp để đáp ứng hiệu quả nguồn cung ra thị trường.
- Hỗ trợ giảm thiểu chi phí:
Data mining cho phép sử dụng nguồn lực hiệu quả hơn. Các tổ chức có thể kiểm soát các hoạt động sản xuất, marketing, bán hàng,.. và phân bổ nguồn lực hợp lý thông qua các công cụ phân tích tự động của Data mining đồng thời phát hiện và ngăn chặn kịp thời các rủi ro, sai sót, qua đó tránh lãng phí, và giảm chi phí hiệu quả. Hãng hàng không Delta gắn chip RFID trong hành lý (đã được kiểm tra) của khách hàng và triển khai các mô hình Data mining để xác định các lỗ hổng trong quá trình vận chuyển và bảo quản hành lý của khách hàng an toàn, giảm tối đa sai sót có thể xảy ra, qua đó làm tăng sự hài lòng của hành khách và giảm chi phí tìm kiếm và định vị hành lý thất lạc.
- Hỗ trợ khả năng thấu hiểu khách hàng (customer insights)
Các công ty triển khai các mô hình Data mining chuyên biệt để phân tích dữ liệu khách hàng nhằm khám phá các đặc điểm chính, các điểm khác biệt về sở thích, thói quen, hành vi,…của mỗi phân khúc khách hàng, xác định nhu cầu mỗi khách hàng một cách chính xác nhất. Dựa vào kết quả thu được, các công ty sẽ triển khai các dịch vụ, sản phẩm, giao tiếp với khách hàng một cách cá nhân hóa hơn. Đặc biệt trong thời đại công nghệ 4.0 ngày nay người tiêu dùng khắp thế giới đang chú trọng vào các hình thức dịch vụ cá nhân hóa nhiều hơn hay còn được gọi “Personlization” nhằm tăng tối đa trải nghiệm khách hàng. Điển hình nhất là ứng dụng Chatbot, hệ thống robot tương tác tự động với khách hàng, phản hồi theo suy nghĩ, lời nói của khách hàng, hay các trang thương mại điện tử như Tiki, Lazada,… đưa ra các gợi ý sản phẩm phù hợp cho chúng ta sau mỗi lần tìm kiếm, tra cứu sản phẩm trên các website, hay Netflix, Youtube đưa ra các gợi ý về video, bộ phim,.. phù hợp với sở thích, mong muốn của chúng ta qua việc phân tính lịch sử xem và lịch sử tìm kiếm.
Thách thức của khai phá dữ liệu

Như đã nói ở trên, do khối lượng dữ liệu mà mỗi công ty, tổ chức phải thu thập ngày nay cực kỳ lớn và phức tạp, đa dạng vô cùng nhưng lại chứa đựng những thông tin hữu ích đem lại các giá trị tiềm năng. Cũng chính vì thế, thách thức đối với các dự án Data mining – trong việc đảm bảo sự hiệu quả trong quá trình thu thập, xử lý và phân tích dữ liệu cho đến việc ứng dụng, triển khai các kết quả đầu ra vào các giải pháp, chiến lược thực tế – ngày một cao hơn. Dưới đây là một số thách thức chính và điển hình:
- Thách thức của Big Data
Các thách thức của Big Data xuất hiện trong mọi lĩnh vực có nhu cầu thu thập, lưu trữ và phân tích dữ liệu. Big Data được đặc trưng bởi 4 tính chất cũng là 4 thách thức lớn đối với Data mining: volume (khối lượng dữ liệu), variety (sự đa dạng dữ liệu), veracity (độ chính xác, tính xác thực dữ liệu), velocity (tốc độ xử lý dữ liệu). Một hệ thống Data mining phải có khả năng đáp ứng các đặc trưng trên thì mới có thể khai thác được các giá trị dữ liệu.
– Volume mô tả thách thức của việc lưu trữ và xử lý số lượng dữ liệu khổng lồ được thu thập bởi các công ty. Lượng dữ liệu khổng lồ đưa ra 2 vấn đề lớn: thứ nhất, khó khăn trong việc tìm được dữ liệu chính xác và thứ hai, nó làm chậm tốc độ xử lý của các công cụ Data mining.
– Variety mô tả thách thức bao gồm nhiều loại dữ liệu khác nhau được thu thập và lưu trữ. Các công cụ Data mining phải được trang bị, nâng cấp để xử lý đồng thời một loạt các định dạng của dữ liệu. Nếu chỉ tập trung vào phân tích các dữ liệu có cấu trúc mà không có biện pháp xử lý dữ liệu không có cấu trúc để phục vụ cho việc khai thác thì đó là một thất bại trong quá trình khai thác giá trị dữ liệu.
– Velocity mô tả thách thức về tốc độ xử lý ngày càng tăng trong quá trình thu thập, lưu trữ và phân tích dữ liệu. Do khối lượng dữ liệu lớn và đa dạng như đã nói ở trên nên tốc độ xử lý dữ liệu càng phải được quan tâm, nếu tốc độ xử lý chậm và công ty không tìm thấy giá trị từ dữ liệu trong thời gian hợp lý sẽ dẫn đến việc gia tăng chi phí, nguồn dữ liệu khai thác không hiệu quả.
– Veracity mô tả thách thức về mức độ xác thực, chính xác của dữ liệu do dữ liệu thu thập rất đa dạng từ nhiều nguồn khác nhau nên sẽ có lúc dữ liệu không cung cấp thông tin chính xác, dữ liệu lộn xộn, không đầy đủ, được thu thập không đúng cách, thậm chí sai lệch. Dữ liệu được thu thập càng nhanh, thì càng nhiều lỗi sẽ xuất hiện trong bộ dữ liệu. Thách thức của tính xác thực chính là cân bằng số lượng dữ liệu với chất lượng của nó nhằm đạt được mục đích sau cùng của Data mining.
- Thách thức trong việc chọn lựa các công cụ, phương pháp Data mining
Các công cụ Data mining khác nhau hoạt động theo những khác nhau do có các thuật toán riêng biệt được sử dụng. Do đó, việc lựa chọn công cụ khai thác dữ liệu một cách chính xác là một nhiệm vụ rất khó khăn. Nếu các kỹ thuật khai thác dữ liệu không phù hợp, thì dữ liệu sẽ không mang lại giá trị như mong muốn.
- Thách thức về mô hình Over-fitting
Mô hình Over-fitting (quá khớp) xảy ra khi mô hình Data mining chỉ tập trung giải thích các lỗi, sai sót trong các mẫu dữ liệu thay vì tập trung nhấn mạnh, thậm chí bỏ qua xu hướng cơ bản của các quan sát trong tập dữ liệu (ví dụ khách hàng đang quan tâm sản phẩm nào, chi tiêu cho sản phẩm đó trong quá khứ như thế nào,..). Ngoài ra các mô hình Over-fitting thường rất phức tạp và chỉ tối ưu việc sử dụng các biến độc lập để đưa ra các dự báo. Thách thức của mô hình Over-fitting sẽ nghiêm trọng hơn khi khối lượng và sự đa dạng của dữ liệu gia tăng. Thách thức còn đề ra trong việc kiểm duyệt số lượng biến thu thập, quá nhiều biến hay quá ít biến sẽ dẫn đến nhiều vấn đề khác nhau, đặc biệt khả năng dự báo kết quả chính xác sẽ bị ảnh hưởng.
- Chi phí trong việc mở rộng hệ thống Data mining và vấn đề training
Khi tốc độ xử lý dữ liệu tiếp tục tăng và khối lượng, sự đa dạng dữ liệu ngày càng cao, các công ty phải mở rộng các mô hình Data mining và áp dụng chúng trên toàn bộ tổ chức. Để đạt được toàn bộ lợi ích của việc khai thác dữ liệu với các mô hình đòi hỏi mỗi công ty phải đầu tư đáng kể vào cơ sở hạ tầng tiên tiến ví dụ như điện toán đám mây (cloud computing) và các phần mềm xử lý chuyên dụng. Để đạt được quy mô, các công ty phải mua và bảo trì các máy tính, máy chủ và phần mềm cao cấp được thiết kế để xử lý số lượng lớn và đa dạng của dữ liệu. Ngoài ra, để sử dụng thành thạo các công cụ Data mining thì yêu cầu nhân viên nếu chưa có kiến thức chuyên môn vững vàng phải tham gia các khóa huấn luyện về Data mining, đây cũng là được tính là khoản chi phí khác mà mỗi công ty phải bỏ ra.
- Bảo mật thông tin và quyền riêng tư (Privacy and Security)
Nhu cầu lưu trữ dữ liệu ngày càng tăng đã buộc nhiều công ty phải chuyển sang sử dụng điện toán đám mây (cloud computing) để xử lý và lưu trữ dữ liệu. Trong khi điện toán đám mây tạo điều kiện cho việc tích hợp các công cụ, phần mềm phân tích của Data mining, nhưng bản chất của điện toán đám mây tạo ra các mối đe dọa cực kỳ lớn về an toàn và bảo mật thông tin. Các tổ chức phải bảo vệ dữ liệu của họ khỏi sự tấn công của tin tặc và hacker nhằm duy trì sự tin tưởng của các đối tác và khách hàng.. Với quyền riêng tư của dữ liệu khách hàng, các tổ chức cần phát triển các quy tắc và ràng buộc nội bộ đối với việc sử dụng và triển khai dữ liệu của khách hàng. Data mining là một công cụ mạnh mẽ cung cấp cho công ty những hiểu biết vô giá về người tiêu dùng của họ. Các tổ chức phải cân nhắc mối quan hệ với khách hàng, xây dựng các chính sách để mang lại lợi ích cho người tiêu dùng và truyền đạt các chính sách này tới người tiêu dùng để duy trì mối quan hệ đáng tin cậy. Đến đây là kết thúc phần 1 tổng quan về Data mining – khai phá dữ liệu, mời các bạn theo dõi các bài viết sắp tới, Big Data Uni sẽ tập trung nói về các ứng dụng của Data mining và các công cụ, thuật toán, quy trình của nó.
Update các phần mới: Tổng quan về Data mining (Phần 2): Ứng dụng trong các lĩnh vựcTổng quan về Data mining (Phần 3): Quá trình và phương pháp
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm lâu năm trong lĩnh vực Big Data sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu Big Data”, “Khai thác dữ liệu Big Data dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.
Nếu bạn có nhu cầu hay thắc mắc hãy đừng ngần lại liên hệ với BigDataUni thông qua số điện thoại hoặc đăng ký thông tin ở mục “Liên hệ” để được chúng tôi tư vấn, hỗ trợ sớm nhất.