
 English
EnglishBigdatauni.com Follow Fanpage Contact
Tiếp tục với chủ đề ứng dụng phân tích dữ liệu trong phân khúc khách hàng, ở bài viết trước chúng ta đã tìm hiểu thế nào là Customer segmentation trong quản lý mối quan hệ khách hàng hay còn gọi là CRM, khái niệm, lợi ích, các dạng/ tiêu chí phân khúc, các bước ứng dụng Data analytics vào Customer segmentation.

Đến với phần 2, BigDataUni và các bạn sẽ đi vào tìm hiểu chi tiết các phương pháp Data mining trong phân khúc khách hàng, và sơ lược cho các ngành bán lẻ, ngân hàng, viễn thông.
Dành cho các bạn chưa xem phần 1:
Data analytics trong phân khúc khách hàng (P.1)
Trước tiên để hiểu rõ các phương pháp phân tích sử dụng trong Customer segmentation, chúng ta cùng sơ lược qua 2 loại mô hình phân tích trong Data mining.
Data mining có 2 loại mô hình:
- Supervised/ predictive models: các mô hình học có giám sát, mô hình dự báo, mô hình có các biến đầu vào, biến mục tiêu được xây dựng với mục đích dự báo khả năng xảy ra của một sự kiện, ước lượng giá trị cho một biến định lượng liên tục nào đó. Các biến đầu vào còn gọi là các biến dự báo (predictor variables), các biến đầu ra gọi là các biến mục tiêu (target variables). Các biến dự báo được gọi là “dự báo” khi chúng được dùng bởi các thuật toán để hình thành cơ sở dự báo cho các biến mục tiêu. Trong phương trình dự báo, các X được coi là các predictor variables và Y là target variables kết quả đầu ra.
Các mối quan hệ giữa các biến dự báo, biến mục tiêu sẽ được tìm thấy, được định lượng thông qua các thuật toán, dưới một hàm ánh xạ, và dùng làm thông tin để đưa ra các dự báo. Gọi là mô hình giám sát, hay học có giám sát, vì các thuật toán sử dụng dữ liệu có “dãn nhán” – mỗi dữ liệu giống như một câu hỏi được gắn nhãn sẵn “câu trả lời” – để xây dựng mô hình dự báo chính xác nhất hay trả lời gần đúng nhất các câu hỏi. Chúng ta giống học sinh đang học về dữ liệu, thì các thuật toán đóng vai trò là các giáo viên “giám sát” giúp chúng ta hoàn thiện kết quả. Nó liên tục cải thiện mô hình phân tích cho đến khi kết quả phân tích đạt yêu cầu.
Supervised/ predictive models bao gồm 3 phương pháp chính:
- Các mô hình phân loại (Classification): mô hình phân loại giúp dự báo các giá trị cho biến mục tiêu là biến định danh (ví dụ có xảy ra hoặc không xảy ra). Mục tiêu là phân loại các đối tượng mới vào các nhóm được định trước, các nhóm có gắn nhãn. Mô hình phân loại giúp dự báo sự kiện quan tâm trong tương lai thông qua ước lượng khả năng xảy ra. Các phương pháp phân tích phổ biến: Decision trees (cây quyết định), Logistic regression (hồi quy tuyến tính), Neural network, Support Vector Machine (SVM), Bayesian models
- Regression: các mô hình hồi quy, giống các mô hình phân loại đều hỗ trợ đưa ra dự báo nhưng điểm khác biệt chính đó là Regression dự báo giá trị cụ thể cho các biến mục tiêu là biến định lượng thông qua các dữ liệu có được, quan sát được từ các biến dự báo.
- Feature selection: lựa chọn thuộc tính (có thể gọi là lựa chọn biến dự báo, biến đầu vào) là bước khởi đầu, được thực hiện trước bước xây dựng mô hình dự báo, các thuật toán lựa chọn thuộc tính đánh giá tầm quan trọng của các yếu tố, các biến đầu vào trong việc hỗ trợ đưa ra dự báo và từ đó xác định, chọn lựa các nào có ý nghĩa phân tích, và loại bỏ những cái không có ý nghĩa phân tích.
- Unsupervised models: ngược lại với các mô hình học có giám sát, mô hình học không giám sát không có các biến mục tiêu, chỉ có các biến đầu vào. Các cấu trúc dữ liệu, mang lại những thông tin hữu ích không bị kiểm soát bởi các biến mục tiêu nào cả, sẽ được khai phá bởi chính các mô hình học không giám sát. Mục tiêu của thuật toán không giám sát là phát hiện ra các mẫu, cấu trúc dữ liệu trong tập dữ liệu đầu vào và xác định các nhóm đối tượng tương đồng, nhóm các trường dữ liệu tương quan, các tập phổ biến (frequent itemset – các đối tượng, các kết hợp đối tượng thỏa mãn tần suất xuất hiện trong tập dữ liệu với độ tin cậy theo yêu cầu), và các dấu hiệu ngoại lệ, bất thường trong tập dữ liệu. Đây gọi là mô hình không giám sát vì không có câu trả lời đúng và không có vị “giáo viên” nào giám sát cả. Các thuật toán được xây dựng để khám phá và thể hiện các cấu trúc hữu ích (insights) bên trong dữ liệu.
Unsupervised models bao gồm 3 phương pháp chính
- Các thuật toán phân phân cụm (Clustering): trong thuật toán phân cụm, các nhóm sẽ không được biết trước, không được gắn nhãn trước như trong Classification, thay vào đó các thuật toán phân tích dữ liệu đầu vào để tìm ra các cụm/ nhóm “tự nhiên” khác nhau, trong mỗi cụm/ nhóm, các đối tượng, điểm dữ liệu hay các quan sát sẽ giống nhau, và giữa các cụm/ nhóm có sự khác biệt (các đối tượng, điểm dữ liệu trong nhóm này khác với các đối tượng, điểm dữ liệu còn lại ở những nhóm khác). Chúng ta sau đó sẽ tìm hiểu đặc điểm của mỗi nhóm và tiến hành gắn nhãn, gọi tên từng nhóm.
- Association rules: là phương pháp khai phá các quy luật kết hợp hay liên kết tiềm ẩn, hay khả năng đi chung với nhau giữa các đối tượng trong dữ liệu, từ đó đưa ra những kết luận “Nếu A đi chung với B Thì…..” Các luật kết hợp được khai phá, phân tích theo trình tự thời gian xảy ra.
- Dimensionality reduction: các thuật toán giảm chiều dữ liệu mà không làm mất nhiều thông tin của các trường (các biến) gốc; bao gồm giảm các biến đầu vào (ví dụ có 100 biến đầu vào, bạn chỉ chọn ra các 50 biến để phân tích, khá giống feature selection), ví dụ đưa không gian dữ liệu từ D chiều xuống K chiều (K < D) khi các điểm dữ liệu, các biến là quá nhiều, từ đó làm chậm tốc độ phân tích, tính toán
Vậy chúng ta đã sơ lược 2 hướng phân tích trong khai phá dữ liệu. Có rất nhiều kỹ thuật phân tích trong Data mining nhưng chỉ một số kỹ thuật được đưa vào sử dụng trong phân khúc khách hàng, trong đó các mô hình Unsupervised models (PCA, Clustering – K-menas) là phổ biến nhất, do các chuyên gia hướng đến khai phá các quy luật tiềm ẩn, thông tin hữu ích, giá trị về khách hàng mà họ chưa biết. Chúng tôi sẽ ưu tiên trình bày sơ lược về PCA, Clustering trong bài viết này.
Các phương pháp khác trong thống kê, Classification, hỗ trợ phân khúc dựa trên các đặc điểm đã biết của khách hàng, dựa trên các quy luật, mục tiêu kinh doanh của các công ty chúng tôi sẽ trình bày song song với các ví dụ trong những bài viết sắp tới.
Các kỹ thuật phân tích phổ biến trong Customer segmentation

Mặc dù các phương pháp Classification và Clustering có thể áp dụng trực tiếp vào dữ liệu nhằm hỗ trợ phân khúc khách hàng hiệu quả tuy nhiên để kết quả phân tích được tối ưu, chúng ta cần trải qua bước đầu tiên là chuẩn bị trong đó giảm các biến, dữ liệu đầu vào, để loại bỏ các thông tin bị thừa, không có ý nghĩa phân tích hoặc đơn giản quá trình phân tích. Mặc dù không bắt buộc, bước này cần triển khai, vì nó điều chỉnh các mối tương quan có thể có giữa các dữ liệu đầu vào, đảm bảo các giải pháp phân khúc mang lại kết quả phân khúc chính xác, không bị “biased”.
Principle Component Analysis (PCA) – phân tích thành phần
PCA, một kỹ thuật phân tích trong Unsupervised models (cũng được xem là phương pháp thống kê) dùng để chuẩn bị dữ liệu trong đó tập trung giảm, loại bỏ dữ liệu của các trường dữ liệu, các biến đầu vào. PCA đưa ra một số lượng hạn chế các biến kết hợp có thể thay thế hiệu quả cho các biến đầu vào ban đầu trong khi vẫn giữ lại hầu hết các thông tin của chúng.
PCA là phương pháp giảm chiều tập dữ liệu lớn (dimensionality – reduction), hiểu đơn giản đó là quá trình chuyển đổi một tập lớn gồm nhiều biến sang một tập biến nhỏ hơn mà vẫn giữ được hầu hết các thông tin trong tập dữ liệu lớn ban đầu.
Giảm số lượng biến của một tập dữ liệu đương nhiên phải trả giá bằng độ chính xác, nhưng lợi ích hướng đến trong việc giảm kích thước tập dữ liệu là đánh đổi một chút độ chính xác để đơn giản hơn quá trình phân tích. Bởi vì các tập dữ liệu nhỏ hơn sẽ dễ dàng khám phá và tìm hiểu các đối tượng nghiên cứu nhanh hơn, cũng như làm cho quá trình phân tích dữ liệu dễ dàng và nhanh hơn khi áp dụng các thuật toán Data mining mà không cần quan tâm đến các biến có thể không có ý nghĩa phân tích.
Lưu ý, PCA nằm trong nhánh Unsupervised models, trong các phương pháp Dimensionality reduction, nhưng cơ chế của nó lại gây hiểu lầm là giống với Feature selection trong Supervised models. Thực ra PCA cũng được coi là Feature selection, cùng có ý nghĩa là lựa chọn các biến nhưng thực chất chúng là 2 phương pháp khác biệt.
Trong PCA, nói đến chiều dữ liệu, tức nói đến không gian dữ liệu được hình thành bởi các biến dữ liệu và các điểm dữ liệu (các quan sát trong tập dữ liệu). Mục đích PCA là chọn ra số chiều dữ liệu K nhỏ hơn số chiều dữ liệu D ban đầu sao cho giữ lại càng nhiều thông tin so với ban đầu càng tốt, để tìm hiểu các tập ít biến nhưng có ý nghĩa hơn một tập nhiều biến gốc ban đầu.
Còn Feature selection yêu cầu chúng ta xác định biến mục tiêu là gì, việc giảm các biến phải dựa trên các mục đích của quá trình xây dựng mô hình dự báo ví dụ ước tính mức độ quan trọng, ý nghĩa phân tích của biến đó trong việc đưa ra dự báo cho biến mục tiêu.
Nói cách khác, cả PCA và Feature selection đều hướng đến tối ưu kết quả phân tích dữ liệu, nhưng PCA giảm các biến, kích thước, chiều của tập dữ liệu trên cơ sở giữ được càng nhiều thông tin càng tốt còn Feature selection tập trung loại bỏ các biến không có ý nghĩa phân tích cho các mô hình dự báo.
Đây là cách phân biệt đơn giản nhất. Sự khác biệt chính giữa 2 phương pháp này thể hiện rõ hơn qua cơ chế hoạt động của chúng.
PCA còn được gọi là một phương pháp thống kê vì công dụng của nó là phân tích mối quan hệ tương quan giữa các yếu tố, các biến đầu vào, và dùng chính thông tin này để tìm ra các số lượng các biến đo lường có giá trị phân tích mà vẫn đảm bảo giữ lại nhiều nhất thông tin trong tập dữ liệu sau khi đã giảm chiều.
Nó hoạt động trên cơ sở tìm ra các biến có tương quan với nhau, và trong các mô hình tích các biến đầu vào có tương quan với nhau sẽ không có nhiều ý nghĩa, cần loại bỏ một trong số đó, để tối giản quá trình phân tích, và tối ưu kết quả. Mặt khác, thông qua PCA, chúng ta cũng có cơ hội khai phá ra được các biến có ý nghĩa phân tích khi nó có mối quan hệ tương quan với biến mục tiêu, mà trước đó không được biết đến. Mục tiêu chính của PCA là nghiên cứu các biến, tìm ra các biến tương quan với nhau, chuyển thành các tập biến mới nhỏ hơn nhưng các biến này không có tương quan với nhau.
Giải thích tới đây có nhiều bạn sẽ lầm tưởng PCA là công cụ trực tiếp loại bỏ các biến không có ý nghĩa? Điều này không đúng!
PCA ban đầu sẽ trực quan dữ liệu bằng không gian dữ liệu đa chiều, mô tả đầy đủ dữ liệu các biến, các điểm dữ liệu trên không gian đó. Tiếp theo, như đã nói, để tìm ra các biến tương quan, PCA sẽ sử dụng không gian mới, ít chiều hơn, và chuyển dữ liệu vào không gian này, vào môi trường mới này để phân tích. Tuy nhiên, điều quan tâm, là phải giữ được hầu hết thông tin, mà không để bị mất khi di chuyển. Thước đo ở đây chính là “phương sai” của dữ liệu.
Kết quả sau cùng của PCA, chỉ là một đồ thị, một không gian dữ liệu ít chiều hơn với các biến cũng như sự tương quan giữa chúng được phản ánh trên đó, hỗ trợ chúng ta phân tích, đánh giá, nên loại bỏ biến nào trước khi xây dựng các mô hình phân tích về sau
PCA sử dụng các công thức chuẩn hóa dữ liệu, Covariance Matrix (ma trận hiệp phương sai), Correlation Matrix (ma trận hệ số tương quan) và Linear regression (hồi quy tuyến tính – công thức kiểm định hệ số hồi quy). Eigenvalues (giá trị riêng), Eigenvector (vector riêng)
Các bài viết sắp tới về case study Customer segmentation trong các ngành chúng tôi sẽ trình bày rõ hơn về từng phương pháp, và sự khác biệt thông qua các ví dụ.
Clustering
Theo cách hiểu đơn giản nhất Clustering là phương pháp phân tích qua đó tập dữ liệu sẽ được phân thành nhiều cụm/ nhóm khác nhau, trong mỗi cụm/ nhóm các điểm dữ liệu hay các quan sát sẽ giống nhau, và giữa các cụm/ nhóm có sự khác biệt (các quan sát trong nhóm này khác với các quan sát còn lại ở những nhóm khác).
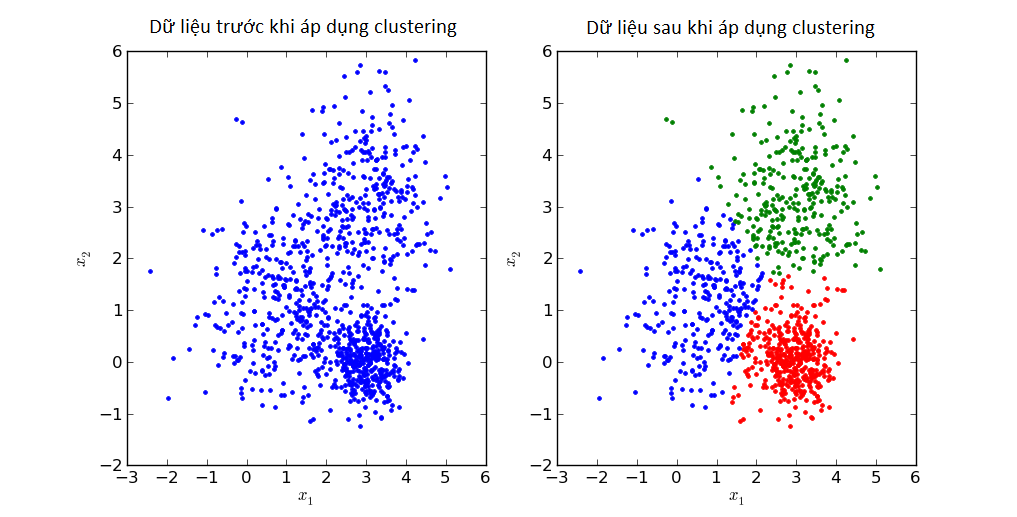
Ví dụ tập dữ liệu khách hàng như đã nói sau khi áp dụng thuật toán phân cụm, giám đốc xác định được 4 nhóm khách hàng chính: (1) nhóm khách hàng thu nhập cao & có khả năng tham gia dịch vụ, (2) nhóm khách hàng thu nhập trung bình & có khả năng tham gia dịch vụ, (3) nhóm khách hàng thu nhập trung bình & không có khả năng tham gia dịch vụ, (4) nhóm khách hàng thu nhập thấp & không có tiềm năng. Các khách hàng ở nhóm 1 phải khác biệt với các khách hàng ở những nhóm còn lại, xét tương tự nhóm (2), (3), (4). Độ chính xác cao thể hiện sự khác biệt rõ rệt và là cơ sở để phân công hiệu quả 4 đội chuyên viên tư vấn vào từng nhóm phù hợp, từ đó phát triển chiến lược marketing, CRM tốt hơn. Và dĩ nhiên chắc các bạn cũng biết nếu một số khách hàng ở nhóm bất kỳ có cùng đặc điểm với các khách hàng ở những nhóm còn lại hay được phân sai nhóm, thì hiệu quả kinh doanh có thể bị tác động. Ví dụ, nhóm (2) và (3) có cùng đặc điểm là khách hàng thu nhập trung bình, vậy nếu không xác định rõ các tiêu chí đánh giá khả năng tham gia dịch vụ thì việc phân cụm sai sẽ xảy ra.
Vì thế clustering nên được gọi là thuật toán phân cụm thay vì thuật toán phân nhóm
Thuật toán Clustering còn có tên gọi khác là segmentation analysis, phân tích phân khúc, vì thuật toán này được ứng dụng khá nhiều trong marketing, sales, và CRM với nhiệm vụ xác định các phân khúc khách hàng để đưa ra các chiến dịch quảng cáo, bán hàng nhắm mục tiêu hiệu quả. Chúng ta sẽ tìm hiểu lại ở phần lợi ích.
Clustering được gọi unsupervised classification (phân loại không giám sát) là phương pháp trong unsupervised learning (học không giám sát) – phương pháp xây dựng các model phân tích – dựa trên tập dữ liệu “không có nhãn”, các điểm dữ liệu chưa được phân loại – mục đích tìm hiểu và trích xuất được những thông tin giá trị về đặc điểm, tính chất của những quan sát bên trong. Khác với supervised learning (học có giám sát), clustering không cố gắng phân loại (classify), không cố gắng ước lượng (estimate), hay dự báo (predict) giá trị của biến mục tiêu.
Các dạng phân tích clustering quan trọng
Cơ chế để clustering hoạt động đó chính là cách thức xác định sự tương đồng (Similarity) và khác biệt (Dissimilarity) giữa các đối tượng quan sát (các object) trong tập dữ liệu. Trong Data mining hay Data analytics, các hệ số, thước đo dùng để tính toán tính tương đồng, giống nhau hay khác biệt là rất đa dạng ví dụ hệ số Jaccard, Sorensen – Dice, hay Simple-matching,… tuy nhiên trong phương pháp Clustering, thì chủ yếu sử dụng Distance metrics như Euclidean distance, Manhattan distance, Minkowki distance,… trong đó Euclidean distance được sử dụng phổ biến nhất.
Các hệ số tính toán mức độ Similarity được sử dụng để mô tả định lượng mức độ giống nhau của hai điểm dữ liệu hoặc mức độ giống nhau của hai cụm: hệ số càng lớn thì hai điểm dữ liệu càng giống nhau. Các thước đo, chỉ số khoảng cách được dùng để định lượng Dissimilarity thì ngược lại: khoảng cách càng lớn thì hai điểm dữ liệu hoặc hai cụm càng không giống nhau.
Công thức Enclidean:
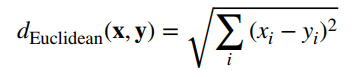
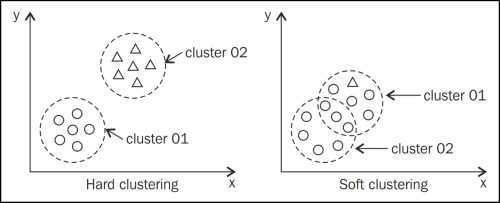
Nếu xét về tính tuyệt đối thì clustering sẽ có 2 dạng là Hard clustering và Fuzzy clustering:
- Hard clustering hiểu đơn giản là một đối tượng quan sát, một điểm dữ liệu hay một object chỉ nằm trong duy nhất 1 cluster mà thôi, tức phải xem xét sự khác biệt giữa các cluster ở mức tối đa, một object bất kỳ khi đã trong 1 cluster thì mặc nhiên nó sẽ khác với các object khác ở những cluster còn lại.
- Fuzzy clustering hay còn gọi Soft clustering thì ngược lại, một đối tượng quan sát, một điểm dữ liệu hay một object có thểm nằm trong 1 hoặc nhiều hơn 1 cluster. Các chuyên gia thường ví von Fuzzy clustering là một dạng clustering kiểu “relaxed”, kết quả từ quá trình phân cụm có thể không cần rõ ràng, phân biệt một cách tuyệt đối như Hard clustering
Nếu dựa trên cấu trúc phân cụm thì clustering có 2 dạng tổng quát:
- Hierarchical clustering: phân cụm theo cấp bậc, gọi là cấp bậc một phần là do tên gọi và một phần là do cách trực quan kết quả clustering. Như ở các ví dụ trên các bạn có thể thấy clustering thường được biểu diễn bằng các hình tròn bên trong là các object giống nhau, còn Hierarchical clustering thường được minh họa bằng biểu đồ Dendrogram.
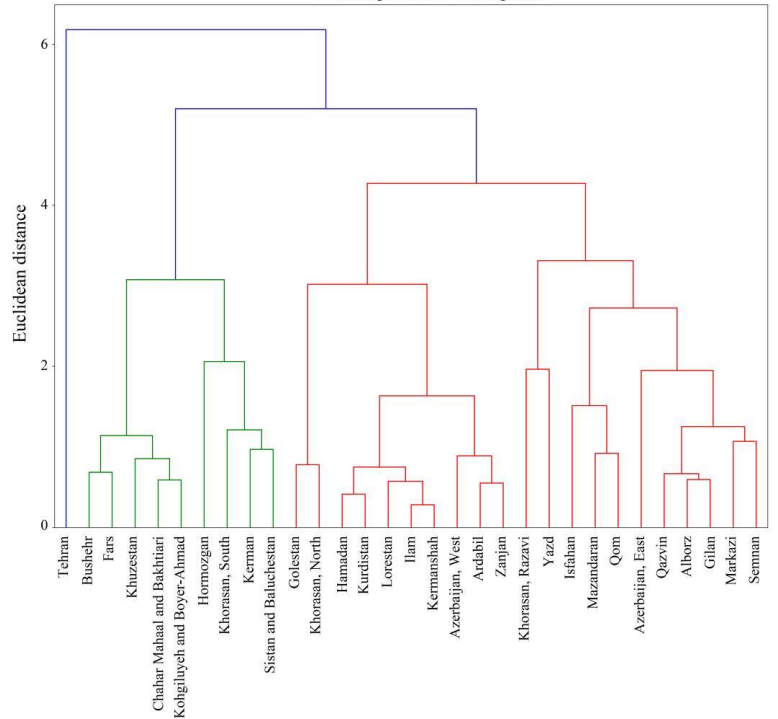
Nguồn hình: “Clustering method for spread pattern analysis of corona-virus (COVID-19) infection in Iran” của tác giả Mehdi Azarafza, Mohammad Azarafza, Haluk Akgün
Hierarchical clustering được sử dụng hiệu quả trong trường hợp chuyên gia phân tích muốn sắp xếp các phân cụm theo cấp bậc.
Hierarchical clustering có 2 dạng chính là Agglomerative (gom tụ) và Divisive (phân tách). Với Agglomerative, bắt đầu mỗi quan sát là một cụm nhỏ của riêng nó. Sau đó, trong các bước tiếp theo, hai cụm gần nhất được tổng hợp thành một cụm kết hợp mới. Bằng cách này, số lượng cụm trong tập dữ liệu sẽ giảm đi một ở mỗi bước. Cuối cùng, tất cả các cụm được kết hợp thành một cụm lớn duy nhất. Còn Dicisive, bắt đầu với tất cả các quan sát sẽ nằm trong một cụm lớn, với các quan sát khác nhau nhất sẽ được tách theo phương pháp đệ quy (recursive), thành một cụm riêng biệt, cho đến khi mỗi quan sát đại diện cho cụm riêng của nó.
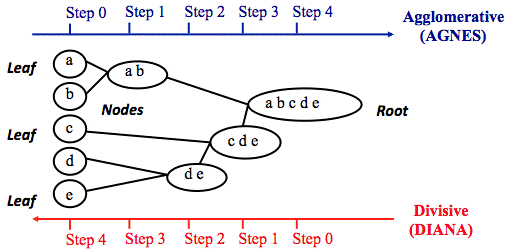
Nguồn hình: Research gate
- Non – hierarchical clustering: những dạng phân cụm không theo quy tắc thứ bậc bao gồm các phương pháp Partitioning (k-means, k-medoids, k-medians), Density – based (phương pháp clustering dựa trên mật độ các quan sát/ object nằm gần nhau trong không gian dữ liệu), Grid-based (một dạng clustering của Density – based nhưng các cluster được xác định và thể hiện trên một cấu trúc dạng lưới). Đây là 3 dạng clustering thông dụng không theo cấp bậc. Ngoài ra còn có nhiều dạng clustering khác phức tạp hơn như Model-based clustering hay Graph-based clustering.
Trong các bài viết sắp tới về ứng dụng Data mining trong phân khúc khách hàng cho ngành bán lẻ, ngân hàng, viễn thông, chúng ta sẽ sử dụng K-means clustering, đây là dạng phân cụm được sử dụng phổ biến nhất ở nhiều lĩnh vực khác không chỉ riêng quản lý mối quan hệ khách hàng hay CRM.
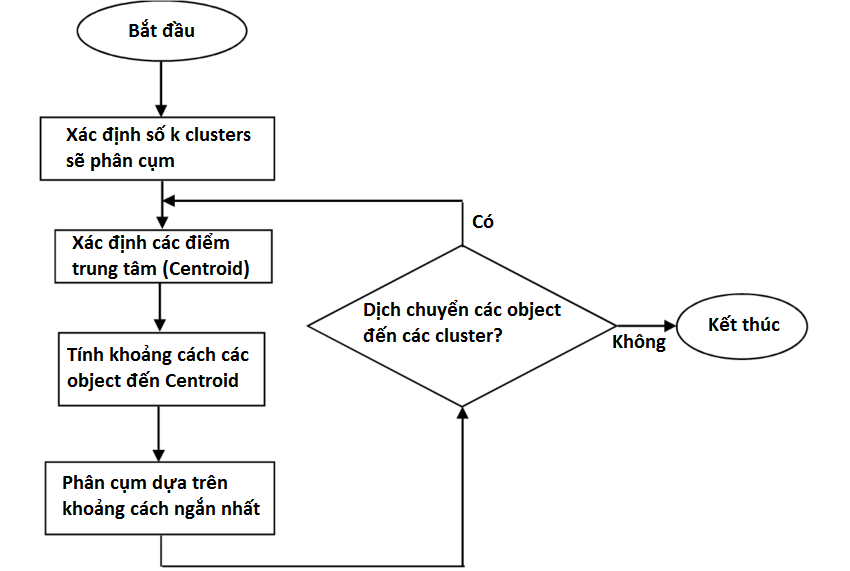
K-means clustering là thuật toán phân cụm thuộc Partitioning clustering, bắt đầu với việc xác định ra số k các cluster sẽ phải phân cho tập dữ liệu, với n số quan sát/ số object thì k ≤ n, tức mỗi cluster phải chứa ít nhất 1 quan sát hay 1 object. Partitioning clustering là phương pháp phân cụm “one-level” tức một cấp, các cluster không được thể hiện dưới dạng cấp bậc.
Hướng tiếp cận cơ bản nhất trong Partitioning clustering chính là tách cụm độc quyền, giống như Hard clustering, mỗi object, mỗi quan sát chỉ thuộc một cluster duy nhất. K-means clustering cũng sử dụng công thức tính khoảng Euclidean để làm cơ sở phân cụm. Flow chart đơn giản trình bày các bước của K-means clustering:
Các phương pháp khác
Trước và sau khi tiến hành phân khúc bên cạnh các phương pháp Data mining vừa trình bày ở trên chúng ta còn các phương pháp khác. Trước khi phân khúc, chúng ta cần tiến hành tóm tắt dữ liệu, trực quan dữ liệu sử dụng các phương pháp thống kê cơ bản. Sau khi phân khúc, để dự báo hành vi của các khách hàng trong từng phân khúc, dựa trên các đặc điểm của phân khúc hay các đặc điểm của chính khách hàng, chúng ta sử dụng các phương pháp phân tích hồi quy (Regression analysis) và xây dựng mô hình phân loại (Classification – Decision trees, cây quyết định).
Do bài viết có giới hạn nên chúng tôi sẽ không trình bày lại, các bạn tham khảo các bài viết thuộc những chủ đề thống kê, Regression, Classification – Decision trees ở mục Blog của chúng tôi.
Lưu ý, các phương pháp thống kê, và thuật toán phân loại, cụ thể Cây quyết định Decision trees, cho phép các công ty phân khúc khách hàng theo mục tiêu kinh doanh hay quy luật tự đề ra về hành vi, đặc điểm của khách hàng đã biết, liên quan đến các sản phẩm, dịch vụ của công ty, và có thể kết hợp với cách phân cụm Clustering tìm ra các phân khúc khách hàng “tự nhiên” nhất, để khai phá các các điểm tương đồng của khách hàng tiềm ẩn trong từng phân khúc.
Như vậy chúng ta đã tìm hiểu sơ lược 2 phương pháp PCA, Clustering trong phân khúc khách hàng. Tiếp tục bài viết, chúng ta sẽ đến phần quan trọng khác là phân khúc khách hàng trong các ngành bán lẻ, ngân hàng, viễn thông.
Customer segmentation trong ngành bán lẻ

Ngành bán lẻ so với ngành tài chính ngân hàng, hay viễn thông được coi là ngành hoạt động sôi nổi và có sự cạnh tranh khốc liệt nhất. Mỗi công ty hoạt động trong lĩnh vực bán lẻ thường có rất nhiều sản phẩm và triển khai bán hàng, marketing trên mọi nền tảng, hay còn gọi là đa kênh. Từ đó họ tiếp cận nhiều khách hàng hơn, thu thập nguồn dữ liệu vô cùng dồi dào từ khách hàng đặc biệt là từ các khách hàng thân thiết, khách hàng thành viên. Vậy tại sao ngành bán lẻ lại rất cần phân khúc khách hàng?
Sự cạnh tranh của nhiều công ty bán lẻ vô hình chung tác động rất mạnh lên lòng trung thành của khách hàng. Khách hàng có quá nhiều sự lựa chọn khi shopping ngày nay, và làm sao để họ quan tâm đến mình đó mới thực sự là quan trọng. Và dĩ nhiên khách hàng chỉ ở lại với công ty khi công ty liên tục dự đoán được chính xác các nhu cầu và thực hiện các hành động bán hàng, marketing đúng sản phẩm, dịch vụ nhanh chóng, phù hợp.
Các công ty bán lẻ trước đây coi chiến lược giá, chiến lược sản phẩm, chiến lược chuỗi cung ứng, tồn kho,… là các chiến lược hàng đầu được sử dụng là “vũ khí” cạnh tranh chính. Nhưng nó thực sự không đủ, “chiến lược khách hàng” thông qua phân khúc khách hàng nên được ưu tiên hàng đầu.
Chiến lược khách hàng ở đây nhấn mạnh vào việc phát triển các chiến lược tiếp thị, sales phù hợp cho từng phân khúc khách hàng tìm được trên cơ sở thúc đẩy thấu hiểu nhu cầu, hành vi, sở thích của từng phân khúc, và đáp ứng chính xác.
Phân khúc khách hàng trong ngành bán lẻ bao gồm nhiều loại, phụ thuộc vào dữ liệu khách hàng mà các công ty bán lẻ có được, và mục đích nghiên cứu của công ty.
- Phân khúc theo nhân khẩu học (nếu có): cái này chắc có lẽ quen thuộc nhất đối với các bạn, ở các bài viết trước chúng tôi cũng đã đề cập qua. Các phân khúc dựa trên thông tin về vị trí địa lý, tuổi, giới tính, nghề nghiệp, thu nhập, tình trạng hôn nhân,…- các dữ liệu nếu có thể thu thập từ các khách hàng thân thiết.
- Ứng dụng của hình thức này là giúp công ty “matching” và “mapping” các sản phẩm, dịch vụ phù hợp với đặc điểm nhân khẩu học của từng khách hàng
- Phân khúc khách hàng theo nhu cầu, sở thích, cảm nhận: dữ liệu nghiên cứu thị trường, dữ liệu khảo sát khách hàng cung cấp các hiểu biết về nhu cầu, sở thích và cảm nhận của khách hàng, hỗ trợ phân khúc, cải tiến hoạt động sales, marketing, cải tiến sản phẩm, dịch vụ hay phát triển cái ý tưởng mới để đáp ứng từng phân khúc.
- Phân khúc khách hàng theo giá trị: đây là hình thức phân khúc theo mục tiêu kinh doanh của các công ty, kết hợp các dữ liệu về nhân khẩu học, nhu cầu, dữ liệu lịch sử giao dịch của khách hàng cũng được sử dụng để phân khúc. Trong bán lẻ, các công ty thường phân khúc khách hàng dựa trên mức độ chi tiêu, và xác định các phân khúc nào sẽ là tiềm năng cần được ưu tiên, các phân khúc nào cần được duy trì.
- Phân khúc khách hàng theo hành vi: trong bán lẻ hành vi khách hàng cung cấp rất nhiều thông tin hữu ích (insights) đặc biệt là những mong muốn thầm kín thường bộc lộ qua cách khách hàng nghiên cứu sản phẩm, so sánh sản phẩm, tìm kiếm theo giá,… kết quả của phân khúc hành vi sẽ giúp công ty xác định chính xác hơn nhu cầu tức thời của khách hàng một cách nhanh chóng, và đưa ra các hành động marketing, sales các sản phẩm phù hợp.
- Phân khúc khách hành theo lịch sử giao dịch: thói quen mua sắm, sự nhạy cảm về giá, khi nào mua, mua ở đâu, các lần mua hàng thường cách nhau bao nhiêu, số lần mua hàng trong tháng, năm,… thông tin về giá trị như tổng số tiền chi ra, số tiền trung bình bỏ ra cho một dòng sản phẩm, số sản phẩm trong giỏ, và số tiền bỏ ra để mua giỏ đó, kênh mua hàng nào thường sử dụng,.. Đó là một số thông tin, dạng dữ liệu về lịch sử giao dịch. Phân khúc theo lịch sử giao dịch cho phép công ty chủ động nhiều hơn, điều chỉnh linh hoạt các hoạt động sales, marketing đa dạng hơn, cá nhân hóa hơn, phù hợp hơn theo thói quen giao dịch, thói quen tiêu dùng của từng khách hàng.
Phân khúc khách hàng theo thói quen mua sắm thường kết hợp với phân khúc khách hàng theo giá trị để tạo thành phân khúc khách hàng theo mô hình RFM.
Mô hình RFM – Recency, Frequency, Monetary là 3 thước đo, mô tả một cách tóm tắt về hành vi khách hàng và giá trị khách hàng mang lại cho công ty. Mô hình RFM được sử dụng phổ biến trong các công ty bán lẻ.
- Recency: thời gian tính từ lần cuối giao dịch, hay lần gần nhất ghé thăm cửa hàng, lần gần nhất truy cập website bán hàng,…tính theo đơn vị ngày, tuần, tháng.
- Frequency: tổng số lần giao dịch, số lần ghé thăm cửa hàng, số lần ghé thăm website được xét trong thời kỳ nghiên cứu, số lần giao dịch trung bình hàng tuần, hàng tháng nếu xét trên một đơn vị thời gian.
- Monetary: tổng số tiền giao dịch hay trung bình số tiền giao dịch trên một đơn vị thời gian hay trong một khoảng thời gian nghiên cứu. Cách tính khác, là số tiền trung bình trên mỗi giao dịch, mục đích là tránh việc Frequency và Monetary có mối quan hệ tương quan ngoài ý muốn, ví dụ số lần mua hàng tăng thì tổng số tiền khách hàng bỏ ra sẽ tăng.
Các khách hàng sau khi được tính toán các giá trị R, F, M. Các giá trị sẽ được sắp xếp theo thứ tự, sau đó được chia thành 5 nhóm, mỗi nhóm chứa 20% tập dữ liệu, và tiến hành gán số cho mỗi giá trị trong R, F, M theo thang đo từ 1 đến 5. Với 5 là mức cao nhất: nhóm 20% khách hàng gần nhất giao dịch, có số lần giao dịch nhiều nhất, số tiền khách hàng bỏ ra nhiều nhất và score 1 là mức thấp nhất, ngược lại. Ví dụ: 555: R = 5, F = 5, M = 5, đây là khách hàng tiềm năng nhất, giá trị nhất (best customer) hoặc 111: R = 1, F = 1, M = 1, là khách hàng ít tiềm năng nhất, giá trị mang lại nhỏ nhất (worst customer)
Mỗi khách hàng sẽ có mỗi điểm RFM tương ứng. Các công ty sẽ xem xét một phân khúc khách hàng có RFM ra sao sẽ gồm những đặc điểm gì, và tiến hành chia nhóm khách hàng.
Phương pháp Clustering được ứng dụng để tối hưu hóa quá trình phân khúc, cụ thể, thông qua clustering chúng ta sẽ tìm được các nhóm khách hàng tương đồng theo 3 giá trị R, F, M trong thực tế, qua đó tránh quá trình công ty tự cho điểm R, F, M một cách chủ quan hoặc mang tính “hời hợt” dẫn đến kết quả không chính xác. Nói cách khác, Clustering không cần chúng ta phải tính điểm mỗi R, F, M theo thang đo 1 – 5 mà trực tiếp phân khúc theo giá trị thực của R, F và M và xác định sẵn các nhóm tương đồng, mỗi nhóm sẽ đại diện bởi 3 giá trị R, F, M cụ thể. Công ty sau đó sẽ “learn” mỗi nhóm, và tìm ra các đặc điểm khách hàng trong đó. Nhược điểm của Clustering là nó không cho công ty “chủ động”, sáng tạo, linh hoạt trong việc nghĩ ra các phân khúc, thay vào đó nó sẽ tự làm, suy ra số lượng phân khúc sẽ nhỏ hơn, nhưng tính chính xác có thể được đảm bảo.
- Phân khúc khách hàng theo nhóm sản phẩm: trong dữ liệu lịch sử giao dịch, bên cạnh hành vi, thói quen mua sắm, số tiền giao dịch, thì thông tin quan trọng khác công ty có thể có đó là thông tin về các sản phẩm, dòng sản phẩm, loại sản phẩm khách hàng hay mua. Công ty có thể tìm hiểu và xác định trong một ngành hàng nhất định, sau một sản phẩm A, khách hàng sẽ mua tiếp sản phẩm B nào. Ví dụ, thời trang, khách hàng mua quần, sau đó sẽ mua giày; ăn uống, khách hàng mua mỳ ăn liền, sẽ mua tiếp nước ngọt,… Đầu tiên ứng dụng phương pháp thống kê đơn giản để biết được khách hàng ưa thích ngành hàng nào mà tiến hành phân khúc, sau đó sử dụng Association rules trong Data mining để tìm hiểu các luật kết hợp “Nếu… thì…” để dự báo sau khi mua sản phẩm nào đó khách hàng sẽ mua tiếp sản phẩm gì.
Việc phân khúc khách hàng theo nhóm sản phẩm có một tác dụng khác đó là công ty sẽ biết được khách hàng ưa thích nhóm sản phẩm đó sẽ mang những đặc điểm gì, nhân khẩu học, hành vi. Những thông tin giá trị giúp công ty tối ưu các hoạt động sales, marketing của mình.
Ở bài viết sắp tới, chúng tôi sẽ đi vào các ví dụ cụ thể để các bạn hiểu được ứng dụng Data mining trong phân khúc khách hàng ở ngành bán lẻ là như thế nào.
Customer segmentation trong ngành Ngân hàng bán lẻ

Ngân hàng bán lẻ hay còn gọi ngân hàng tiêu dùng, là ngân hàng dành cho các khách hàng cá nhân. Các dịch vụ ngân hàng được coi là bán lẻ bao gồm cung cấp tài khoản tiết kiệm và giao dịch, thế chấp, cho vay cá nhân, thẻ ghi nợ và thẻ tín dụng.
Trong ngành Ngân hàng bán lẻ, phân khúc khách hàng được chia thành 2 nhánh lớn đó là nghiên cứu khách hàng sở hữu thẻ tín dụng và nghiên cứu khách hàng sử dụng các dịch vụ của ngân hàng.
Khách hàng sở hữu thẻ tín dụng
Thẻ tín dụng ghi lại thông tin về lịch sử giao dịch của khách hàng cho phép các ngân hàng tìm hiểu, phân tích hành vi, phát hiện ra nhu cầu, thói quen sử dụng thẻ ý tưởng, từ đó phát sinh các ý tưởng, triển khai những hoạt động sales, marketing, tiếp cận thu hút khách hàng tiếp tục sử dụng hoặc đăng ký thêm các dịch vụ khác.
Một người có thể sử dụng thẻ tín dụng của mình theo nhiều cách khác nhau, mục đích khác nhau như mua sắm, trả tiền sinh hoạt, thanh toán điện nước, Internet, điện thoại, thanh toán ăn uống hằng ngày,… và nhiều thứ khác nữa. Hành vi sử dụng thẻ tín dụng sẽ phản ánh phần nào cách sống, tính cách cá nhân, lối sống, hay đang ở trong giai đoạn nào của cuộc đời – là người thích độc thân, tự lập hay đã có gia đình, hoặc đã ly hôn,…
Tùy vào mục đích, tính cách, thói quen, sở thích, một khách hàng có thể sử dụng thẻ tín dụng của mình theo tần suất, và cường độ nhất định.

Ví dụ, khách hàng hay mua sắm online thường sử dụng thẻ tín dụng nhiều lần để thỏa mãn các nhu cầu cá nhân hàng ngày hay hàng tuần, giá trị giao dịch hay số tiền bỏ ra mỗi lần không nhiều. Khách hàng mua sắm ở các siêu thị, trung tâm thương mại, có tần suất ít hơn, thậm chí chỉ 1 lần trong tuần hoặc 1 lần trong tháng, nhưng giá trị giao dịch là rất lớn.
Bên cạnh thông tin về thói quen sử dụng thẻ, các ngân hàng cũng sẽ biết được hạn mức sử dụng thẻ mỗi lần có thể có mối quan hệ với địa điểm sử dụng thẻ. Ví dụ, kênh mua sắm online, khách hàng mua nhiều lần, tiền mỗi lần ít; cửa hàng truyền thống, khách hàng mua ít lần, mỗi lần tiền bỏ ra rất nhiều. Tuy nhiên vẫn có nhiều trường hợp, khách hàng chi nhiều cho kênh online chỉ vì mua một thứ, và thứ đó rất đắt. Như các bạn cũng đã biết các sản phẩm được rao bán trên nền tảng trực tuyến rất nhiều loại và giá tiền khác nhau. Khách hàng có nhiều sự lựa chọn, hành vi vì thế cũng phức tạp, do đó các ngân hàng cần phân tích, nghiên cứu kỹ lưỡng để đưa ra kết quả chính xác.
Thông tin về các sản phẩm dịch vụ trong lịch sử thanh toán giúp các ngân hàng tìm hiểu loại sản phẩm, dịch vụ cụ thể, hay hỗn hợp, tập hợp các sản phẩm, dịch vụ nào khách hàng thường giao dịch bằng thẻ tín dụng. Ngoài ra, một số khách hàng sử dụng thẻ tín dụng để rút tiền mặt tại các máy ATM, thay thế các khoản vay thông thường, mục đích sử dụng cả nhân, nhanh và tiện, ngân hàng có thể nghiên cứu thêm và tìm ra giải pháp.
Thanh toán thẻ tín dụng khi tới hạn là điều bắt buộc với khách hàng. Ngân hàng, nhân cơ hội này cũng tìm hiểu được thói quen, mong muốn của khách hàng khi thanh toán. Ví dụ, sẽ có khách hàng thanh toán thẻ 1 lần duy nhất vào cuối tháng sau khi xác nhận sao kê, người khác thì trả nhỏ từng lần đến khi đủ.
Có rất nhiều thông tin hữu ích mà ngân hàng có thể khai thác từ thẻ tín dụng, kết hợp với các thông tin cá nhân, nhân khẩu học, để tiến hành phân khúc khách hàng và thông qua kết quả phân khúc, thiết kế các chương trình, chính sách ưu đãi, hay chiến lược sales, marketing vừa khác biệt, vừa cá nhân hóa đến từng khách hàng, kích thích nhu cầu, và hành động của họ. Ví dụ đưa ra các loại thẻ tín dụng mới, chính sách thanh toán, quà tặng đi kèm, dịch vụ hỗ trợ cao cấp khác,…
Các phương pháp Data mining ứng dụng trong phân khúc khách hàng ở ngành ngân hàng bán lẻ, mảng thẻ tín dụng cũng bao gồm các phương pháp chính như PCA, Clustering hay Classification.
Các loại phân khúc có thể được chia đơn giản như sau:
- Phân khúc theo nhân khẩu học: tuổi, nghề nghiệp, giới tính, trình độ học vấn, tình trạng hôn nhân, thu nhập hàng tháng, tình trạng bất động sản. Các thông tin này có thể được dùng để đánh giá điểm tín dụng “credit score” ban đầu của khách hàng, sau đó kết hợp với dữ liệu hành vi để đưa ra đánh giá mức độ tín dụng tổng thể của khách hàng
- Phân khúc theo hành vi (sử dụng và thanh toán): phân khúc theo lần gần nhất sử dụng thẻ, số giao dịch trong tuần, tháng, số tiền mỗi lần giao dịch hay tổng số tiền sử dụng trong tháng (giống mô hình RFM trong bán lẻ); địa điểm sử dụng thẻ, thời gian sử dụng thẻ, tần suất rút tiền khỏi thẻ, số tiền trung bình mỗi lần rút, khoảng thời gian thanh toán dư nợ hàng tháng, thanh toán 1 lần hay nhiều lần,…
- Phân khúc theo giá trị: phân khúc theo giá trị trung bình mỗi lần sử dụng thẻ, tổng giá trị sử dụng thẻ mỗi tháng; số dư nợ (số dư trong sao kê) trong thẻ chưa thanh toán;…
- Phân khúc theo nhu cầu sử dụng: phân khúc theo nhu cầu sử dụng thẻ cho mua sắm, và không phải mua sắm, như chăm sóc sức khỏe, sinh hoạt hằng ngày (điện, nước,…), và các hoạt động khác như du lịch, giải trí, học vấn,…
- Phân khúc theo thông tin dịch vụ: loại thẻ sử dụng, thời hạn sử dụng, hạn mức cho phép, các dịch vụ kèm thêm khác,…
Các thông tin kể trên là các tiêu chí được dùng để phân khúc khách hàng, các ngân hàng tùy vào mục đích kinh doanh, mục đích nghiên cứu mà có thể chủ động xây dựng các yêu cầu, kết hợp tiêu chí phân khúc phù hợp. Ví dụ, phân khúc “thường xuyên dùng thẻ”, thông tin nhân khẩu học thường thấy của khách hàng là gì, các ngành hàng thường mua, giá trị mỗi lần giao dịch, nhu cầu thường thấy là gì, loại thẻ thường sử dụng,…
Khách hàng nói chung của ngân hàng
Như đã nói trong ngành ngân hàng bán lẻ, có nhiều dịch vụ khác nhau, tín dụng chỉ là một phần trong số đó, ngoài tín dụng chúng ta còn có gửi tiết kiệm, dịch vụ tài khoản ghi nợ, dịch vụ bảo hiểm (xu hướng Bancassurance – phân phối bảo hiểm qua ngân hàng), thế chấp, cho vay, các dịch vụ đầu tư khác.
Để tiếp cận và giới thiệu các dịch vụ phù hợp với đúng khách hàng có nhu cầu, thu hút họ ra hành động, hoặc xây dựng mối quan hệ với các khách hàng, giữ chân khách hàng, ngăn chặn khách hàng rời dịch vụ, các ngân hành phải tiến hành phân khúc khách hàng trên phạm vi rộng hơn, thay vì chỉ ở mảng tín dụng.
Ngoài mục đích tìm hiểu các đặc điểm khách hàng, các ngân hàng thông qua Customer segmentation, xác định được giá trị lợi nhuận các phân khúc khách hàng mang lại, phân tích xu hướng thị trường, mở rộng ý tưởng kinh doanh, cơ hội tăng giá trị lợi nhuận, nâng cao mức độ hài lòng của khách hàng, đồng thời phân tích vị thế cạnh tranh, định vị thương hiệu trong khách hàng.
Tương tự như tín dụng, đối với khách hàng nói chung, các ngân hàng thường tiến hành phân khúc theo các hướng tiếp cận chính:
- Phân khúc khách hàng theo nhân khẩu học: tuổi, nghề nghiệp, giới tính, trình độ học vấn, tình trạng hôn nhân, thu nhập hàng tháng, tình trạng bất động sản, điểm tín dụng,…
- Phân khúc khách hàng theo giá trị: đây là hình thức phân khúc được mọi ngân hàng ưu tiên, quan trọng và cốt lõi. Khác với phân khúc theo tín dụng, ở đây các ngân hàng kết hợp với thông tin nhân khẩu học về nghề nghiệp, về tài sản, về thu nhập cùng với dữ liệu lịch sử các giao dịch, dữ liệu hành vi, để tiến hành phân khúc. Ví dụ giả sử phân khúc “khách hàng doanh nhân” được coi là phân khúc giá trị cao mà các ngân hàng thường nhắm đến, những khách hàng này thường có thu nhập cao, có bất động sản, có công ty riêng hoặc các tài sản kinh doanh khác, có đăng ký dịch vụ thẻ tín dụng, có các khoản tiết kiệm và đầu tư khác,…có nhiều giao dịch thanh toán, rút tiền, giá trị mỗi lần thường lớn,…
- Phân khúc khách hàng theo hành vi: tìm hiểu cụ thể hành vi sử dụng thẻ ghi nợ, thẻ tín dụng và các dịch vụ gửi tiết kiệm, vay, thế chấp,…
- Phân khúc khách hàng theo loại dịch vụ và nhu cầu: tương tự như phân khúc ở mảng tín dụng, các khách hàng khi đăng ký các dịch vụ khác nhau tại ngân hàng thì cũng sẽ có các nhu cầu khác nhau từ nhu cầu sinh hoạt, nhu cầu mua sắm, nhu cầu bất động sản, học vấn, đầu tư tương lai,…
Sau bài viết ví dụ về bán lẻ, chúng tôi sẽ có một bài viết hướng dẫn cụ thể và chi tiết phân khúc khách hàng trong ngành ngân hàng bán lẻ.
Customer segmentation trong ngành viễn thông

Ngành viễn thông trong những năm gần đây cũng là ngành được coi có sự cạnh tranh khốc liệt không kém gì bán lẻ, và ngân hàng. Nhờ vào sự phát triển của công nghệ kỹ thuật, các thiết bị di động thông minh hay Smartphone ngày nay được phổ biến rất nhiều. So với trước kia, chúng ta thường mua Sim điện thoại hay đăng ký dịch vụ gọi điện, gửi tin nhắn từ các nhà mạng, chỉ quan tâm đến cước phí, số đẹp, độ phủ sóng mạnh,.. thì ngày nay, chúng ta lại quan tâm đến dịch vụ và tốc độ Internet, đặc biệt khi sự ra đời của mạng 4G, và 5G đưa mạng 2G, và 3G từ chục năm trước vào lãng quên. Mặt khác một người có thể sở hũu hơn 1 Sim điện thoại, hay đăng ký nhiều hơn 1 dịch vụ tại nhà mạng, ví dụ bạn có thể sở hữu 1 Sim điện thoại phục vụ liên lạc, gửi tin nhắn và đồng thời 1 Sim mạng để vào mạng, lướt web, Facebook mọi lúc tùy thích.
Chính vì sự cạnh tranh khốc liệt, và tỷ lệ rời dịch vụ của khách hàng ngày càng có xu hướng tăng và việc giữ chân khách hàng khó khăn hơn trước, các công ty mạng viễn thông ngày nay liên tục phát triển các dịch vụ, sản phẩm mới thu hút một cách linh hoạt, đáp ứng các nhu cầu thay đổi liên tục của khách hàng. Một trong các công cụ được sử dụng đó là phân khúc khách hàng.
Khác với ngành bán lẻ, và ngành ngân hàng, ngành viễn thông không có thông tin khách hàng cá nhân hay dữ liệu nhân khẩu học dồi dào đặc biệt ở nước ta, mặc dù năm 2018, đã có các quy định về đăng ký sim chính chủ, cung cấp các thông tin cơ bản về cá nhân như tên, độ tuổi, nghề nghiệp, nơi sinh sống, chứng minh thư, nhưng việc khách hàng thay số điện thoại, thay sim có thể diễn ra thường xuyên, và việc yêu cầu họ đăng ký chính chủ cũng thực sự khó khăn.
Vì thế các hoạt động marketing, sales cá nhân hóa, trực tiếp đến từng khách hàng thông qua hoạt động gửi tin nhắn tổng đài là chủ yếu, bên cạnh kết hợp các hoạt động tiếp thị đại chúng trên nền tảng mạng xã hội, website, TVC là chủ yếu.
Quay trở lại với Customer segmentation, dựa trên các giải thích vừa rồi, các công ty viễn thông thường phân khúc các khách hàng của mình chủ yếu ở 2 hướng chính đó là phân khúc theo giá trị và phân khúc theo hành vi
- Phân khúc theo giá trị: phân khúc khách hàng theo số tiền khách hàng bỏ ra để đăng ký dịch vụ và duy trì các dịch vụ của nhà mạng, thời hạn khách hàng sử dụng thẻ sim, lần gần nhất khách hàng gia hạn dịch vụ, tổng số lần khách hàng gia hạn trong tháng, hay trung bình tháng, các dịch vụ khác kèm theo như Internet, số tiền khách hàng thường chi cho dịch vụ Internet,… Tất cả các thông tin sẽ được dùng để tính chỉ số ARPU (Average revenue per user) hay MARPU (Marginal average revenue per user), hiểu đơn giản là giá trị lợi nhuận trên từng khách hàng và giá trị lợi nhuận trên từng khách hàng sau khi đã trừ đi các chi phí trong việc marketing, thu hút, duy trì khách hàng đó. Sau đó dựa vào các chỉ số này, các công ty viễn thông sẽ tiến hành phân khúc. Các hoạt động marketing từ đó cũng được thiết kế phù hợp theo mục đích kinh doanh, nhu cầu cá nhân của từng khách hàng.
Ví dụ, những khách hàng thường xuyên nạp tiền vào sim để gọi điện, và thời hạn sử dụng sim còn dài, sim được sử dụng lâu, kết hợp với dữ liệu hành vi là thường xuyên gọi điện, các cuộc gọi kéo dài, thì công ty có thể coi khách hàng này là khách hàng trung thành, uy tín, sẵn sàng cho họ ứng trước tiền trong trường hợp khách hàng chưa kịp nạp tiền. Hoặc các khách hàng thường đăng ký dịch vụ Internet mỗi ngày, công ty có thể đề xuất các gói Internet theo tháng.
- Phân khúc theo hành vi: đây cũng là một dạng phân khúc rất quan trọng khác, các công ty viễn thông sẽ dựa vào kết quả phân khúc theo hành vi, để tìm hiểu nhu cầu, cũng như đánh giá mức độ trung thành, hỗ trợ đưa ra các chương trình ưu đãi phù hợp để giữ chân khách hàng. Các dữ liệu thông thường như số cuộc gọi thực hiện trong ngày, tuần, tháng, thời lượng mỗi cuộc gọi (tính theo phút, giây), hình thức gọi đi, nhận cuộc gọi đến, nội địa, hay ngoại địa, thời gian diễn ra các cuộc gọi trong ngày; về tin nhắn, số tin nhắn gửi đến người thân, số tin nhắn dịch vụ, số tin nhắn nhận từ các công ty khác là bên thứ 3 cung cấp dịch vụ (tin nhắn xác thực,…), tần suất gửi và nhận tin nhắn,… rất nhiều thông tin khác nữa.
Bên cạnh hỗ trợ các hoạt động sales, marketing thì việc phân khúc khách hàng theo hành vi, giúp các công ty viễn thông phát hiện các hành vi tội phạm, lừa đảo. Ví dụ các bạn có để ý rằng khi từ chối nhận cuộc gọi từ một số lạ đến mà mình chưa từng biết, hay trả lời cuộc gọi đó và cúp máy ngay vì cuộc gọi đó là từ bên bất động sản, bên cho vay,… làm phiền. Khi cúp máy bạn sẽ nhận được tin nhắn từ nhà mạng rằng liệu bạn có muốn “report” số điện thoại này hay chặn tất cả các cuộc gọi đến từ số điện thoại này? Công ty mạng dựa trên phân tích dữ liệu hành vi về số điện thoại đó và của bạn, dự báo được số điện thoại này hay làm phiền các khách hàng khác không chỉ riêng bạn và tiến hành ngăn chặn kịp thời.
Chi tiết về ứng dụng phân khúc khách hàng trong ngành viễn thông sử dụng các công cụ Data mining chúng tôi sẽ đề cập sau bài viết về Customer segmentation trong bán lẻ, và ngân hàng sắp tới. Mong các bạn tiếp tục theo dõi vào ủng hộ
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.