
 English
EnglishMục đích của phân tích dữ liệu (Data analytics), hay khai phá dữ liệu (Data mining) sau cùng là tìm thấy những thông tin hữu ích, có giá trị và tiềm ẩn (Data insights) trong nguồn dữ liệu từ đó làm cơ sở để đưa ra những quyết định, những giải pháp hành động cụ thể mà chúng ta có thể thấy ở mọi ngành và lĩnh vực hiện nay từ kinh tế, đến khoa học xã hội, rõ nhất là trong thời kỳ cả thế giới đang cùng nhau chống lại Covid – 19. Dữ liệu bỗng nhiên trở thành thứ tài sản vô cùng giá trị đối với tất cả tổ chức hiện nay. Tuy nhiên câu hỏi đặt ra, và cũng là thách thức muôn thuở từ khi ngành Data science ra đời, chính là làm thế nào để đảm bảo có được nguồn dữ liệu đạt chất lượng tốt nhất, và phù hợp nhất cho quá trình khai thác nhằm “Turn data into actionable sights” một cách tối ưu nhất? Câu trả lời ở Data preparation.
Có rất nhiều yếu tố quan trọng tác động và quyết định liệu các dự án tận dụng tài sản dữ liệu có thành công hay không, và một trong số đó là chất lượng dữ liệu, còn gọi là Data quality.
Data quality có thể được hiểu theo 2 hướng tiếp cận: nếu là một chức năng trong quy trình quản lý dữ liệu (Data management), thì data quality bao gồm các công việc, hoạt động cải thiện hoặc duy trì chất lượng của dữ liệu luôn ở trạng thái “hoàn hảo”, trong suốt những giai đoạn xử lý, phân tích dữ liệu; nếu data quality là các tiêu chí đánh giá tính chất của dữ liệu, thì nó bao gồm những chỉ tiêu đo lường (mức độ chính xác, đầy đủ, tính nhất quán, phù hợp,…), những yêu cầu, những tiêu chuẩn mà dữ liệu phải có, phải đạt được trước khi đưa các mô hình phân tích.
“Garbage in Garbage out” – dữ liệu đầu vào nếu bị thiếu sót, chưa được chuẩn bị kỹ càng, sẽ dẫn đến dữ liệu đầu ra hay kết quả phân tích sẽ không có ý nghĩa. Đây là câu nói mà nhiều chuyên gia ngành CNTT và cả Data science thường đề cập nhằm nhấn mạnh các yêu cầu về Data quality. Mặc dù có thể nói, chúng ta phải luôn kiểm soát chất lượng dữ liệu trong vòng đời của nó, từ lúc thu thập, cho đến trình bày kết quả phân tích, nhưng nếu ngay từ đầu dữ liệu đã “tệ”, đã “xấu”, mang trong mình quá nhiều vấn đề thì cho dù làm gì đi nữa, sau cùng, chúng ta cũng không thể đạt được những giá trị mong đợi.
Để dữ liệu đạt chất lượng tốt nhất trước khi được khai phá và phân tích, chúng ta phải đi qua một trong những bước cốt lõi đầu tiên, chính là Data preprocessing (xử lý dữ liệu ban đầu) hay Data preparation (chuẩn bị dữ liệu).
Phần 1 bài viết lần này về chủ đề Data preparation – chuẩn bị dữ liệu, chúng tôi sẽ giới thiệu sơ đến các bạn Data preparation là gì, và đặc biệt tại sao chúng ta không được coi thường hay bỏ qua nó. Còn ở phần 2 sắp tới, chúng ta sẽ cùng đi vào một số phương pháp thực tiễn, kỹ thuật xác định, xử lý dữ liệu bị missing values, hay outliers,… trong quá trình chuẩn bị dữ liệu với các ví dụ cụ thể.
Về định nghĩa Data preparation chúng ta cùng nhìn lại quy trình khai phá dữ liệu hay còn gọi là Data mining. Data mining là một quá trình biến dữ liệu thô thành những thông tin hữu ích, bằng cách sử dụng các phần mềm chuyên dụng để tìm kiếm các quy luật, các mẫu, thông tin có giá trị, mối tương quan tiềm ẩn trong khối lượng lớn dữ liệu. Data mining là một trong những lĩnh vực nghiên cứu khoa học dữ liệu, khai thác và sử dụng các dữ kiện, thông tin có giá trị từ dữ liệu để phục vụ đưa ra dự báo, quyết định trong tương lai.
Một hệ thống quy trình các bước Data mining được coi là quy chuẩn, tiêu chuẩn quốc tế, được áp dụng trong tất cả các ngành và lĩnh vực khác nhau có tên CRISP – DM (Cross-Industry Standard Process for Data Mining).
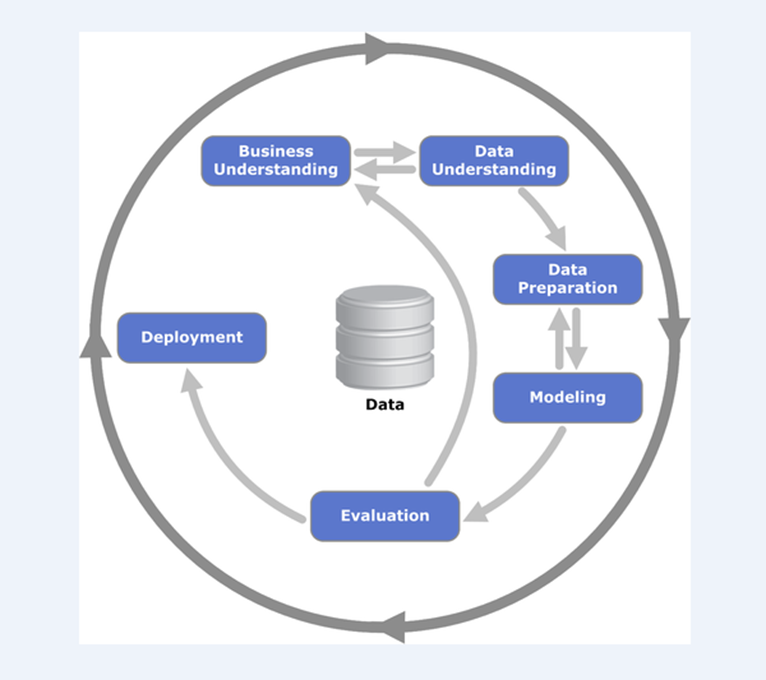
Quy trình CRISP-DM (nguồn hình es.wikipedia.org)
{kind=link}
Quy trình khai phá dữ lieu CRISP – DM bao gồm 6 bước chính với:
Business understanding: xác định yêu cầu, mục đích và các mục tiêu nghiên cứu ở bất kể ngành và lĩnh vực không chỉ riêng kinh doanh. Data understanding: xác định được nguồn dữ liệu cần phân tích, thu thập, tổng hợp và khám phá ban đầu dữ liệu làm quen với dữ liệu, trực quan hóa dữ liệu, xác định các vấn đề của nguồn dữ liệu từ missing values, đến outliers,… Data understanding là bước đệm của Data preparation.
Data preparation, hay chuẩn bị dữ liệu là giai đoạn theo các chuyên gia là tốn nhiều thời gian nhất trong quy trình CRISP-DM, thành quả của giai đoạn này sẽ giúp chúng ta có một bộ dữ liệu hoàn chỉnh cuối cùng để tiến hành xây dựng các mô hình hay còn gọi là model tập trung phân tích và khai thác thông tin. Data preparation gồm một số công việc ví dụ như Data cleaning, Data integration, Data selection, Data transformation. Ở một số tài liệu khác về Data preparation có thể chia thành nhiều hoặc ít hơn những gì chúng tôi liệt kê dưới đây, Data preparation không có một định nghĩa hay một quy tắc tiêu chuẩn được thống nhất, mỗi chuyên gia phân tích có thể có nhiều góc nhìn khác nhau, nhưng đều thể hiện mục đích chung, là thông qua Data preparation, dữ liệu sẽ được đảm bảo về chất lượng – Data quality.
- Select: chọn lọc ra các dữ liệu cần phân tích ví dụ như chọn mẫu, chọn các biến, các cột, dòng dữ liệu có thể liên quan với mục tiêu, cần thiết để phân tích nghiên cứu, sự cân đối của bộ dữ liệu, tránh trường hợp khối lượng dữ liệu quá lớn đưa vào model sẽ làm chậm tốc độ phân tích, ảnh hưởng đến toàn quá trình, đặc biệt loại ra các dữ liệu dư thừa, trùng lặp.
- Clean: làm sạch bộ dữ liệu. Dữ liệu sau khi chọn cần được kiểm tra để tìm ra và loại bỏ dữ liệu “bị nhiễu” , dữ liệu không hợp lý, xử lý dữ liệu ngoại lệ, dữ liệu bị trùng lặp… đặc biệt là xử lý missing value, thêm giá trị vào các dữ liệu chứa missing value (filling in missing value) hay thay đổi missing value bằng các biến giả định phù hợp để chuẩn bị đưa vào model phân tích.
- Transform, construct: chuyển đổi, cấu trúc bộ dữ liệu từ định dạng này sang định dạng khác, từ loại biến này đến loại biến khác, điều chỉnh dữ liệu theo yêu cầu, mục đích của chuyên gia phân tích, thay đổi giá trị dữ liệu sao cho hợp lý, hay xây dựng các dữ liệu mới với loại biến, giá trị mới từ dữ liệu cũ.
- Integrate, format: tích hợp, và điều chỉnh bộ dữ liệu. Quá trình tích hợp cũng cần xây dựng các điều kiện phù hợp để hạn chế sai sót, tránh việc bỏ sót các dữ liệu quý giá. Điều chỉnh dữ liệu nhằm tạo ra bộ dữ liệu gọn hơn, dễ quan sát hơn, tránh bị nhầm lẫn. Format dữ liệu để đảm bảo sự đồng nhất, tránh các vấn đề phát sinh từ việc dữ liệu không tương thích ở các giai đoạn trong khi phân tích.
Ở phần 2 bài viết, chúng tôi sẽ chỉ đề cập đến Data cleaning, vì nó bao gồm các phương pháp, làm sạch dữ liệu được sử dụng phổ biến trong lĩnh vực Data science
Các giai đoạn sau Data preparation, bao gồm đưa dữ liệu đã được chuẩn bị, đảm bảo chất lượng để đưa vào mô hình phân tích (Modelling) và sau đó là đánh giá (Evalutaion), đề xuất, triển khai các giải pháp hành động dựa trên thông tin có được. (Deployment)
Tiếp theo chúng ta cùng đến với nguyên nhân tại sao phải coi Data preparation là bước quan trọng trong bất kể công việc nào liên quan đến dữ liệu:
Data preparation là bước đầu kiểm tra chất lượng dữ liệu
Chất lượng kém sẽ trực tiếp “phá hủy” những giá trị mà mỗi tổ chức mong muốn có được từ dữ liệu. Nguồn tài sản dữ liệu có nhiều vấn đề nhưng lại không có các phương án khắc phục, lâu dần sẽ tác động đến toàn bộ tổ chức, đến từng bộ phận chức năng, chứ không chỉ dừng lại ở các dự án nghiên cứu.
Ví dụ, bộ phận Marketing cần dữ liệu, hay đơn giản là thông tin từ bộ phận Bán hàng và CSKH để lên ý tưởng tiếp thị, quảng cáo. Nhưng nguồn dữ liệu lại không ở trạng thái “tốt”, không được xử lý trước, nhiều thông tin bị nhập sai, không chính xác, không rõ ràng,… nếu bộ phận Bán hàng trực tiếp phân tích, mà họ không xử lý trước dữ liệu thì thông tin đưa đến bộ phận Marketing có thể không đáng tin cậy. Và nếu giả sử, cả Bán hàng, Marketing nhận dữ liệu đã phân tích từ bộ phận Dữ liệu mà chính họ cũng thực hiện kỹ các bước trong Data preparation thì hậu quả sẽ như thế nào?
Dữ liệu thường có những vấn đề sau mà thông qua Data preparation chúng ta phải xử lý như:
- Dữ liệu cung cấp thông tin không đáng tin cậy
- Dữ liệu không đầy đủ, thiếu giá trị tại các ô quan sát
- Dữ liệu bị trùng lặp
- Dữ liệu có giá trị ngoại lệ
- Dữ liệu mơ hồ, khó diễn giải ý nghĩa, không có thông tin mô tả về dữ liệu cụ thể
- Dữ liệu cung cấp thông tin lỗi thời
- Dữ liệu cập nhật trễ
- Dữ liệu có định dạng phức tạp, không nhất quán.
- Dữ liệu không có những thuộc tính, những biến cần cho việc phân tích
Theo một nghiên cứu gần đây của Gartner, công ty đi đầu trong lĩnh vực nghiên cứu và tư vấn, thì những tổ chức được khảo sát (chủ yếu tại thị trường Hoa Kỳ, và một số quốc gia phát triển khác) cho rằng dữ liệu kém làm tổn thất trung bình gần 15 triệu USD mỗi năm. Trong một nghiên cứu của công ty hàng đầu về phần mềm, công nghệ, IBM trong năm 2016, trích trong Havard Business Review thì có đến 3.1 nghìn tỷ USD chi phí bỏ ra cho dữ liệu chất lượng kém hàng năm, chỉ tính trong thị trường Hoa Kỳ. Nghiên cứu khác của Ovum cho rằng dữ liệu kém chất lượng có thể khiến các công ty kinh doanh tổn thất 30% doanh thu.
Chất lượng dữ liệu tốt sẽ tăng khả năng đưa ra những sáng kiến, quyết định, giải pháp hiệu quả và tỷ lệ thành công hơn, hạn chế rủi ro có thể xảy ra cho mọi hoạt động kinh doanh (từ sản xuất, marketing, đến logistics, sale,…) trong hiện tại và tương lai. Dữ liệu chất lượng tốt sẽ được nhanh chóng và dễ dàng đưa vào sử dụng hơn là dữ liệu kém chất lượng, tăng năng suất hoạt động của toàn tổ chức hay công ty đặc biệt quan trọng đối với các tổ chức đang tiếp cận, ứng dụng những xu hướng công nghệ mới như AI, Machine Learning, hay Big Data trong thời đại 4.0, và các công ty đang định hướng Data – driven là chiến lược phát triển ở hiện tại và tương lai.
Chất lượng dữ liệu là động lực thúc đẩy cốt lõi của quy trình Data preparation. Các bạn có thể tham khảo thêm các bài viết của BigDataUni về chủ đề Data quality tại link dưới đây để biết được tại sao Data quality có thể tác động đến kết quả và giá trị nhận được từ những dự án nghiên cứu dữ liệu.
Tổng quan về Data quality – chất lượng dữ liệu (p1)
Tổng quan về Data quality – chất lượng dữ liệu (p2)
Data preparation đảm bảo các thuật toán phân tích sẽ đem lại kết quả phân tích chính xác
Better data => Fancier Algorithms. Dữ liệu tốt hơn sẽ khiến các thuật toán phân tích “hấp dẫn” hơn. Nếu dữ liệu được chọn lọc phù hợp, được làm sạch, được xử lý kỹ càng, thì cho dù các thuật toán phân tích từ ít tinh vi đến tinh vi, từ đơn giản, đến phức tạp đều có thể mang lại những giá trị nhất định, giúp tìm thấy được những thông tin hữu ích, tiềm ẩn trong bộ dữ liệu – Insights. Ngoài ra, Data preparation bên cạnh là bước đầu đảm bảo chất lượng dữ liệu, nó còn giúp hỗ trợ xác thực tính chính xác, và phù hợp của kết quả phân tích từ những thuật toán, phối hợp với các phương pháp đánh giá mô hình (Evaluation) nhằm khẳng định độ tin cậy của kết quả phân tích.
Cũng nói thêm, chưa nói đến giai đoạn sau khi phân tích, một số thuật toán yêu cầu loại dữ liệu đầu vào khác nhau, hay nói đơn giản, dữ liệu không phù hợp về tính chất thì không thể vận hành thuật toán và xây dựng mô hình. Nếu không chuẩn bị lại dữ liệu, thì phải thay đổi thuật toán. Data preparation giúp dữ liệu đầu vào tương thích với yêu cầu của các thuật toán. Ví dụ, ở những bài viết trước về Logistic regression, hồi quy logistic dạng Binary, chúng tôi có đề cập là bộ dữ liệu phải có biến dự báo (biến mục tiêu y) là biến định tính với 2 giá trị định tính, hay biến Flag (biến thay phiên) cũng chỉ có tối đa 2 giá trị, thì thuật toán Binary logistic mới có thể áp dụng. Do đó khi biến mục tiêu y không phải là các loại biến này, cụ thể là biến định lượng liên tục (continuous variable) nếu không chuyển đổi thì chúng ta phải dùng thuật toán Linear/ multi linear regression – hồi quy đơn biến hay đa biến thay vì Binary logistic. Nhưng việc thay đổi thuật toán còn phụ thuộc vào mục đích và nhu cầu của việc phân tích, vậy nên triển khai Data preparation để chuẩn bị dữ liệu phù hợp cũng sẽ tùy trường hợp bắt buộc, và không bắt buộc.
Data preparation là công việc quan trọng trong quy trình phân tích dữ liệu vì tính chất dữ liệu ngày nay.
Dữ liệu mà các công ty, tổ chức thuộc bất kỳ lĩnh vực nào ngày nay thu thập và khai thác là rất nhiều, phức tạp, có nhiều định dạng, đến từ nhiều nguồn khác nhau và khối lượng thường rất lớn (có thể nói với thuật ngữ phổ biến hiện tại là Big Data), luôn thay đổi và biến động, nhờ vào sự phát triển của khoa học, công nghệ.
Nhưng mặt khác nó được coi là tài sản quan trọng nhất hiện nay, bên cạnh nguồn tài chính và nhân lực vốn có của mỗi tổ chức, có thể mang lại vô vàn thông tin hữu ích hỗ trợ cải thiện hoạt động, đề xuất chiến lược phát triển. Nhưng để tận dụng hiệu quả và triệt để thì Data preparation phải cần được chú trọng và triển khai.
Vì tính phức tạp, khối lượng lớn của nguồn dữ liệu hiện tại thì càng đòi hỏi phải khám phá, phải hiểu, phải tổng hợp, phải sàng lọc, phải xác định, phải làm sạch dữ liệu trước khi phân tích. Không nói chắc các bạn cũng hiểu, giả sử một công ty họ dồi dào về tài sản dữ liệu, nhưng liệu họ có đưa hết tất cả vào mô hình phân tích mà không suy nghĩ? Nếu dữ liệu không đảm bảo chất lượng như đã nói ở trên, thì chi phí phải gánh chịu và tổn thất trong ngắn hạn và dài hạn là không hề nhỏ. Nếu dữ liệu đạt chất lượng, nhưng khối lượng quá lớn, có quá nhiều biến mà không phải tất cả đều cần thiết để phân tích, thì có thể sẽ làm chậm tiến độ của quy trình khai phá dữ liệu, cũng làm tăng chi phí về mặt thời gian, về nhân lực.
Mặt khác, nếu thực hiện Data preparation và đã tiến hành chọn lọc được những gì cần thiết nhất để phân tích nhưng cũng không loại trừ khả năng bỏ sót dữ liệu có giá trị, lãng phí tài sản được coi là quan trọng nhất hiện nay. Đây còn gọi là thách thức Dark data.
Khi nhiều công ty đã bắt đầu triển khai các dự án Big Data, hay Data Analytics thì thách thức lớn đối với quá trình phân tích dữ liệu chính là thách thức Dark data. Dark data hay còn gọi là dữ liệu tối, dữ liệu mà theo định nghĩa của Gartner – công ty tư vấn và nghiên cứu thị trường hàng đầu – là dữ liệu, nguồn thông tin mà một công ty, tổ chức thu thập, xử lý, lưu trữ thường xuyên trong quá trình hoạt động kinh doanh nhưng không tìm thấy mục đích sử dụng, không tìm thấy được giá trị của chúng.
Một nghiên cứu từ các công ty nghiên cứu Exasol 2018 khảo sát các chuyên gia các công ty ở Anh và Đức, có 82% cho rằng không thể xác định dữ liệu nào là thực sự quan trọng.
Để hạn chế khối lượng Dark data thì mỗi công ty phải xác định chính xác mục đích của mỗi loại dữ liệu mà mình thu thập, hay phải áp dụng các thuật toán, model phân tích chính xác để khai phá giá trị của dữ liệu và đặc biệt là phải chuẩn bị dữ liệu thật tốt. Nếu dữ liệu thu thập đến sau cùng không đem lại kết quả, thì đây chính là thất bại của toàn bộ dự án Big Data.
Dữ liệu đã không còn giống với 10 năm trước, 20 năm trước, chúng đã khác rất nhiều, và cần một hướng tiếp cận toàn diện để khai thác chúng hiệu quả, và trong đó không thể thiếu Data preparation
Data preparation là một trong các quy trình được những chuyên gia phân tích dành nhiều thời gian nhất khẳng định tầm quan trọng của giai đoạn này
Theo Figure Eight, 60% – phần thời gian ước tính mà các nhà khoa học dữ liệu dành cho việc làm sạch và sắp xếp dữ liệu.
Theo nhà báo nổi tiếng Steve Lohr của tờ New York Times cho biết: “Các nhà khoa học dữ liệu, theo các cuộc phỏng vấn và ước tính của các chuyên gia, thường dành 50% đến 80% thời gian của mình để thu thập và chuẩn bị dữ liệu, trước khi có thể khám phá ra những thông tin hữu ích”
Còn theo IBM, trong bài blog: “Breaking the 80/20 rule: How data catalogs transform data scientists’ productivity” có đề cập đến tỷ lệ 80/20 trong ngành phân tích dữ liệu và tầm quan trọng của Data preparation. Lý do các công ty thuê các nhà khoa học dữ liệu với mục đích đầu tiên là để phát triển các thuật toán và xây dựng các mô hình học máy, thường là các công việc mà các nhà khoa học dữ liệu thích nhất. Tuy nhiên, ở nhiều công ty thường thấy được tỷ lệ 80/20 trong quy trình phân tích dữ liệu: 80% thời gian của một nhà khoa học dữ liệu, thời gian quý giá dành cho việc tìm kiếm, làm sạch và tổ chức dữ liệu, và chỉ còn 20% để thực hiện phân tích, xây dựng mô hình thuật toán.
Theo IBM, khi bắt đầu bất kỳ dự án phân tích mới nào, các nhà khoa học dữ liệu phải xác định các dữ liệu có liên quan, đây là nhiệm vụ không hề dễ. Nhiều nguồn dữ liệu có thể đã bị lãng phí mà không được tìm kiếm và chia sẻ một cách dễ dàng. Các nhà khoa học dữ liệu có thể phải liên hệ với các bộ phận khác nhau để xin dữ liệu họ cần và đợi hàng tuần mới có được, nhưng sau cùng dữ liệu lại không cung cấp thông tin họ cần hoặc có vấn đề nghiêm trọng về chất lượng. Ngay cả khi họ có được dữ liệu phù hợp, các nhà khoa học dữ liệu cần dành thời gian để khám phá và hiểu nó. Ví dụ, họ có thể không biết tập hợp các trường trong bảng dữ liệu đang đề cập đến cái gì ngay từ cái nhìn đầu tiên hoặc dữ liệu có thể ở định dạng có thể khó hiểu hoặc khó phân tích. Sau khi sắp xếp dữ liệu mình cần, các nhà khoa học lại có một nhiệm vụ “nặng nhọc” khác cần thực hiện: chuẩn bị dữ liệu để phân tích bao gồm định dạng, làm sạch và lấy mẫu dữ liệu, trong một số trường hợp cũng có thể phải thực hiện các phép biến đổi tỷ lệ, phân tách và / hoặc tổng hợp trên dữ liệu trước khi bắt đầu đào tạo mô hình của mình. Mục đích của Data preparation, là giúp các nhà khoa học dữ liệu có được nhiều nhất lượng dữ liệu mình cần và với chất lượng tốt nhất.
Tuy nhiên cũng theo IBM, cần có giải pháp để phá vở quy luật 80/20 để cải thiện hiệu suất trong phân tích dữ liệu, bằng nhũng phần mềm, ứng dụng công nghệ, đẩy nhanh quá trình thu thập, tổng hợp, quản trị, tổ chức và chuẩn bị dữ liệu
Trong báo cáo SAS, cùng với tổ chức TWDI (Transforming Data with Intelligence) trong năm 2017, cũng ước tính khoảng thời gian mà các nhà khoa học dữ liệu dành cho Data preparation cũng từ 50% đến 80%. Và cũng giải thích được nguyên nhân tại sao lại có con số này. Thời gian đáng kể được dành cho việc chuẩn bị dữ liệu đơn giản vì dữ liệu thường không ở trạng thái “sẵn sàng” để khám phá và phân tích. Dữ liệu thường được thu thập từ các hệ thống, ứng dụng và kênh cụ thể chỉ được thiết kế để phục vụ một bộ phận, chức năng, chẳng hạn như theo dõi hoạt động của chuỗi cung ứng. Cách thức thiết kế như vậy chỉ tập trung vào các yếu tố cần thiết để giúp chính bộ phận đó vận hành hiểu quả, mà ví dụ ở đây là bộ phận logistics, chứ không theo quy tắc có thể hỗ trợ việc tìm hiểu và phân tích dữ liệu. Nói dễ hiểu, dữ liệu chuỗi cung ứng chỉ có nhân viên chuỗi cung ứng đọc, hiểu, và sử dụng được dễ dàng, và còn đối với những chuyên gia phân tích thì phải mất nhiều thời gian sử dụng các phương pháp khác nhau khám phá dữ liệu. Theo SAS, Data preparation trở thành một vấn đề thậm chí còn lớn hơn khi tổ chức xem xét khai thác dữ liệu lớn được thu thập từ nhiều nguồn khác nhau. Sau khi xác định câu hỏi muốn trả lời, chuyên gia phân tích phải chọn lọc, sắp xếp dữ liệu của mình. Ngoài ra, nếu phân tích nhiều loại dữ liệu, chuyên gia phân tích cũng sẽ cần giải quyết các vấn đề từ tính chất của dữ liệu. Ví dụ, dữ liệu văn bản phức tạp bởi có thể có nhiều ngữ nghĩa, có chữ viết tắt và sai chính tả. Xác định mục đích phân tích chỉ là điểm khởi đầu; chuẩn bị dữ liệu để đạt được mục đích đó mặc dù chiếm nhiều thời gian nhưng cực kỳ quan trọng.
Một khảo sát khác trong năm 2016, thực hiện bởi CrowdFlower, nhà cung cấp giải pháp tích hợp, làm giàu dữ liệu “Data enrichment”, cho rằng 80% thời gian của quy trình phân tích được các nhà khoa học dữ liệu dành cho Data preparation
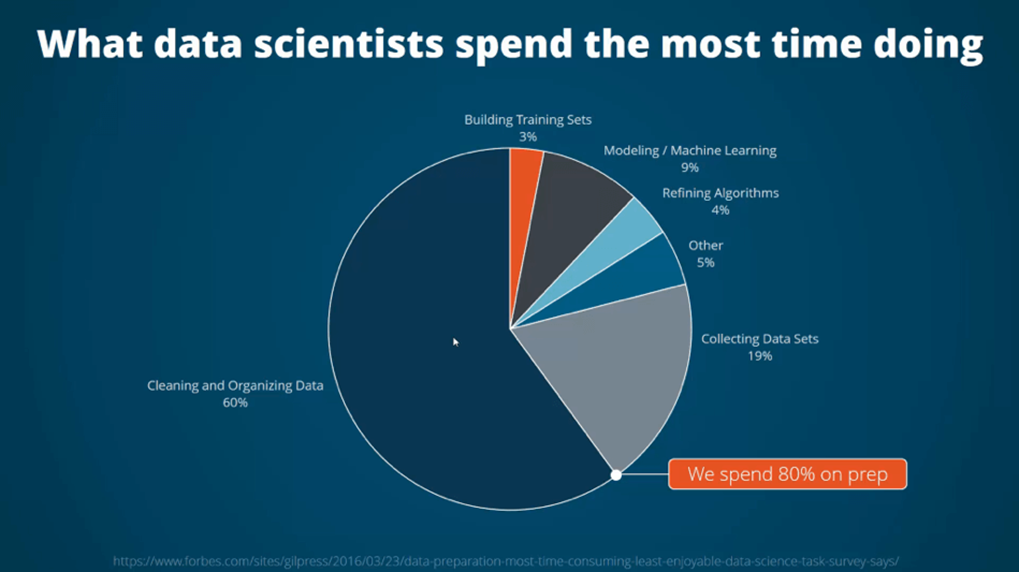
Nguồn hình: Forbes
Các bạn có thể thấy trên hình, làm sạch và tổ chức dữ liệu đã chiếm gần 60%, và thu thập dữ liệu chiếm 19%, có nghĩa các nhà khoa học dữ liệu dành gần 80% để chuẩn bị dữ liệu trước khi đưa vào phân tích. Ở một số trường hợp, xây dựng tập dữ liệu training, phục vụ huấn luyện mô hình cũng được cho là nằm trong giai đoạn Data preparation, nên theo hình nếu tính luôn phần màu cam thì tổng cộng trên 82% để chuẩn bị dữ liệu.
Mặc dù Data preparation quan trọng và chiếm nhiều thời gian nhưng nó lại là quy trình, nhiệm vụ không được các nhà phân tích “ưa thích”, nói nôm na, Data preparation là bước thủ tục phải thực hiện trước khi khai thác dữ liệu. Có thể là công việc nhàm chán, phải tỉ mỉ, cẩn thận và mất nhiều công sức, hơn nữa sẽ dễ làm các nhà phân tích cảm thấy “nản” khi họ phải xử lý vô số vấn đề mà có khi không bao giờ hết đến từ nguồn dữ liệu.
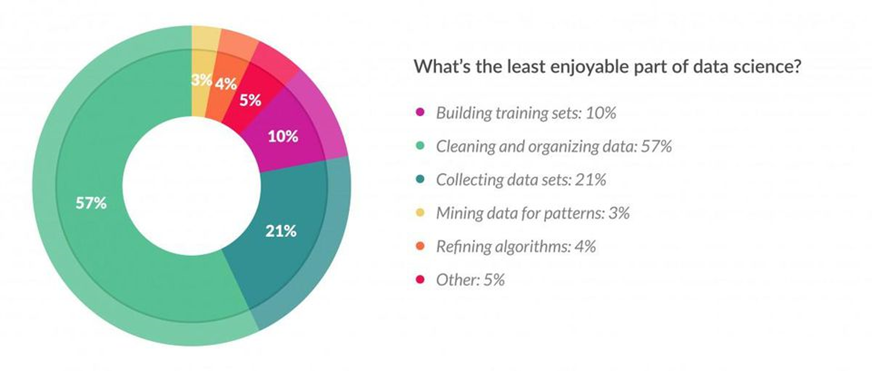
Nguồn hình: Forbes
Làm sạch và tổ chức dữ liệu là công việc ít được ưa thích nhất chiếm đến 57%, số các nhà khoa học dữ liệu được khảo sát.
Vào năm 2009, nhà khoa học dữ liệu Mike Driscoll đã phổ biến đến giới phân tích một thuật ngữ mới là “Data munging”, mô tả quá trình phức tạp, mất thời gian, công sức của việc làm sạch, bóc tách dữ liệu và xác thực chất lượng dữ liệu là một trong những kỹ năng quan trọng của chuyên gia phân tích dữ liệu.
Theo khảo sát khác của Blue Hill năm 2016 các nhà phân tích dữ liệu dành ít nhất 2 giờ mỗi ngày cho các hoạt động chuẩn bị dữ liệu. Và trong 2 giờ mỗi ngày, Blue Hill ước tính rằng chi phí khoảng 22.000 đô la mỗi năm cho mỗi nhà phân tích dữ liệu để chuẩn bị dữ liệu sử dụng trong các dự án phân tích dữ liệu.
Trong khảo sát thị trường Data preparation trên toàn cầu mới nhất của công ty tư vấn Dresner năm 2020. Thì trong số các tổ chức, công ty từ nhiều ngành và lĩnh vực khác nhau, với quy mô từ nhỏ đến lớn, đến từ các quốc gia khác nhau thì gần 80% cho rằng Data preparation là nhiệm vụ quan trọng:

Nguồn hình: Dresner Advisory Services
Một số nguyên nhân khác giải thích tại sao Data preparation quan trọng
- Data preparation giúp việc chia sẻ dữ liệu diễn ra một cách hiệu quả mà vẫn đảm bảo chất lượng dữ liệu trong suốt quá trình truyền tải, giúp đẩy nhanh việc đạt được giá trị từ tài sản dữ liệu.
- Đối với các công ty kinh doanh, tích hợp các nguồn dữ liệu đa dạng là một nhiệm vụ quan trọng của các quy trình chuẩn bị dữ liệu. Ví dụ, bộ phận sales và marketing muốn tương tác với khách hàng hiện tại và khách hàng tiềm năng trên nhiều kênh khác nhau, bao gồm cả social media và cần một luồng dữ liệu ổn định từ các hoạt động trong mỗi kênh này. Để có được một cái nhìn hoàn chỉnh và có thể phân tích độ hiệu quả của các chiến dịch tiếp thị và bán hàng đa kênh, các công ty cần thu thập, tích hợp dữ liệu, chuyển đổi phù hợp và đưa vào mô hình phân tích để tìm thấy được nhiều thông tin có giá trị.
- Data preparation là cơ sở giúp tổ chức đưa ra các chiến lược tổng thể, các quyết định hợp lý, tiềm năng mang lại nhiều giá trị hơn só với mục tiêu đề ra, dựa vào nguồn tài sản dữ liệu chất lượng, đã được chuẩn bị để đưa vào khai thác.
- Các công cụ trong chuẩn bị dữ liệu cũng cho phép người dùng tại các công ty tăng niềm tin vào dữ liệu, bằng cách làm phong phú các bộ dữ liệu, kiểm tra những vấn đề trong bộ dữ liêu và tích hợp thêm thông tin để giảm thiểu dữ liệu bị thiếu sót. Các công cụ Data preparation cho phép người dùng đánh giá độ chính xác của dữ liệu trước khi đầu tư thời gian và tài nguyên để phân tích. Do đó, người dùng có thể tiết kiệm rất nhiều thời gian, đẩy nhanh tiến độ các dự án nhằm đạt được những giá trị mong đợi.
- Với độ chính xác và chất lượng dữ liệu khi được cải thiện, tốc độ xử lý dữ liệu sẽ tăng lên. Data preparation giúp tổ chức phản ứng nhanh hơn với các vấn đề phát sinh trong hoạt động kinh doanh thông qua việc có được những báo cáo phân tích dữ liệu trong thời gian ngắn. Do đó, những hiểu biết giá trị có thể được rút ra ngay lập tức, hỗ trợ sự hợp tác giữa các phòng ban kịp thời, sau cùng nâng cao năng suất hoạt động của tổ chức.
- Tác động chính của Data preparation là nâng cao giá trị thực của dữ liệu cũng như hiệu quả của việc phân tích, không chỉ cho phép ra quyết định nhanh hơn, cải thiện sự hài lòng và giúp những nhân viên không có chuyên môn cao về phân tích dữ liệu có thể sử dụng dữ liệu cho công việc của họ tốt hơn khi cần mà không cần quan tâm đến các vấn đề trong dữ liệu vì chúng đã được xử lý trước đó.
- Với các giải pháp và công nghệ cải tiến trong Data preparation, tổ chức có thể đối phó tốt hơn với các vấn đề hiện tại của dữ liệu và chuẩn bị cho những thách thức mới trong tương lai, xuất phát từ những dữ liệu mới. Họ có thể sử dụng Data preparation để xây dựng giá trị của tài sản dữ liệu và quản lý chúng hiệu quả hơn. Quan trọng nhất là các giám đốc điều hành, các quản lý và phần còn lại của một tổ chức sẽ có thể nhận được dữ liệu cần thiết nhanh hơn và sử dụng chúng hỗ trợ đưa ra các quyết định chiến lược với niềm tin, độ tin cậy cao.
Đến đây chúng tôi xin kết thúc phần 1 bài viết về Data preparation, ở bài viết phần 2 chúng ta sẽ đi vào Data cleaning với một số phương pháp xử lý dữ liệu missing value, và dữ liệu ngoại lệ. Mong các bạn tiếp tục ủng hộ BigDataUni.
Tài liệu tham khảo
https://www.gartner.com/doc/2636315/state-data-quality-current-practices
https://hbr.org/2016/09/bad-data-costs-the-u-s-3-trillion-per-year
www.exasol.com/en/community/resources/resource/moving-the-enterprise-to-data-analytics/
https://www.ibm.com/cloud/blog/ibm-data-catalog-data-scientists-productivity
https://www.sas.com/content/dam/SAS/en_us/doc/whitepaper2/tdwi-data-preparation-109318.pdf
rapidminer.com/blog/data-prep-time-consuming-tedious/
http://bluehillresearch.com/quantifying-the-case-for-enhanced-data-preparation/
https://www.trifacta.com/gated-form/dresner-survey-2020/
https://www.dezyre.com/article/why-data-preparation-is-an-important-part-of-data-science/242
www.ironsidegroup.com/2019/07/16/data-preparation-business-analytics/
ericbrown.com/data-analytics-data-preparation.htm
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.