
 English
EnglishNhư vậy, trong 3 bài viết trước tìm hiểu về các kiến thức căn bản của linear regression trong bán lẻ với ví dụ đơn giản về dự báo doanh thu của một cửa hàng quần áo, bao gồm xây dựng phương trình, lựa chọn biến phù hợp, kiểm tra độ hiệu quả của mô hình bằng hệ số xác định R2 và kiểm định F, dự báo giá trị của biến mục tiêu, cũng như tìm hiểu về vấn đề đa cộng tuyến.
Để kết thúc series các bài viết về hồi quy tuyến tính, trong phần cuối chúng ta sẽ cùng đi qua 1 ví dụ khác để nhìn lại linear regression lần cuối trước khi sang phương pháp phân tích hồi quy khác.
Các kiến thức cơ bản, các bạn vui lòng xem lại những bài viết trước về ứng dụng linear regression trong bán lẻ, ở mục Blog của chúng tôi.
Case study mà chúng ta sẽ tìm hiểu trong bài viết này đó chính là thông qua hồi quy tuyến tính làm cách nào để xác định vị trí xây dựng cửa hàng mới của một chuỗi bán lẻ tại Mỹ. Case study được tham khảo từ khóa học Business Analyst của trường Đại học trực tuyến Udacity.
Một chuỗi bán lẻ đồ dùng, đồ ăn cho thú cưng ở tiểu bang Wyoming Mỹ có 13 cửa hàng khắp cả tiểu bang và đang dự định mở thêm cửa hàng thứ 14 cũng trong cùng tiểu bang này. Vị giám đốc đề ra yêu cầu cho bộ phân kế hoạch là phải phân tích dữ liệu lịch sử để dự báo doanh số tại những địa điểm khả thi hay nói cách khác là các thành phố mà tại đó có thể xây cửa hàng mới.
Một số yêu cầu đề ra, hay tiêu chí để chọn lựa thành phố, giả định tỷ lệ người Mỹ nuôi thú cưng rất cao.
- Cửa hàng mới này phải nằm trong một thành phố mới nghĩa là thành phố này không có cửa hàng khác của chuỗi bán lẻ, cửa hàng bán lẻ mới này là duy nhất của công ty trong thành phố này.
- Tổng khối lượng hàng bán (sale volumes) của các đối thủ cạnh tranh (cùng trong mảng bán lẻ đồ dùng, thực phẩm thú cưng) trong thành phố này phải thấp hơn 500.000 USD (đã tính theo giá trị tiền chứ không phải số lượng, tức doanh số sau cùng của tất cả các đối thủ trong 1 năm theo dữ liệu lịch sử) dự báo cho năm 2014
- Dân số của thành phố này phải hơn 4000 người, căn cứ dự báo dân số ở Mỹ năm 2014
- Dự báo doanh thu bán lẻ 2014 tại thành phố này phải trên mức 200.000 USD và dĩ nhiên doanh thu dự báo bán lẻ tại thành phố này phải hơn những thành phố còn lại trong danh sách chọn lựa
Dữ liệu người giám đốc yêu cầu bộ phận IT đưa bộ phận kế hoạch phân tích bao gồm doanh thu của công ty, doanh thu của đối thủ và các dữ liệu về dân số, hộ gia đình, diện tích từng thành phố,…chúng ta phải xét xem liệu dữ liệu này có phù hợp để phân tích hay không. Chúng ta sẽ đóng vai bộ phận kế hoạch để tìm ra kết quả phân tích, và kết luận đến giám đốc.
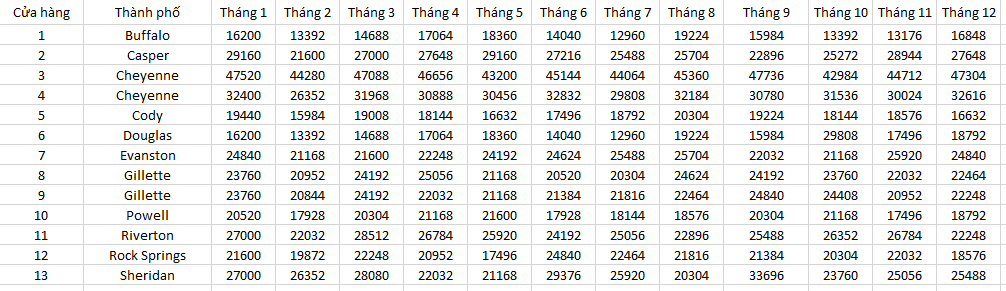
Doanh thu của các cửa hàng tại các thành phố chúng ta sẽ phân loại và tính tổng theo thành phố cụ thể như sau:
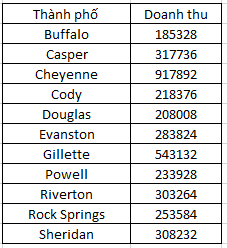
Bên trên sẽ là dữ liệu để chúng ta xem xét để tránh đặt địa điểm cửa hàng mới nằm trong các thành phố kể trên để đảm bảo tiêu chí lựa chọn, đồng thời sẽ được dùng để lập phương trình dự báo doanh thu cho công ty tại mỗi thành phố. Tiếp đến là dữ liệu về doanh số của các đối thủ cạnh tranh ở các thành phố trong năm trước, bao gồm tại các thành phố chưa có cửa hàng của công ty.
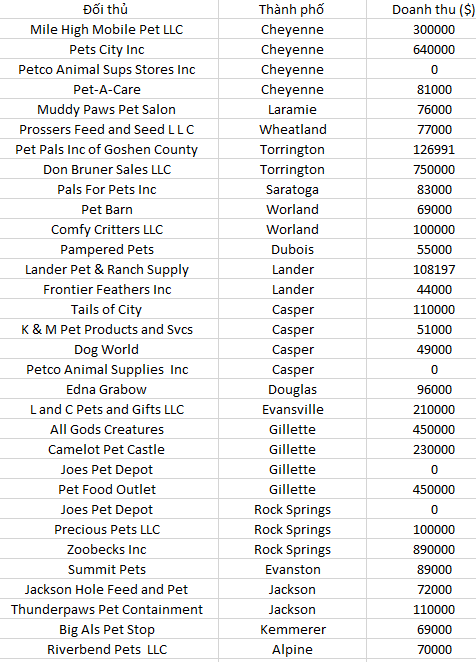
Tương tự chúng ta tính tổng theo thành phố:
Chúng ta có một số dữ liệu nhân khẩu học khác bao gồm diện tích mỗi thành phố, số hộ gia đình có người dưới 18, tổng số gia đình, mật độ dân số. Ví dụ mẫu:
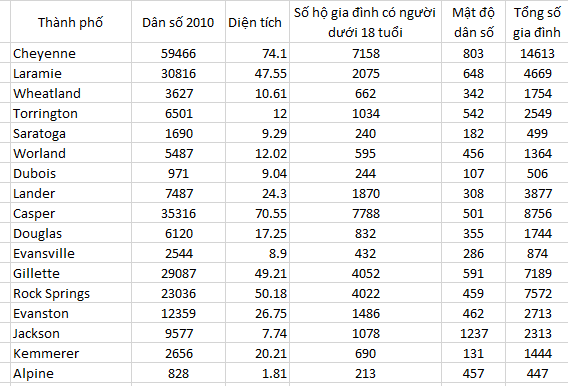
Như vậy có 2 việc cần làm, đầu tiên chúng ta sẽ lập phương trình dự báo doanh thu của công ty dựa trên biến độc lập bao gồm các biến thuộc nhân khẩu học, các biến về hộ gia đình đặc trưng của mỗi thành phố (có chi nhánh của công ty), và chúng ta sẽ dùng phương trình này để dự báo cho các thành phố mới chưa có chi nhánh của công ty bằng cách thay giá trị đặc trưng vô phương trình.
Tiếp theo chúng ta sẽ lập phương trình dự báo tổng doanh thu của các đối thủ cạnh tranh trong chính từng thành phố (kể cả thành phố có chi nhánh của công ty)
Chúng ta sẽ có 2 tập dữ liệu cần dự báo, lưu ý trong bài viết này chúng tôi chưa đề cập đến outliers
- Dữ liệu bao gồm biến doanh thu của công ty (biến mục tiêu), và các biến dự báo khác
- Dữ liệu bao gồm biến tổng doanh thu của các đối thủ cạnh tranh (biến mục tiêu) và các biến dự báo khác.
Tập dữ liệu để dự báo doanh thu của công ty tại các thành phố:
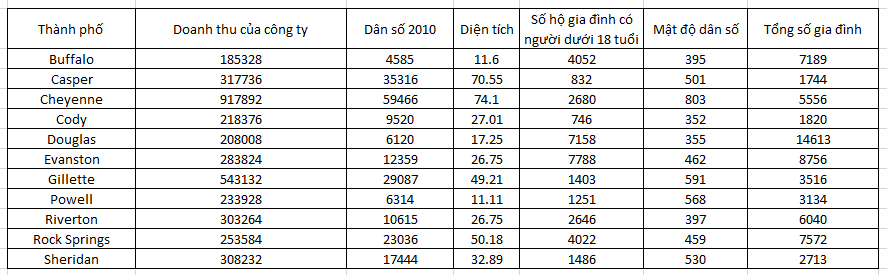
Chúng ta tìm hiểu ma trận hệ số tương quan để xem xét mối liên hệ giữa các biến như đã đề cập ở các bài viết trước.
Dựa vào kết quả dưới đây có thể thấy 2 biến liên quan đến hộ gia đình có hệ số tương quan thấp với biến doanh thu công ty, không tiến gần -1 hay 1, và p-values lớn hơn 0.05 (nếu xét cả 0.01 là mức ý nghĩa), khẳng định không có mối liên hệ nhất định. Mặc dù số hộ gia đình không có ý nghĩa để đưa vào mô hình nhưng mật độ dân số, và dân số 2010 lại có hệ số tương quan cao với biến doanh thu công ty, tương tự như biến diện tích. Lý do có thể giải thích đơn giản là ở Mỹ tỷ lệ người sống độc thân có thú cưng bên cạnh là rất cao, các bạn xem phim Mỹ cũng có thể thấy được.
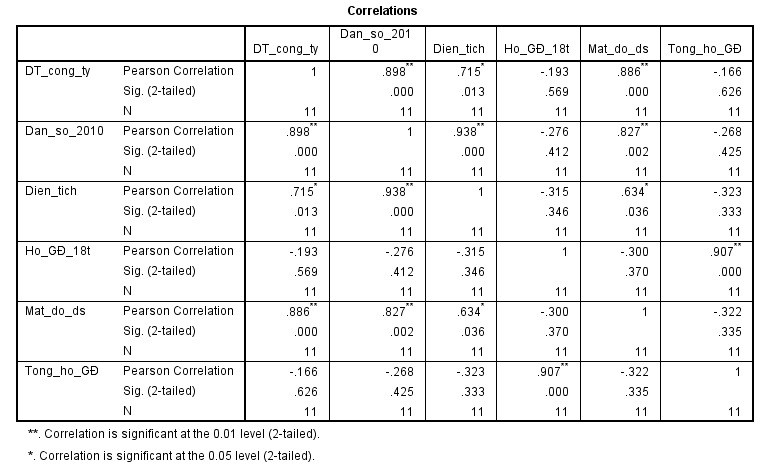
Tiếp theo xét đến vấn đề đa cộng tuyến, số hộ gia đình có người dưới 18 tuổi và tổng hộ gia đình có hệ số tương quan cao, hiển nhiên vì tổng hộ gia đình bao gồm biến số hộ gia đình có người dưới 18 tuổi. Chúng ta đã loại bỏ 2 biến này ra nên không cần quan tâm nữa.
Với 3 biến dân số 2010, diện tích, và mật độ dân số, thì biến mật độ dân số và dân số 2010 có hệ số tương quan cao do mật độ dân số tính bằng = tổng dân số / diện tích vậy nên khi một biến tăng thì biến còn lại sẽ tăng. Do đó chúng ta loại bỏ bớt một biến, cụ thể ở đay chúng tôi sẽ chọn biến dân số 2010. Giá trị p-value của kiểm định hệ số tương quan đều nhỏ hơn 0.05 củng cố thêm kết luận.
Sau cùng 2 biến còn lại thích hợp đưa vào phương trình chỉ có biến dân số 2010, và biến diện tích. Tuy nhiên 2 biến này lại có mối quan hệ tương quan mạnh với nhau, đơn giản thành phố nào diện tích lớn thì đông dân hơn, có thể gây ra vấn đề đa cộng tuyến và giá trị VIF sẽ rất cao. Tuy nhiên trong thực tại diện tích không tăng mà dân số có thể tăng hoặc giảm giữa các thành phố có thể do thiên tai, tình hình kinh tế,… Với cơ sở biến diện tích được dùng để cung cấp thông tin xác định tỷ lệ tương quan và mặc dù có đa cộng tuyến, nhưng 2 biến này đều có ý nghĩa cho việc dự báo biến mục tiêu ví dụ chúng ta muốn biết doanh thu công ty thay đổi thế nào khi dân số thay đổi, hay di chuyển chi nhánh sang thành phố khác.
Sử dụng phương pháp Stepwise chúng ta kết luận chắc chắn hơn. Nhắc lại lần nữa, để tìm hiểu phương pháp stepwise là gì hay các kiến thức liên quan các bạn hãy xem lại những bài viết của chúng tôi về linear regression trong mục blog.
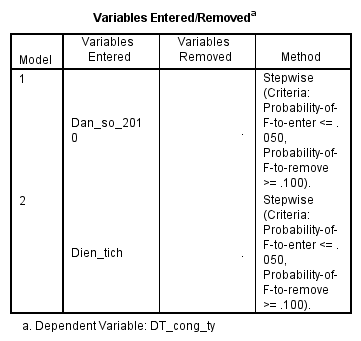
Trong thực tế chúng ta phải xem xét rất nhiều biến độc lập khác như những giải pháp dự phòng thay thế cho vấn đề đa cộng tuyến hoặc tăng cỡ mẫu hay thiết kế lại quy trình nghiên cứu. Ví dụ ở bài viết này để tham khảo nhằm hiểu thêm về linear regression chứ chưa thể áp dụng hoàn toàn vào thực tế. Kết luận ban đầu, dữ liệu này là không phù hợp để phân tích.
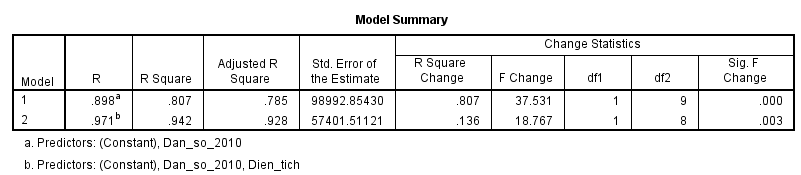
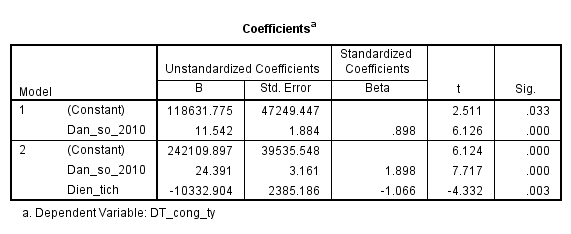
Hệ số xác định R2 cao và tăng lên so với mô hình 2, kiểm định F và kiểm định t đều có đều p-value (sig) < 0.05 càng khẳng định mối liên hệ giữa 2 biến với biến doanh thu.
Chúng ta có phương trình dự báo doanh thu của công ty như sau:
Y = 242110 + 24.4* Dân số 2010 – 10333*Dien tich
Theo yêu cầu lựa chọn thì doanh thu của công ty tại các thành phố mới đều phải trên 200000 USD, chúng ta sẽ thay giá trị diện tích, và dân số 2014 (dự báo) vào đề dự báo, và chọn lựa.
Dự báo ở trong bài viết này là ước lượng điểm, tức sử dụng trực tiếp phương trình bằng cách thay giá trị trực tiếp, do yêu cầu 200000 USD, là giá trị cụ thể.
Ở đây chúng ta quan tâm đến các thành phố có đối thủ cạnh tranh, nên chỉ còn lại các thành phố sau, dân số 2014 dự báo có sẵn sẽ được đưa vào phương trình:
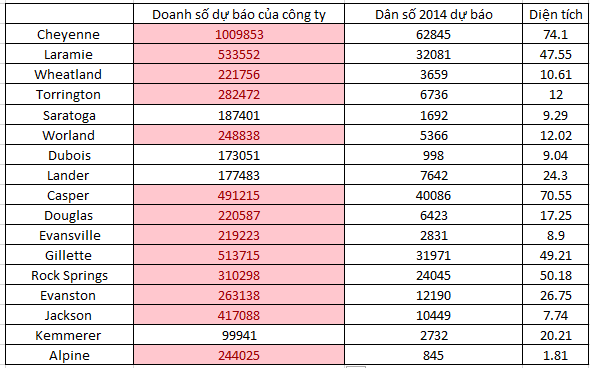
Chúng ta loại bỏ các thành phố Kemmerer, Dubois, Lander, Saratoga. Tuy nhiên do chúng ta kết luận bộ dữ liệu không phù hợp để phân tích nên kết quả trên vẫn chưa tin tưởng hoàn toàn, phải áp dụng phương pháp đánh giá khác, không chỉ dựa trên kết quả kiểm định hay hệ số xác định mà thôi. Cụ thể thì trước khi kết thúc series về hồi quy chúng tôi sẽ trình bày.
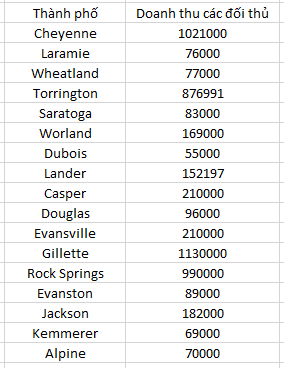
Tiếp theo chúng ta dự báo tổng doanh thu của các đối thủ cạnh tranh tại thành phố để chọn lựa tiếp. Chúng ta xem qua tập dữ liệu thứ 2, tương tự trước tiên chúng ta tìm hiểu qua ma trận hệ số tương quan để xem xét mối liên hệ giữa các biến
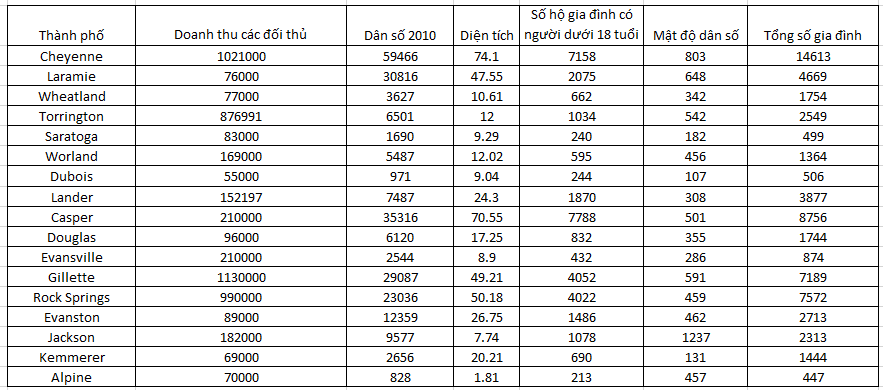
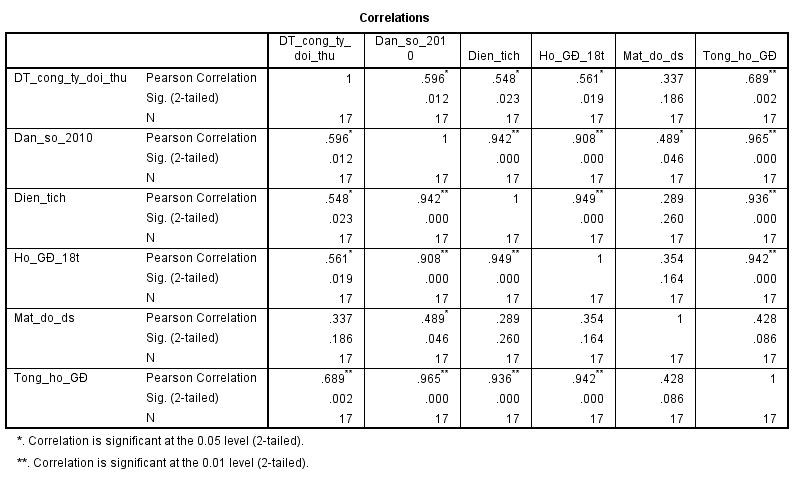
Khác với ở tập dữ liệu đầu, biến tổng doanh thu của các công ty đối thủ có mối tương quan với các biến còn lại, nhưng mối liên quan này không bền vững vì đa phần các hệ số tương quan đều không tiến gần đến 1 hay -1. Chúng ta xét tiếp p-value của giá trị kiểm định hệ số tương quan thì chỉ có biến dân số 2010, biến diện tích, biến tổng hộ gia đình, biến số hộ gia đình có người dưới 18t.
Tiếp tục xét đến vấn đề đa cộng tuyến thì các biến độc lập đều có mối quan hệ tương quan với nhau, chúng ta không thể loại bỏ hết, thì sẽ không còn gì để phân tích. Do vấn đề đa cộng tuyến sẽ tác động tiêu cực đến giá trị của kết quả dự báo nhưng tác động tiêu cực ra sao chúng ta còn nhiều phương pháp đánh giá khác mà chúng tôi sẽ đề cập ở các bài viết khác. Nguyên nhân các biến độc lập tương quan với nhau thì có lẽ không cần giải thích với các bạn.
Trên cơ sở hướng đến việc nghiên cứu sự biến động doanh thu của công ty hay tổng doanh thu của các đối thủ nếu các biến độc lập như diện tích, dân số,… thay đổi hay nói cách khác xu hướng tiêu dùng có khác biệt giữa các thành phố hay không thì rất cần xét các đặc trưng giữa từng thành phố.
Chúng ta sẽ sử dụng phương pháp Stepwise để xem biến nào cần đưa vào mô hình.
Qua phương pháp stepwise, chúng ta chỉ còn duy nhất một biến là cần thiết đưa vào mô hình đó chính là tổng hộ gia đình.

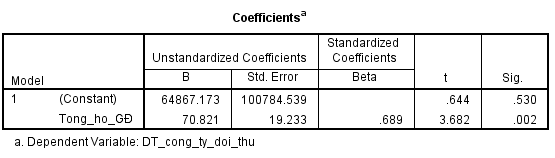
Quay lại ma trận hệ số tương quan thì biến tổng hộ gia đình có hệ số tương quan cao nhất nên để loại bỏ vấn đề đa cộng tuyến, chúng ta chỉ còn giữ lại một biến mà thôi. Kiểm định t cho hệ số hồi quy ới giá trị p-value cột sig < 0.05, tổng hộ gia định có mối quan hệ tương quan với biến mục tiêu, chúng ta sẽ có phương trình dự báo sau:
Y = 64867.173 + 70.8*Tổng hộ GĐ
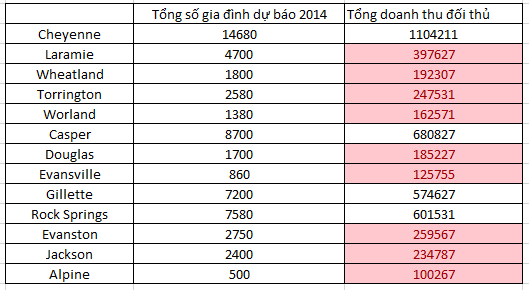
Chúng ta sẽ loại bỏ các thành phố mà tổng doanh thu đối thủ cao hơn 500000 USD. Như vậy còn các thành phố Laramie, Wheatland, Torrington, Worland, Douglas, Evansville, Evantson, Jackson, Alpine.
Tuy nhiên các bạn có thể thấy sự bất hợp lý trong kết quả ở trên ví dụ ở thành phố Laramie tổng số hộ gia đình năm 2010 là 4669 thì tổng doanh thu của đối thủ chỉ là 76000 $, có 1 cửa hàng đối thủ duy nhất. Nhung vào năm 2014 dự báo tổng số gia đình sẽ là 4700, tăng rất ít, nhưng tổng doanh thu của các đối thủ dự báo là 397627 $ cao hơn rất nhiều. Nếu chúng ta thay 4669 vào phương trình thì được 395432$. Hoàn toàn chênh lệch rất nhiều so với 76000 $.
- Tuy nhiên nếu xét trong hiện tại thì thành phố Laramie là thích hợp nhất, doanh số dự báo năm 2014 là cao nhất 533552$ nếu công ty mở cửa hàng bán lẻ tại đây, thành phố này có dân số trên 30000, và chỉ có 1 đối thủ cạnh tranh là Muddy Paws Pet Salon với doanh thu chỉ có 76000$.
Kết luận sau cùng bộ dữ liệu mà vị giám đốc yêu cầu bộ phận IT đưa cho bộ phận kế hoạch phân tích là hoàn toàn không phù hợp. Phải có thêm nhiều thông tin khác như về giá bán, xu hướng tiêu dùng theo thời kỳ, số lượng thú cưng trong mỗi thành phố, thu nhập trung bình của người dân, sản phẩm cụ thể của đối thủ,…
Trong bài viết này các bạn cũng nhận thấy đôi khi hệ số R2, phương pháp kiểm định không đánh giá hoàn toàn đúng về độ hiệu quả của mô hình, khi chúng ta thấy kết quả dự báo quá bất hợp lý. Về các phương pháp chuyên sâu hơn trong việc đánh giá độ chính xác của mọi mô hình hồi quy trong việc dự báo giá trị của biến mục tiêu sẽ được chúng tôi trình bày ở phần cuối cùng trong series Regression. Còn bài viết sắp tới chúng ta sẽ tìm hiểu về hồi quy Logistic, một mô hình hồi quy phổ biến không kém gì tuyến tính.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.