
 English
EnglishTrở lại với chủ đề Clustering, ở các bài viết trước, BigDataUni và các bạn đã cùng tìm hiểu tổng quan về phân tích phân cụm là gì, mục đích, lợi ích, các dạng phân cụm chính, đi qua các ví dụ triển khai thuật toán Hierarchical, và K-means clustering, sau cùng là sơ lược về mô hình RFM.
Trong bài viết lần này, chúng ta sẽ đi vào ví dụ triển khai thuật toán K-means clustering với cộng cụ RFM (Recency – Frequency – Monetary) hỗ trợ phân khúc khách hàng tối ưu thúc đẩy các hoạt động marketing, sales hiệu quả.
Link các bài viết dành cho những bạn chưa tham khảo các bài viết trước
Tìm hiểu về phương pháp Clustering (phân cụm) (P.1)
Tìm hiểu về phương pháp Clustering (P.2): Hierarchical clustering đơn giản
K-means Clustering và mô hình RFM (P.1)
Lý thuyết về RFM chúng tôi không nhắc lại trong bài viết này, cũng như K-means clustering. Các bạn xem lại các bài viết trước, link ở trên.
Một công ty thương mại điện tử tại Mỹ thu thập dữ liệu giao dịch lịch sử của các khách hàng thân thiết trên kênh bán hàng trực tuyến từ 1/1/2011 đến 31/12/2014 (ngày thu thập dữ liệu) để đánh giá, phân tích tiềm năng lợi nhuận của những khách hàng này bao gồm dự báo các khách hàng có thể tiếp tục quay lại giao dịch trong tương lai hay các khách hàng có nguy cơ rời bỏ công ty.
Dữ liệu cần được xử lý và chọn lọc các biến thuộc yếu tố Recency, Frequency, Monetary
+ Recency: lượng thời gian kể từ giao dịch, tương tác gần đây nhất của khách hàng thường tính bằng ngày (vẫn có các công ty tính theo tuần, tháng)
+ Frequency: tần số là tổng số giao dịch của khách hàng (trong một khoảng thời gian xác định).
+ Monetary: tổng số tiền mà khách hàng đã chi tiêu qua tất cả các giao dịch (trong một khoảng thời gian xác định).
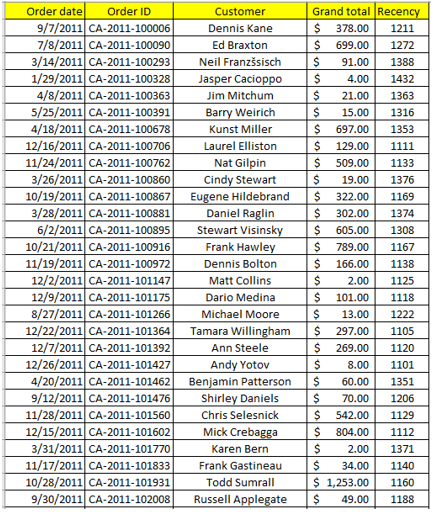
Mẫu dữ liệu giao dịch lịch sử trên kênh trực tuyến:

Dữ liệu bao gồm 4 biến, tổng cộng có 5009 quan sát, tức có 5009 giao dịch. Các bạn có thể tải data mẫu tại đây: link
- Order ID: Mã đơn đặt hàng
- Order Date: Ngày đặt hàng
- Customer: Tên khách hàng
- Grand total: Tổng giá trị đơn hàng
Sử dụng Excel đơn giản, chúng ta có thể tính khoảng thời gian từ ngày thu thập dữ liệu (31/12/2014) đến ngày gần nhất khách hàng đặt hàng để tìm Recency sau đó sắp xếp dữ liệu theo khách hàng để xác định Frequency cũng như tính tổng giá trị tiền khách hàng đem lại Monetary.
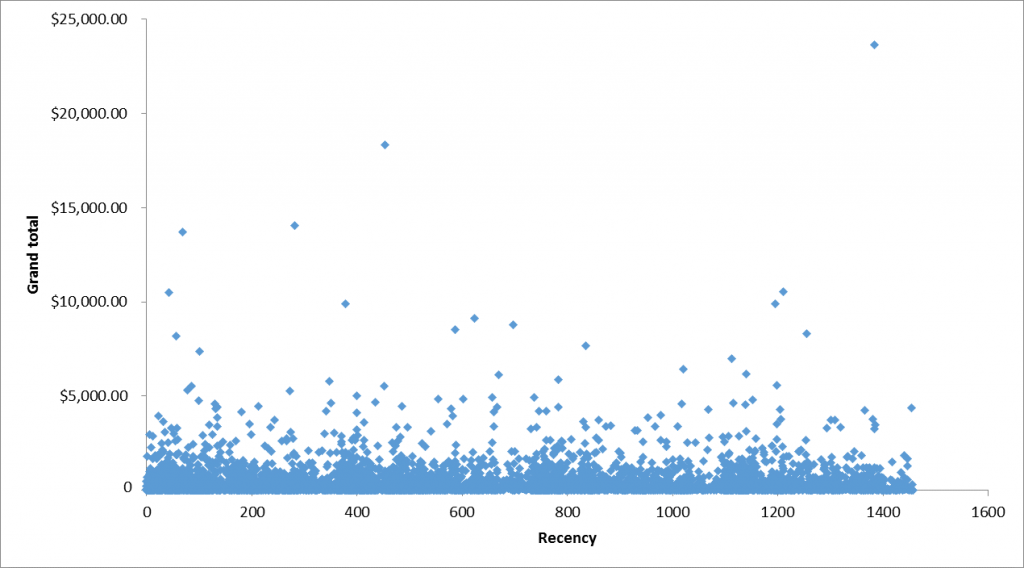
Nhìn trên biểu đồ Scatter plot chúng ta có thể thấy yếu tố Recency không có mối quan hệ, không có tác động rõ ràng lên Grand total giá trị đơn hàng (P-value cho kiểm định hệ số hồi quy β > 0.05). Trong thực tế, vì công ty trong ví dụ này là công ty bán lẻ có kênh thương mại điện tử nên có nhiều ngành hàng khác nhau từ FMCG (nhóm hàng tiêu dùng nhanh) đến điện tử, gia dụng và với nhiều mức giá khác nhau, khách hàng sẽ tùy vào nhu cầu của mình để mua hàng, và nhu cầu phát sinh là khác nhau giữa các thời điểm và khác nhau giữa các khách hàng. Không thấy bất kỳ xu hướng nào rõ rệt, nên khẳng định từ 2011 đến 2014 các hoạt động kinh doanh của công ty diễn ra bình thường, không có sự biến động trong doanh thu.
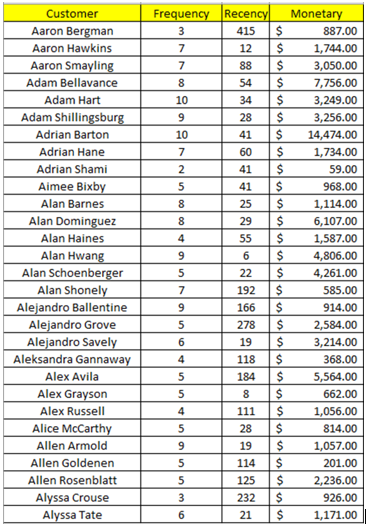
Tiếp theo chúng ta sắp xếp dữ liệu theo tên khách hàng để xác định giá trị Recency nhỏ nhất để đánh giá chung cho khách hàng, do khi tính Recency trong mô hình RFM và trong thực tế chúng ta quan tâm đến lần gần nhất khách hàng tương tác với các dịch vụ, hay giao dịch các sản phẩm của công ty, Recency càng thấp là dấu hiệu cho thấy khả năng khách hàng có thể quay lại mua hàng là cao. Ví dụ như dưới đây, Aaron Bergman có tổng cộng 3 giao dịch từ 2011 đến 2013, gần nhất là ngày 11/11/2013, từ đến 31/12/2014 là 415 ngày, nhỏ nhất, tương tự Aaron Hawkins là 12 ngày, Aaron Smayling là 88 ngày và Adam Bellavance là 54 ngày.

Nếu chỉ nhìn vô số các giao dịch và Recency thì có thể thấy khả năng Aaron Hawkins quay lại mua hàng trong tương lai là khá cao, và có thể khách hàng này sẽ trung thành với công ty, khi thấy rằng từ 2011 đến 2014 năm nào khách hàng cũng có giao dịch với công ty. Còn Aaron German là 415 ngày, và trong năm 2014 thì không có bất kỳ giao dịch nào vậy khả năng khách hàng này đã rời bỏ công ty là cao. Lý do chúng tôi phân tích trước một chút về Recency và tần suất mua hàng sắp nói dưới đây mục đích để các bạn thấy được tầm quan trọng của thời điểm khách hàng giao dịch.
Tiếp theo chúng ta sẽ tính tổng số lần giao dịch, và tổng doanh thu mà từng khách hàng mang lại cho công ty
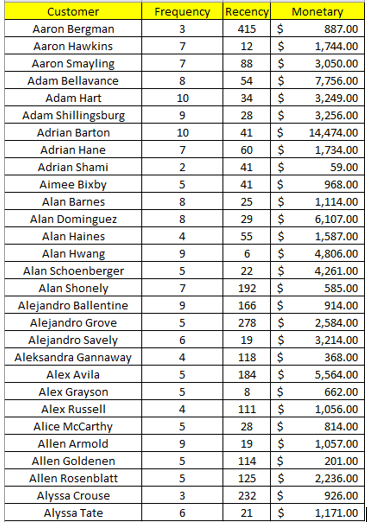
Các bạn xem ở bảng trên có thể thấy ví dụ Aaron Bergman có 3 giao dịch, tần suất sẽ bằng 3, tổng số tiền giao dịch là 887 USD. Công thức tính khá đơn giản.
Như vậy sau khi tính tổng theo từng khách hàng thì nhìn lại bảng dữ liệu các bạn có thể thấy có tất cả 793 khách hàng, mỗi khách hàng sẽ có các giá trị Recency, Frequency, Monetary tương ứng.
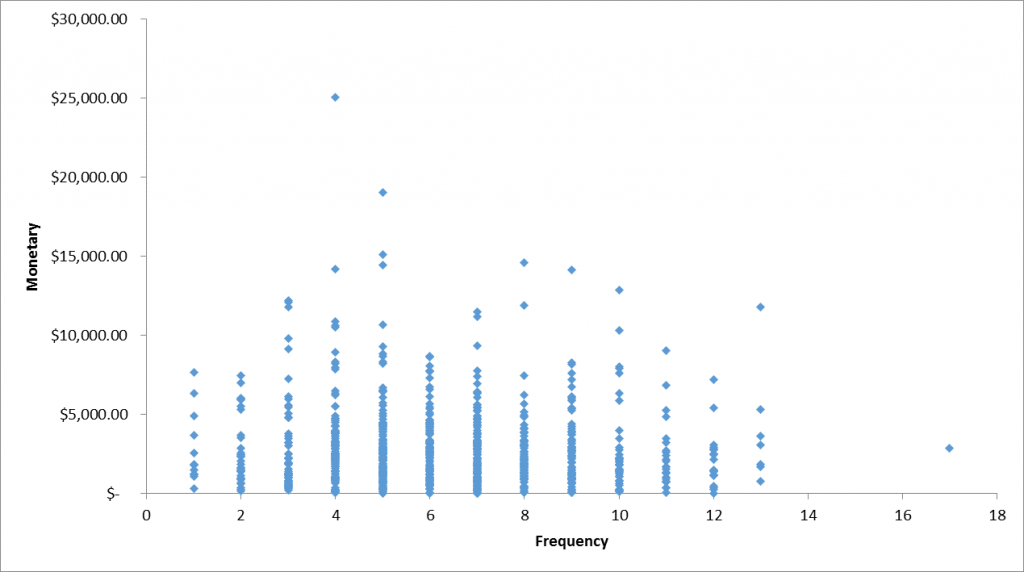
Số lần giao dịch từ 2011 đến 2014 của các khách hàng không tác động đến tổng số tiền khách hàng đem lại cho công ty trong ví dụ này (P-value cho kiểm định hệ số hồi quy β > 0.05). Nhìn trên biểu đồ các bạn có thể thấy tổng số lần giao dịch tăng thì tổng số tiền một khách hàng mang lại có thể không tăng. Ví dụ những khách hàng có số lần giao dịch là 12, có giá trị giao dịch trung bình nhỏ hơn những khách hàng chỉ có 5 lần giao dịch. Điều này trong thực tế cũng dễ hiểu, có thể khách hàng dồn mua hàng một lần trong năm, hoặc phân nhỏ chi tiêu cho nhiều lần mua hàng khác nhau trong năm. Giả thiết khác nếu mua nhiều lần thì sản phẩm mua có thể là hàng tiêu dùng nhanh hoặc hàng điện tử giá trị thấp và ngược lại.
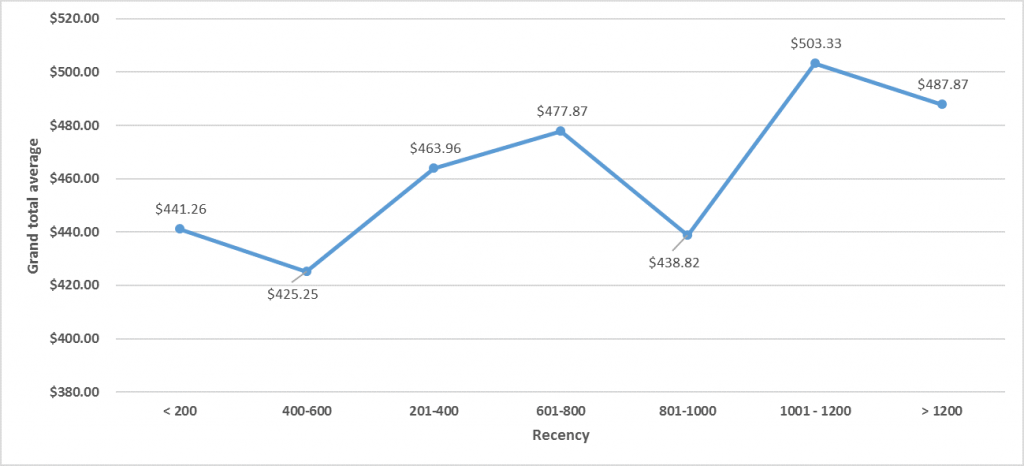
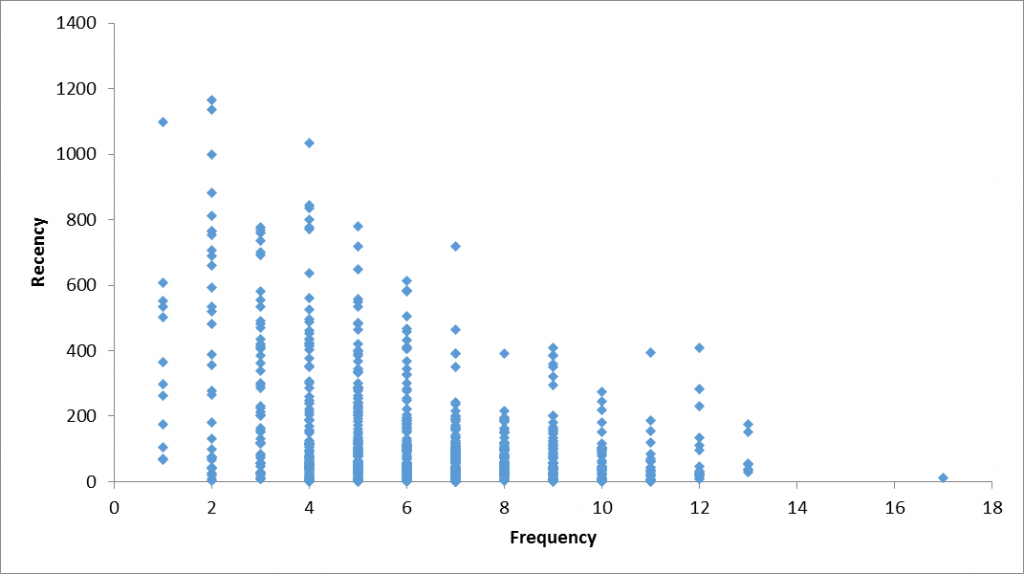
Về mối quan hệ giữa số lần giao dịch và lần giao dịch gần nhất, thì có thể thấy khi tổng số lần giao dịch tăng thì khoảng cách giữa lần giao dịch cuối cùng đến thời điểm nghiên cứu là giảm, nghĩa là khách hàng nào mua hàng nhiều lần thì có thể lần mua hàng cuối cùng sẽ gần với thời điểm nghiên cứu, càng gần 31/12/2014. P-value kiểm định cho hệ số hồi quy nhỏ hơn rất nhiều so với 0.05 theo quy ước của hồi quy tuyến tính, các bạn có thể tính thử.
Nhìn vào biểu đồ phía dưới đây
Bước tiếp theo là sắp xếp từng giá trị theo thứ tự từ nhỏ đến lớn hoặc từ lớn đến nhỏ dần tại từng biến này, chia tập dữ liệu theo ngũ phân vị (Quintiles) hoặc 5 phần không bằng nhau tùy vào giá trị Recency, Frequency, Monetary cũng như theo kinh nghiệm và các yêu cầu về kinh doanh. Rồi cho điểm mỗi phần từ 1-5 với 5 là tốt nhất, 1 là xấu nhất
Đầu tiên là Recency, phần dữ liệu thứ nhất có Recency cao nhất chúng ta sẽ cho điểm Recency = 1, thấp nhất, do khi Recency cao, nghĩa là khách hàng có nguy cơ rời dịch vụ, tức mang dấu hiệu xấu. Lưu ý ở ví dụ này chúng tôi xem xét R score và RFM score càng cao thì càng tốt, các bạn cũng có thể quy ước ngược lại, tương tự như F và M, chỉ cần nhớ rõ các điểm thể hiện tính chất của khách hàng như thế nào để tiến hành phân khúc, tránh bị nhầm lẫn. Dưới đây là kết quả 10 khách hàng hàng có Recency score = 1, và 10 khách hàng có Recency score = 5, tránh bài viết quá dài chúng tôi không thể hiện kết quả Recency score 2, 3, 4 của các khách hàng còn lại.
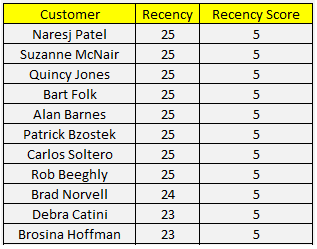
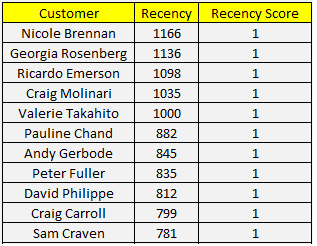
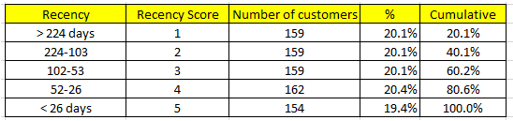
Sau khi chia tập dữ liệu và tiến hành gán điểm thì có thể thấy Recency có 5 khoảng giá trị để đánh giá khách hàng, những khách hàng nào khoảng thời gian từ lần cuối giao dịch tính đến 31/12/2014 trên 224 ngày thì có Recency score thấp nhất là 1, dưới 26 ngày cao nhất là 5.
Lưu ý quan trọng:
Việc chia tập dữ liệu không nhất thiết phải là tỷ lệ 20%, đỡ đau đầu hơn thì các bạn vẫn có thể sử dụng tỷ lệ 25% tức chia tập dữ liệu theo tứ phân vị (Quartile) sau đó gán điểm từ 1 – 4 để phân tích. Ngoài ra, chúng ta vẫn có thể tùy chỉnh các khoảng giá trị tại Recency, Frequency, Monetary theo các mục đích và yêu cầu kinh doanh, hay dựa trên kinh nghiệm để đánh giá khách hàng để gán điểm. Ví dụ công ty cho rằng khách hàng của mình có Recency < 30 ngày thì chắc chắn sẽ mua hàng tiếp trong tương lai, vậy < 30 days không phải 26 days, và điểm sẽ là 5. Lúc này khi các khoảng giá trị không dựa trên sự phân chia dữ liệu với tỷ lệ 20% thì các phần dữ liệu sẽ có số quan sát không bằng nhau.
Hơn nữa việc có sự thay đổi trong cách phân chia tập dữ liệu theo 5 phần bằng nhau (Quintiles) hoặc 5 phần không bằng nhau phụ thuộc vào chính những giá trị ở các biến Recency, Frequency, Monetary. Ví dụ ở trên, Recency tính theo ngày nên giữa khách hàng có sự khác biệt cao về giá trị Recency nên khi chia 5 phần bằng nhau theo ngũ phân vị sẽ dễ ngắt khoảng giá trị hơn. Còn như Frequency mà chúng ta thấy ngay dưới đây, chỉ có 14 giá trị là “unique” nên khi phân chia tập dữ liệu các phần sẽ không bằng nhau.
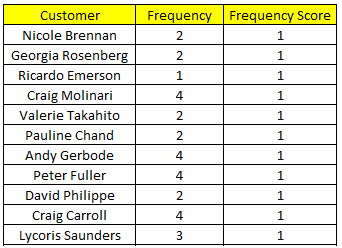
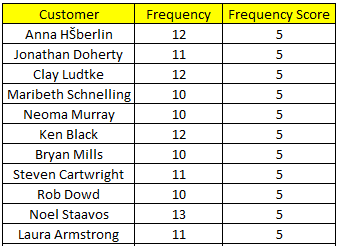
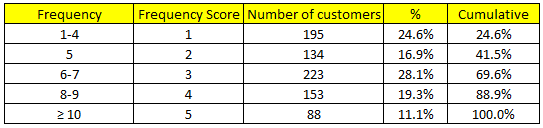
Các bạn có thể thấy 5 phần chia dựa trên Frequency có số quan sát hay số khách hàng đã chênh lệch khá nhiều. Do giá trị tại ngũ phân vị thứ nhất, giá trị Frequency tại ví trí 159 (159/793 = 20%) là bằng 4 mà từ khách hàng từ vị trí 160 trở lên đến vị trí 195 (195/793 = 24.6%) vẫn có Frequency = 4. Nhắc lại các giá trị tại Frequency phải được sắp xếp từ nhỏ đến lớn.
Như vậy số khách hàng có Frequency từ 6-7, tức từ năm 2011 đến 2014 mua hàng 6-7 lần, sẽ được gán điểm là 3, chiếm tỷ trọng cao nhất 28.1%.
Sau cùng chúng ta tính điểm Monetary Score cho từng khách hàng.
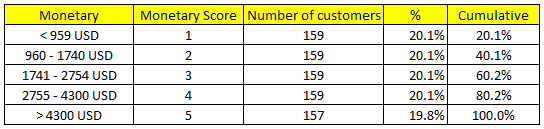
Tương tự như Recency, ở Monetary giá trị khác biệt rất nhiều, nên tập dữ liệu chia thành 5 phần bằng nhau. Các khách hàng có tổng số tiền giao dịch < 959 USD sẽ gán điểm là 1 thấp nhất, > 4300 USD sẽ gán điểm là 5 cao nhất.
Như vậy chúng ta đã gán xong điểm R, F, M. Bước sau cùng là phân khúc khách hàng dựa trên quy ước RFM score kết hợp. 5x5x5, chúng ta sẽ có 125 RFM score khác nhau.
Dưới đây là mẫu 15 khách hàng
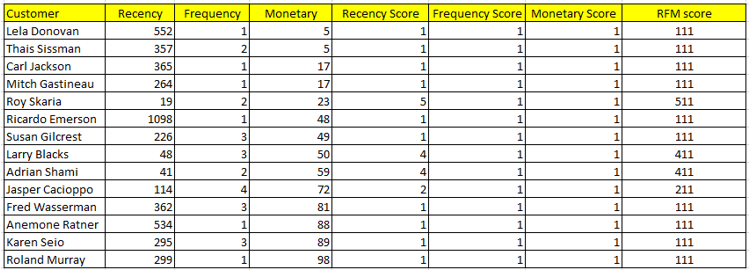
Theo như tập dữ liệu sau khi tính RFM score sẽ có tổng cộng 112 RFM score khách nhau.
Ở đây chúng tôi tạm phân khúc dựa theo kinh nghiệm của mình, các bạn có thể tham khảo:
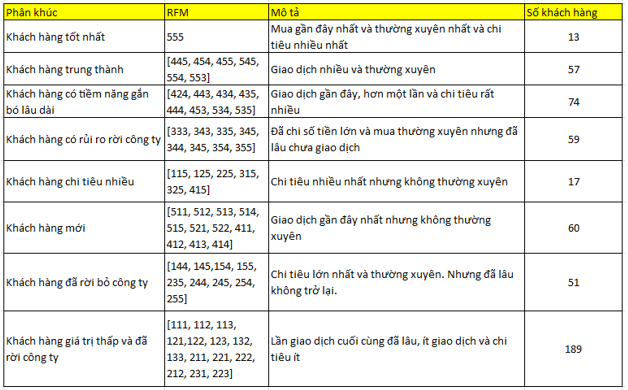
Tổng cộng 520 khách hàng đã được phân khúc, còn 273 khách hàng còn lại các bạn có thể thử tự phân khúc dựa trên nhận định của mình.
Thông tin 13 khách hàng tốt nhất mà công ty hiện có, tỷ lệ là khá thấp.
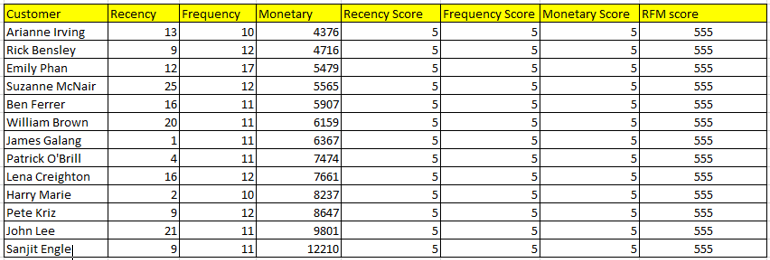
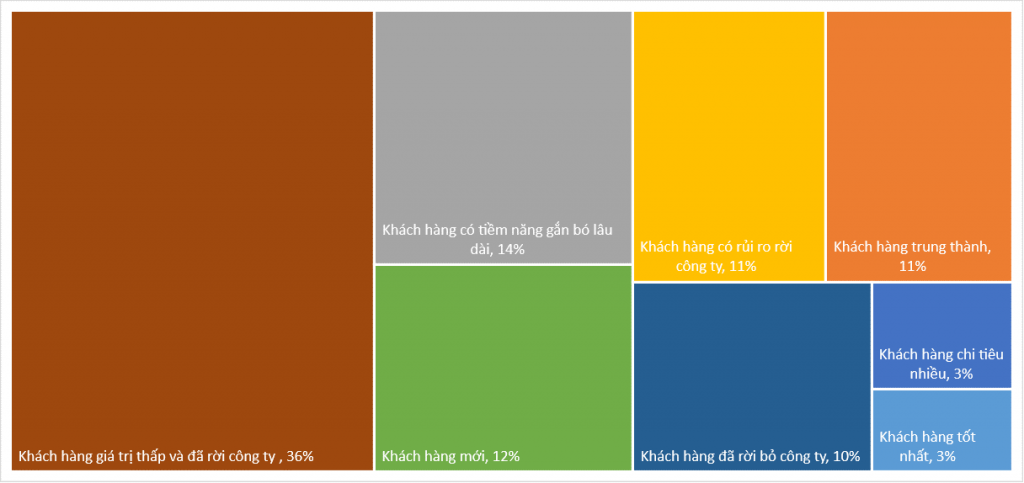
Nhiệm vụ của công ty lúc này là tìm ra giải pháp để giữ chân các khách hàng tốt nhất của mình thông qua các dịch vụ premium hơn, thu hút khách hàng mới giao dịch nhiều hơn trong tương lai bằng cách giới thiệu những sản phẩm khác có thể cross-selling hay up-selling, tương tự các khách hàng chi tiêu nhiều. Đối với những khách hàng có tiềm năng gắn bó lâu dài và khách hàng trung thành thì xây dựng thêm các chương trình khách hàng thân thiết. Đặc biệt cần quan tâm đến khách hàng có rủi ro rời bỏ công ty, cần cung cấp thêm các dịch vụ CSKH tốt hơn, các chương trình khuyến mãi nhắm mục tiêu.
Nói chung, đến giai đoạn này công ty có thể khá đau đầu khi phải suy nghĩ giải pháp hành động cho từng phân khúc khách hàng nhưng nếu thành công thì đảm bảo tăng được lợi nhuận lâu dài. Các bạn có thể suy nghĩ thêm các cách tiếp cận khác trong thực tế lỡ đâu có cơ hội vận dụng mô hình RFM trong tương lai.
K-means Clustering với RFM model
Chắc nhiều bạn sẽ thấy mâu thuẫn sao chủ đề bài viết về clustering mà nói nhiều đến cách thực hiện mô hình RFM đến thế, thực chất cho dù triển khai phân cụm K-means clustering cho dữ liệu RFM thì chúng ta cũng phải xử lý dữ liệu giống như các bước đầu ở trên, chỉ khác biệt là ở K-means clustering chúng ta không còn gán điểm số cho R, F, M, rồi phân khúc theo RFM score.
Ở K-means clustering chúng ta sẽ phân khúc khách hàng theo cách thức phân cụm mà ở đó trong mỗi cụm các khách hàng sẽ tương đồng về giá trị Recency, Frequency, Monetary.
Sau khi chúng ta tính được các giá trị Recency, Frequency, Monetary giống như ở trên. Ở đây phức tạp hơn chúng ta phải chuẩn hóa dữ liệu trước khi tiến hành phân cụm, nhưng trong bài viết này cho nhanh chóng chúng tôi bỏ qua bước này. Trong thực tế các bạn nhớ lưu ý điểm này.
Về cách vận hành K-means clustering các bạn có thể xem lại phần 1 bài viết, link ở phía trên đầu. Ở đây chúng tôi sử dụng công cụ SPSS modeler của IBM để xác định nhanh các cluster cần tìm.
Đối với ví dụ này, chúng tôi chọn k = 5, theo mặc định của SPSS modeler, tức cần tìm 5 cluster. Nếu các bạn nào đã biết về K-means clustering trước đó có thể biết đến phương pháp Elbow trong việc chọn k sao cho tối ưu. Trong bài viết lần này chúng tôi chưa đề cập đến phương pháp này cũng như các cách đánh giá độ hiệu quả của các cluster tìm được, mà sẽ dời sang bài viết cuối sắp tới của chủ đề clustering. Mong các bạn thông cảm!

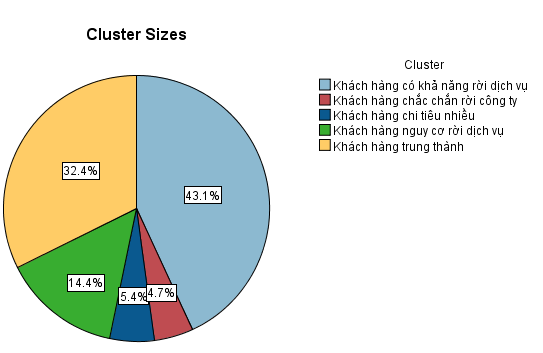
Trên là kết quả phân cụm cũng như phân tích của chúng tôi cho từng cụm khách hàng tìm được. Khác với cách thức gán điểm số, ở đây chúng ta tìm thấy được giá trị trung bình của Recency, Frequency, Monetary ứng với mỗi cluster.
Bước sau cùng cũng vậy, công ty sẽ có nhiệm vụ tìm giải pháp cho từng cụm khách hàng tìm được. K-means clustering cho phép xác định các nhóm khách hàng có điểm giống nhau trong hành vi mua sắm ở thực tế, và điểm giống nhau được xác định bằng các phương pháp định lượng cụ thể. Khác với việc gán điểm RFM score, mặc dù có nhiều phân khúc chi tiết hơn nhưng mức độ chặt chẽ trong việc tìm ra sự tương đồng của các khách hàng có trong một phân khúc là chưa cao do chỉ xét trên các khoảng giá trị để cho điểm.
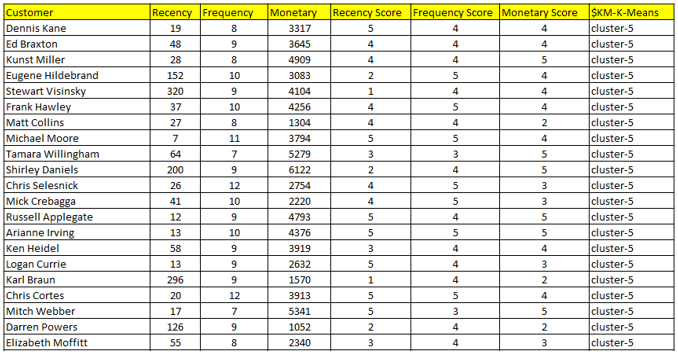
Cluster-5 – Khách hàng trung thành hay được coi khách hàng tốt nhất. Bên trên là mẫu thông tin của một vài khách hàng tốt nhất công ty có.
Cách khác
Bên cạnh việc dùng giá trị thực của Recency, Frequency, Monetary, chúng ta cũng có thể sử dụng giá trị điểm, score của Recency, Frequency, Monetary để thực hiện. Như vậy sẽ tìm được 5 cụm cluster mà ở đó xác định được score trung bình của R, F, M trong mỗi cluster, rồi rút ra đặc điểm mỗi cluster và tìm giải pháp. Cách này khắc phục khuyết điểm phân khúc theo RFM score vừa nói ở trên.

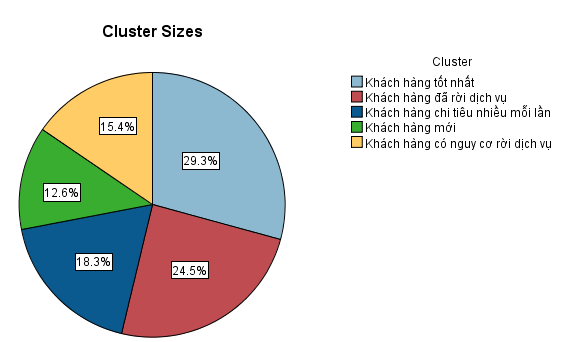
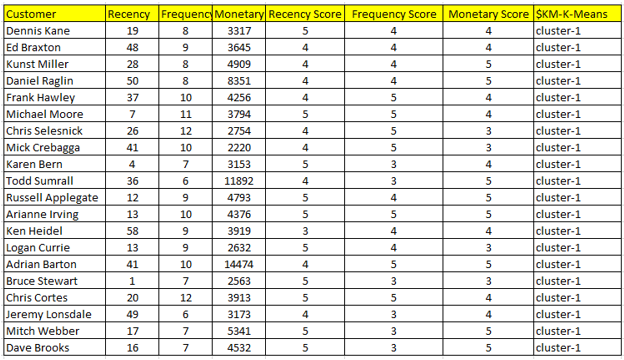
Cluster 1 – khách hàng tốt nhất, bên trên là mẫu thông tin của một vài khách hàng tốt nhất theo cách 2 này.
Như vậy đến đây là kết thúc bài viết lần này hẹn các bạn ở những bài viết khác.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.