
 English
EnglishQuay trở lại với series bài viết mới về các thuật toán Data mining. Ở những bài viết trước chúng ta đã cùng nhau tìm hiểu về thuật toán clustering quan trọng trong phân tích dữ liệu. Đến với chủ đề mới lần này, BigDataUni và các bạn tiếp tục làm quen với một phương pháp, kỹ thuật khai phá dữ liệu mới, được gọi là Association Rules – luật kết hợp. Nếu bạn nào đang tìm hiểu về lĩnh vực Data science thì chắc đã học qua hay nghe đến phương pháp này. Association Rules không chỉ là phương pháp phân tích nền tảng trong kiến thức khai phá dữ liệu mà nó còn nổi tiếng vì là công cụ hỗ trợ các hoạt động sales và marketing trong lĩnh vực bán lẻ, thương mại điện tử – E-commerce từ trước đến nay.
Trong bài viết phần 1, chúng ta sẽ tập trung tìm hiểu phương pháp Association rules là gì, công thức toán áp dụng bên trong, ứng dụng và mục đích triển khai Association rules trong thực thế. Bài viết phần 2 chúng ta sẽ đi vào thuật toán khai phá luật kết hợp quan trọng có tên Apriori và các ví dụ cụ thể để thực hiện phân tích Association rules cơ bản.

Association Rules là gì? Mục đích sử dụng?
Đứng ở góc độ là một khách hàng mua sắm, khi chúng ta đến siêu thị chắc hẳn đã chuẩn bị cho mình trước một list hay danh sách những thứ mình cần mua dựa trên các nhu cầu thiết yếu, sở thích, mục đích riêng,…Các trung tâm thương mại thì khác với siêu thị, khách hàng có xu hướng tham quan hơn. Còn kênh bán hàng online, kênh thương mại điện tử, đa phần do phát sinh đột ngột, hay mục đích mua hàng có thể đã có từ trước như chưa đủ khả năng, nhưng khách hàng vẫn có thể truy cập ngay lập tức vào website để tra cứu sản phẩm mình cần sau đó nếu cần mua sẽ tiến hành giao dịch, quá trình mua hàng cứ tiếp tục nếu nhận thấy có sự quan tâm đối với các sản phẩm khác, mà không cần tạo list như đi siêu thị, cũng có thể do lâu lâu mới đi như dịch bệnh Covid bùng phát thì hạn chế hẳn.
=> thông thường, mọi khách hàng đều có nhu cầu shopping nào đó (có thể rõ, cụ thể hay chỉ mập mờ, chưa hình thành nhưng có sự quan tâm) khi ghé thăm bất kể cửa hàng từ online đến offline (hay brick-and-mortar, cửa hàng truyền thống) và sản phẩm có thể từ một trở lên
Một bà nội trợ đến siêu thị có thể mua thứ nhất: thực phẩm chuẩn bị cho các bữa ăn trong ngày, thực phẩm để dự trữ tiêu thụ lâu dài, các nhu yếu phẩm khác cho gia đình như đồ dùng trong nhà tắm và các đồ dùng sinh hoạt chung khác. Một phụ nữ trẻ vào trung tâm thương mại để mua mỹ phẩm, thời trang. Một thanh niên trẻ vào trung tâm thương mại có thể mua đồ ăn liền hay các sản phẩm cho nam giới, và các sản phẩm công nghệ.
=> nhu cầu, sở thích mua sắm sẽ khác nhau giữa các nhóm khách hàng khác nhau. Xác định các nhóm khách hàng với nhũng đặc điểm nhân khẩu học cụ thể làm cơ sở để dự báo được loại sản phẩm phù hợp.
Đứng ở góc độ là một nhà quản lý cửa hàng, nhân viên bán hàng có thể sẽ quan tâm một khách hàng nữ/ nam, trẻ/ lớn tuổi,… đến cửa hàng sẽ mua những gì? tiếp đến sau khi đã có thứ mình cần, họ có mua thêm sản phẩm khác hay không nếu họ có list sẵn những gì cần mua hay chưa có, hoặc có thể nhận thấy cần thiết tại thời điểm mua hàng? Và việc phát sinh nhu cầu mới, sản phẩm mới có liên kết gì so với nhu cầu ban đầu khi mới bước vào cửa hàng?
Để phân khúc khách hàng theo nhân khẩu học hay hành vi mua sắm thì chúng ta đã có phương pháp clustering kết hợp mô hình RFM và hỗ trợ marketing, bán hàng cho những dòng sản phẩm phù hợp với nhu cầu, sở thích của khách hàng tuy nhiên để dự báo liệu khách hàng có mua thêm sản phẩm nào khác để công ty có thể giới thiệu thêm các sản phẩm khác hay không, dựa trên việc khai phá “luật kết hợp” trong những sản phẩm khách hàng có thể mua.
Và công cụ để tìm ra chính là dựa vào Association Rules.
Nhiều bạn sẽ thắc mắc tại sao chúng tôi lại giải thích dài dòng như vậy trong khi có thể nói thẳng đoạn vừa trên về mục đích cần Association Rules. Lý do chúng tôi muốn các bạn hiểu Association Rules ở cả 2 phương diện: là khách hàng, là quản lý, nhân viên bán hàng, như vậy khi đến với các nội dung sau các bạn sẽ dễ nắm bắt hơn.
Ví dụ một phụ nữ đến siêu thị mua cho mình dầu gội đầu có thể sẽ mua thêm dầu xả, dầu dưỡng tóc, hay phụ kiện như mũ gội đầu, khăn trùm tóc. Một bà nội trợ sau khi mua nước mắm có thể mua thêm cái gia vị khác nếu cần như mua bột nêm, bột ngọt. Hay một người mua máy ảnh Canon có thể sẽ mua thêm thẻ nhớ, túi đựng máy ảnh. Như khuyến nghị “Frequently Bought Together” của Amazon trong hình dưới đây.
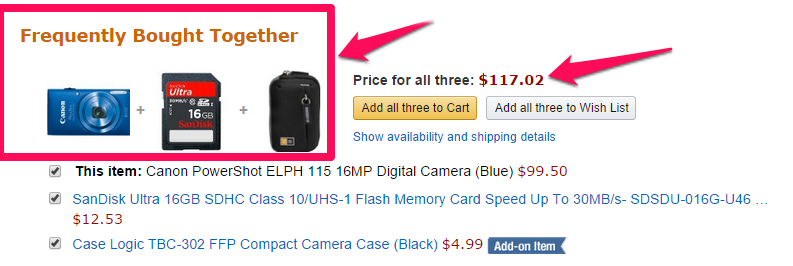
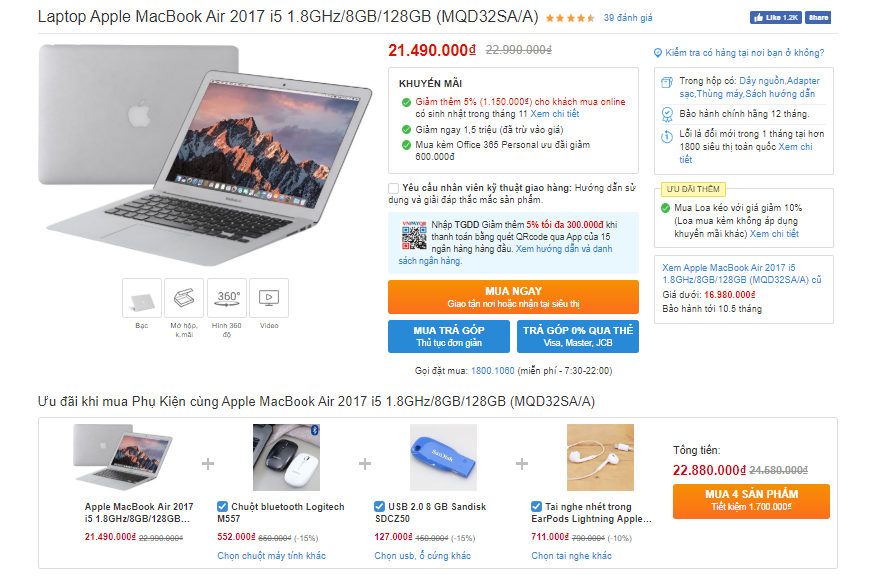
Hay Tiki giới thiệu các sản phẩm phụ kiện đi kèm cho khách hàng khi mua một chiếc macbook.
Những ví dụ chúng tôi nói ở trên khá là phổ biến, và gắn liền với thuật ngữ “Cross-selling” (bán chéo các sản phẩm khác). Quy luật cross-selling các công ty có thể đoán biết dựa trên việc kết hợp các đặc tính của sản phẩm. Giả sử người dùng laptop có thể không quen sử dụng touchpad thì phải mua mouse.
Tuy nhiên, các công ty muốn nhiều hơn thế, họ muốn tìm hiểu liệu “có một quy luật nào đó” dẫn đến việc “nếu” các khách hàng mua sản phẩm A “thì” sẽ mua sản phẩm B nào đó mà trong thực thế công ty không lường trước được, phải dùng đến phân tích dữ liệu.
Ví dụ một thanh niên mua chai nước ngọt Coca-cola loại 1.5 lít nhưng thay vì mua thêm các sản phẩm nước giải khát khác sát bên thì lại mua kẹo Mentos. Chắc các bạn cũng biết phản ứng hóa họa giữa Coca-cola và Mentos từng là “Trend” hot ở các nước phương Tây. Phân tích dữ liệu giao dịch online của các khách hàng công ty nhận thấy bỗng nhiên có sự gia tăng mạnh trong việc đặt mua Coca-cola cỡ lớn với kẹo mentos. Do đó đưa ra chiến lược trong tháng sắp tới là marketing mentos cùng Coca-cola chung với nhau. Trên kênh bán hàng online có thể khuyến nghị song song, còn tại cửa hàng thì xếp kế bên như hình dưới đây.

Thật ra chúng tôi lấy ví dụ này để nói về Association Rules, trong thực tế trào lưu này quá hot, công ty không cần phải phân tích dữ liệu cũng biết được. Nhưng giả sử, lúc này là 10 năm trước, trend hay mạng xã hội còn quá mới mẻ, thì công ty không thể nào biết nếu không dùng Data mining.
Association rules là phương pháp khai phá các quy luật kết hợp hay liên kết tiềm ẩn, hay khả năng đi chung với nhau giữa các đối tượng trong dữ liệu, từ đó đưa ra những kết luận “Nếu…..Thì…..”. Và các kết luận phải được kiểm chứng về xác suất xảy ra, về độ tin cậy. như Nếu khách hàng mua Cocla-cola, thì 80% mua Mentos, độ tin cậy 90%.
Association rules còn được gọi là “Affinity analysis” với ý nghĩa tương tự và “Market Basket analysis” theo ứng dụng phổ biến, mà nổi tiếng nhất của nó chính là hỗ trợ các công ty tìm ra những nhóm các sản phẩm có thể kết hợp mà khách hàng sẽ mua.
Khi các công ty có dữ liệu lịch sử dồi dào về các sản phẩm khách hàng giao dịch, thì khai phá luật kết hợp giữa những sản phẩm sẽ mang về rất nhiều lợi ích to lớn.
Nói một chút về dữ liệu phù hợp áp dụng thì các thuật toán khai phá luật kết hợp sử dụng chủ yếu dữ liệu định tính – categorical data, có thể có biến định danh, biến thay phiên (binary) – kết hợp các phép đếm, tính xác suất đơn giản. Vì các sản phẩm khách hàng giao dịch được ghi nhận theo tên loại chứ không có số. Association Rules theo chúng tôi là các thuật toán dễ hiểu nhất trong Data mining, đơn giản, không quá phức tạp.
Association rules chúng ta chia làm 2 phần cần tìm: “Nếu” – IF – hay còn gọi Antecedent: điều kiện, tiền đề, cái gì đến trước, nguyên nhân và “Thì” – Then – hay còn gọi Consequent: kết quả, cái gì đến sau. 2 phần này sẽ hợp thành 1 quy luật.
Theo ví dụ ở trên thì Coca-cola chính là Antecedent, nằm ở mệnh đề Nếu, còn Mentos là Consequent nằm ở mệnh đề Thì.
Mặc dù sử dụng dữ liệu định tính, nhưng Association Rules vẫn có phương pháp để đánh giá các quy luật được khai phá, cụ thể qua 3 thông số Confidence (Độ tin cậy), Support (Độ ủng hộ) và hệ số Lift
Ví dụ:
- Cửa hàng bán lẻ thực phẩm có 100000 giao dịch.
- 2500 giao dịch có chứa sản phẩm kẹo Mentos (2.5%)
- 10000 giao dịch có chứa sản phẩm Coca-cola (10%)
- 1000 giao dịch có chứa cả Coca-cola và Mentos (1%)
Bộ dữ liệu mẫu có thể hình dung như sau:
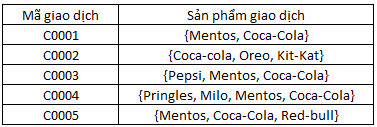
{Mentos} + {Coca-cola} => {Mentos, Coca-cola}
Giả sử luật kết hợp được tìm thấy “Nếu khách hàng mua kẹo Mentos, thì mua Coca-cola”, tỷ lệ Support = (1000/100000) = 1% và Confidence = (1000/2500) = 40%. Các bạn có thể thấy tỷ lệ khách hàng mua Coca-cola trong tổng số giao dịch là 10% nếu không quan tâm các yếu tố tác động, nhưng nếu trong số các khách hàng mua Mentos thì có tới 40% mua Coca-cola. Như vậy Mentos làm tăng tỷ lệ mua Coca-cola lên 4 lần. Đây chính là hệ số Lift.
Chúng tôi sẽ trình bày rõ hơn về 3 hệ số này ở phần sau.
Như vậy chúng ta đã hiểu Association Rules là gì, mục đích sử dụng, tiếp theo cùng điểm qua một số những ứng dụng của phương pháp trong thực tế.
Các ứng dụng phổ biến của Association Rules
Market Basket Analysis
Đây là ứng dụng chính của phân tích luật kết hợp, vì nó cho thấy lợi ích kinh doanh cao nhất trong top các thuật toán Data mining được sử dụng, và hầu như các nhà bán lẻ hay thương mại điện tử đều biết đến.
“Market Basket” là tên gọi của Database thu thập dữ liệu giao dịch thông qua quét mã Barcode sản phẩm bán tại các trung tâm thương mại, và tập dữ liệu thường rất lớn. Mỗi record có thể chứa các thông tin như list các sản phẩm được khách hàng mua, theo ID khách hàng cụ thể nếu khách hàng có thẻ thành viên, hoặc mã số giao dịch.
Những insight khai phá được chẳng hạn như Association Rules giúp ích rất nhiều trong việc gia tăng lợi nhuận dựa trên cải tiến các hoạt động marketing, sales

Ngày nay, khi hình thức mua sắm online gia tăng, hành vi tra cứu sản phẩm, và giao dịch sản phẩm của khách hàng trên nền tảng trực tuyến nhiều hơn tạo điều kiện cho nguồn dữ liệu đầu vào dồi dào hơn, và nhiều insight hơn được khai phá.
Lý do đơn giản, khách hàng phải đi qua gian hàng, kệ hàng này đến kệ hàng khác trong siêu thị để kiếm sản phẩm mình cần, và việc làm này có thể hạn chế nếu khách hàng không có nhiều thời gian và đơ giản là mỏi chân. Nhưng khi tra cứu trên cửa hàng trực tuyến khách hàng có thể mua nhiều sản phẩm khác nhau do có chỉ cần vài giây là tìm được sản phẩm mình cần.
Đối với các cửa hàng truyền thống, kết quả phân tích từ Association rules có thể giúp:
- Tối ưu việc trưng bày sản phẩm, hạn chế thời gian khách hàng phải bỏ ra để kiếm các sản phẩm mình cần trong một lúc, như ví dụ mentos bán chung với Coca-cola, có thể thực tế gian hàng bánh kẹo nằm xa gian hàng nước giải khác.
- Các chương trình khuyến mãi, giảm giá, hay bán theo combo ngay tại cửa hàng như khách hàng mua sản phẩm A, sẽ được giới thiệu sản phẩm B với giá thấp hơn khi mua chung – công ty dự báo khách hàng có thể mua thêm sản phẩm B khi đã mua sản phẩm A, nhờ vào Association Rules
- Tăng cường hoạt động cross-selling tốt hơn. Bên cạnh để khách hàng tự trải nghiệm mua sắm, các nhân viên bán hàng sẽ được cung cấp thông tin về một loạt những sản phẩm kết hợp, các đặc tính xung quanh tư vấn thêm cho khách hàng giả sử luật kết hợp cho thấy giá trị gia tăng thêm
Đối với website thương mại điện tử, cửa hàng trực tuyến thì:
- Hỗ trợ xây dựng hệ thống khuyến nghị – Recommendataion system – hiệu quả
- Marketing target nhiều đối tượng khách hàng chính xác hơn. Ví dụ khách hàng mua sản phẩm A có khả năng thích sản phẩm B và ngược lại. Công ty sẽ xây dựng nội dung marketing hết hợp A và B nhắm cả 2 phân khúc khách hàng mục tiêu thay vì đơn lẻ
Và sau cùng đối với nhà sản xuất họ có thể phát triển những ý tưởng mới kết hợp các sản phẩm lại với nhau như sản phẩm A có hương vị sản phẩm B bên trong. Chẳng hạn kẹo mentos có vị Cola được bán rất chạy.
Chuẩn đoán bệnh trong y tế
Association rules trong y học cũng được xem là thuật toán phân tích quan trọng vì nó có thể hỗ trợ các y bác sĩ trong quá trình khám, chữa bệnh.
Để chuẩn đoán một căn bệnh có thể phải dựa trên rất nhiều triệu chứng để đưa ra các kết luận ban đầu trước khi tiến tới các cuộc xét nghiệm chính thức. Những chuẩn đoán chính xác ban đầu có thể giảm thời gian khám chữa bệnh, cũng như chi phí một bệnh nhân bỏ ra cho các dịch vụ xét nghiệm. Tuy nhiên, nó có thể đem lại nhiều hậu quả khôn lường nếu các bác sĩ gặp sai sót.
Trong cơ thể con người chúng ta có hàng triệu tế bào, cơ quan, mạch máu và dây thần kinh, chỉ cần một nơi có vấn đề sẽ phát sinh đến nhiều căn bệnh khác nhau. Nhưng sẽ có các biểu hiện phổ biến, có sự liên kết với nhau có thể giúp bác sĩ tìm ra nguyên nhân căn bệnh và đưa ra chuẩn đoán.
Ví dụ “Nếu người bị vàng da, mắt vàng, thì có thể mắc các bệnh lý về gan” Ban đầu các nhà y học có thể chưa biết được lý do tại sao da vàng sẽ mắc bệnh gan, nhưng qua Association rules thấy một tỷ lệ khá cao trong Confidence: những bệnh nhân vàng da đa phần mắc bệnh gan sau này.
Nếu tỷ lệ Confidence không đạt 100%, thì có thể vàng da là triệu chứng của căn bệnh khác. Tuy nhiên khả năng cao vẫn mắc bệnh gan, và thay vì cho bệnh nhân thực hiện các xét nghiệm khác nhau, bác sĩ sẽ chỉ định xét nghiệm máu, hoặc các xét nghiệm về gan tương tự.
Association rules trong lĩnh vực y học mục đích hỗ trợ bác sĩ biết được xác suất xảy ra căn bệnh A bất kỳ khi liên kết đến hàng loạt các yếu tố, triệu chứng B, C,…Assocation rules còn cho phép các nhà nghiên cứu phát hiện ra các triệu chứng mới, căn bệnh mới.

Covid-19 có thể là ví dụ để áp dụng Association rules. Nhưng hiệu quả hay không hiện tại chúng ta vẫn chưa biết được. Trong đợt dịch thứ 2 vừa rồi, xuất hiện nhiều ca bệnh thậm chí không có triệu chứng rõ ràng.
Các chuyên gia nước ngoài thường nhắc đến triệu chứng sốt, ho kèm theo điều kiện là case đó từng đến vùng dịch, thì mới chỉ dừng lại ở mức nghi ngờ, cần rất nhiều cơ sở khác.
Ở nước ta, khí hậu thay đổi thất thường dẫn đến nhiều căn bệnh có triệu chứng sốt, ho nhưng có thể là cúm thông thường, hoặc có thể là Covid-19. Tuy nhiên với phương châm không bỏ sót những ai có nguy cơ nhiễm, Chính phủ thực hiện biện pháp cách ly hết, triệt để bất kể có từ vùng dịch về hay không, hoặc tiếp xúc với F1, F2, F3, F4.
Mặt tiêu cực, người dân dễ bị hoang mang. Họ ùa nhau đến bệnh viện để xét nghiệm dù chỉ mới bị ho sốt nhẹ mà quên rằng bộ kit xét nghiệm không phải dồi dào, ngay cả tâm dịch tại Đà Nẵng đang thiếu kit xét nghiệm hồi tháng 8.
Phân tích dữ liệu các trường hợp mắc nhiều hơn thì thấy rằng, sốt ho vẫn chưa phải là triệu chứng Covid -19 rõ rệt mà chính là triệu chứng ho khan, khó thở, và tức ngực.
Ví dụ có thể Confidence {ho khan, khó thở, và tức ngực => Covid – 19} > Confidence {sốt, ho => Covid-19}
Một số ứng dụng khác:
- Ứng dụng trong sinh học để phân tích chuỗi/ trình tự (Sequences) của Protein
Chuỗi Protein được tạo thành từ 20 loại axit amin. Mỗi protein mang một cấu trúc 3D riêng phụ thuộc vào trình tự của các axit amin này. Một sự thay đổi nhỏ trong trình tự có thể gây ra sự thay đổi trong cấu trúc dẫn đến biến đổi chức năng của protein. Sự phụ thuộc này của protein hoạt động dựa vào trình tự axit amin trước giờ luôn là một chủ đề chính trong các nghiên cứu lớn. Trước đây các chuyên gia cho rằng những chuỗi Protein là ngẫu nhiên, nhưng không phải vậy. Các nhà nghiên cứu Nitin Gupta, Nitin Mangal, Kamal Tiwari và Pabitra Mitra đã giải mã bản chất của mối liên hệ giữa các axit amin khác nhau có trong một loại protein. Những kiến thức và hiểu biết về các quy tắc liên kết dựa trên Association rules sẽ vô cùng hữu ích trong quá trình tổng hợp các protein nhân tạo.
- Phân tích dữ liệu điều tra dân số (Census data)
Chính phủ ở các nước đều có hàng tấn dữ liệu điều tra dân số. Dữ liệu này có thể được sử dụng để lập kế hoạch cho các dịch vụ công hiệu quả (giáo dục, y tế, giao thông) cũng như giúp các doanh nghiệp công (thiết lập nhà máy mới, trung tâm mua sắm và thậm chí tiếp thị các sản phẩm cụ thể). Ứng dụng Association Rules khai thác nguồn dữ liệu có tiềm năng to lớn trong việc hỗ trợ chính sách công đúng đắn và vận hành hiệu quả xã hội.
- Ứng dụng hỗ trợ hoạt động CRM trong công ty tài chính, tín dụng
Không chỉ áp dụng trong ngành bán lẻ, thương mại điện tử. Association rules có thể được ứng dụng trong ngành tài chính. Quản lý quan hệ khách hàng (CRM), thông qua đó, các ngân hàng có thể xác định sở thích của các nhóm khách hàng khác nhau, các sản phẩm và dịch vụ tài chính, tín dụng được điều chỉnh theo nhu cầu của khách hàng để tăng cường sự gắn kết giữa khách hàng và ngân hàng. Việc áp dụng Association rules củng cố quá trình đào tạo, cách thức vận hành và cho phép nhân viên bán hàng, marketing hiểu rõ khách hàng để cung cấp dịch vụ chất lượng tốt hơn theo hình thức Cross-selling hay Up-selling. Ví dụ, hiện tại đang có xu hướng Bancassurance, tức công ty bảo hiểm bán sản phẩm bảo hiểm tại chính các chi nhánh ngân hàng. Áp dụng Association rules phân tích có thể thấy xu hướng khách hàng có đăng ký dịch vụ gửi tiết kiệm thì sẽ đăng ký mua một sản phẩm bảo hiểm nào đó.
Confidence, Support & Lift trong Association Rules
Để hiểu Association rules cũng như các tiêu chí Confidence, Support & Lift chúng ta cùng đi qua ví dụ sau. Ví dụ được tham khảo từ tài liệu Data mining & Predictive analytics của tác giả Daniel T. Larose.

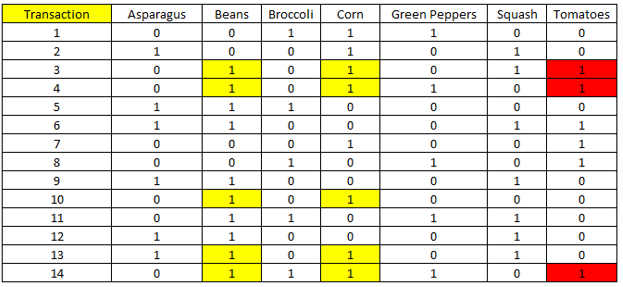
Bên trên là dữ liệu mẫu Market Basket của một công ty bán lẻ thực phẩm. Có 2 dạng bảng dữ liệu, bên trên là một dạng, dạng thứ hai được biểu diễn dưới hệ số coding 0 và 1 (kiểu biến flag) ứng với từng giao dịch, 0 tức giao dịch không chứa sản phẩm, 1 tức giao dịch có chứa sản phẩm.
Chuẩn bị dữ liệu cũng là một trong các bước quan trọng khi phân tích Association rules. Trong series bài viết đầu tiên chúng ta tạm thời quan tâm đến thực hiện trên dữ liệu định tính.

Dạng khác chính là biểu diễn dọc, tức bảng dữ liệu chỉ có 2 cột, 1 mã transaction, 1 là sản phẩm, và mỗi dòng chỉ liệt kê 1 sản phẩm duy nhất tương ứng theo transaction. Việc thiết lập nhiều loại bảng khác nhau chỉ hỗ trợ nhanh chóng quá trình đếm và liệt kê sản phẩm, tuy nhiên hiện nay có rất nhiều phần mềm phân tích tiên tiến khác nhau, thậm chí cả Excel cũng có thể phân tích Association rules đơn giản nên quá trình tạo bảng như thế nào có thể không phải vấn đề quá quan trọng
Sau khi chuẩn bị bảng dữ liệu, việc tiếp theo là liệt kê các kết hợp nếu có, hay tiến hành đếm tần số xuất hiện.
Gọi trên là tập dữ liệu D, với T = {T1, T2, T3,…TN} là tập các giao dịch có mã số, I = {I1, I2, I3… IN} là tập các sản phẩm đã bán. Với mỗi giao dịch Ti sẽ chứa một tập con các sản phẩm lấy ra từ tập I. Một tập hợp bao gồm giữa 0, 1 hoặc hơn 1 sản phẩm được gọi là “Itemset” – tập phần tử.
Nếu một itemset chứa k các phần tử có thể gọi k-itemset ví dụ 2-itemset thì itemset có chứa 2 phần tử. Theo phương pháp, chúng ta phải xác định Frequency từ 1-itemset cho từng sản phẩm, đến 5-itemset. Các bạn có thể tự làm để tìm các Association rules, bài viết có giới hạn nên chúng tôi không trình bày cụ thể.
Công việc tiếp theo là đếm tần suất xuất hiện các itemset cụ thể trong tập dữ liệu để tính hệ số support. Đặc tính quan trọng của 1 itemset chính là Frequency, tần suất xuất hiện các giao dịch có chứa các item set đó.
Ví dụ itemset A = {Beans, Corns}, và itemset B = {Tomatoes}. Chúng ta sẽ xem xét luật kết hợp nếu A được mua, thì B cũng được mua. Với A là Antecedent và B là Consequent, có chứa các tập con nằm trong I.
Để đo lường và chọn lựa một luật kết hợp bất kỳ chúng ta phải sử dụng Support và Confidence
Support là tỷ lệ xuất hiện các giao dịch có chứa cả A và B trong tập dữ liệu D.
Support = P(A ∩ B) = (Số giao dịch có chứa A và B)/ Tổng các giao dịch
Lưu ý ký hiệu ∩ trong công thức và công thức Confidence dưới đây trên có nghĩa là “và”, sự kiện A và B độc lập nhau. Ở đây áp dụng quy tắc nhân trong xác suất, khách hàng mua sản phẩm A rồi mua sản phẩm B hoặc ngược lại, thì việc mua hàng có 2 giai đoạn xảy ra cùng lúc.
Support là thước đo quan trọng vì nếu một luật kết hợp có tỷ lệ support thấp, ít xuất hiện thì có thể xảy ra là do tình cờ.
Tỷ lệ Support thấp cũng có thể không được quan tâm xét từ góc độ kinh doanh vì nó có thể không mang lại lợi nhuận khi quảng cáo các mặt hàng mà khách hàng hiếm khi mua cùng nhau.
Confidence là thước đo độ chính xác của luật kết hợp tìm được, tính bằng cách tìm tỷ lệ trong số các giao dịch có chứa itemset A trong tập giao dịch D thì có bao nhiêu giao dịch chứa luôn B
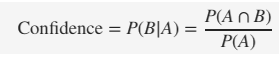
Confidence là thước đo độ tin cậy về những suy luận có từ luật kết hợp tìm được. Giả sử nói khách hàng mua itemset A thì có chắc chắn sẽ mua itemset B? lỡ mua itemset C, itemset E nào đó thì sao? Chúng ta sẽ dựa trên Confidence để chọn ra itemset B để khẳng định luật kết hợp.
Các nhà phân tích có thể thích các luật kết hợp có Support cao hoặc Confidence cao và thường là cả hai. Các luật kết hợp “mạnh” sẽ phải đáp ứng hoặc vượt qua các tiêu chí nhất định hay các yêu cầu được đặt ra, hay còn gọi Threshold. Ví dụ, một nhà phân tích quan tâm đến việc tìm kiếm các mặt hàng siêu thị được mua cùng nhau có thể đặt mức Support tối thiểu là 10% và mức tin cậy tối thiểu là 60%.
Do tùy vào trường hợp, mục đích kinh doanh, và bối cảnh nghiên cứu nên các giá trị tối thiểu của Support và Confidence sẽ khác biệt, nên không có một quy tắc chuẩn nào hết ví dụ, một nhà phân tích nghiên cứu biểu hiện gian lận tài chính sẽ cần giảm mức Support tối thiểu xuống 1% hoặc ít hơn, bởi vì tương đối ít giao dịch sẽ có biểu hiện gian lận trong tập dữ liệu
Support và Confidence là yếu tố quan trọng để đánh giá liệu có hay không các luật kết hợp cần dành sự quan tâm đặc biệt:
- Luật kết hợp phải đạt mức support tối thiểu
- Trong các luật kết hợp đạt mức support tối thiểu, chọn ra các luật kết hợp có Confidence cao nhất.
Quay trở lại ví dụ ở trên,
itemset A = {Beans, Corns}, và itemset B = {Tomatoes} có thể là một luật kết hợp. Trong số 14 giao dịch thì có 3 giao dịch chứa cả A và B.
Support = 3/14 = 21.4%
Có tất cả 5 giao dịch chứa itemset A trong tập dữ liệu 14 giao dịch, mà trong 5 giao dịch này có 3 giao dịch chứa itemset B
Vậy Confidence = 3/5 = 60%
Do tập dữ liệu ít quan sát nên chúng ta không biết liệu 2 tỷ lệ này có thật sự cao hay không. Tuy nhiên tạm thời có thể đưa ra 1 luật kết hợp “Nếu khách hàng mua Beans và Corns, thì sẽ mua Tomatoes” với độ tin cậy 60%, độ ủng hộ 21.4%
Đánh giá dựa trên Support và Confidence thôi cũng chưa đủ, cần nhiều chỉ số đo lường khác, trong bài viết này phần 1 này chúng tôi chỉ đề cập trước về hệ số lift.
Lift là xác định lấy tỷ lệ giữa (tỷ lệ các giao dịch có itemset A và B trên tổng các giao dịch chỉ có itemset A) hay chính là Confidence trên (tỷ lệ các giao dịch chỉ có itemset B trước đó)
Lift {Beans, corn, tomatoes} = 0.6/ (6 : 14) = 1.4 lần. Nghĩa là khả năng khách hàng mua Beans và corn sẽ mua Tomatoes cao chỉ 1.4 lần so với các sản phẩm khác kết hợp với Tomatoes. Lift khá là thấp.
Lift gần đến 1 thường chỉ ra luật kết hợp vừa tìm không có ý nghĩa quan tâm. Ví dụ chúng ta xem lại công thức
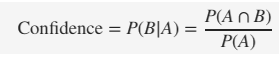
Lift = Confidence/ P(B) = P(A ∩ B)/ P(A).P(B)
Như vậy theo công thức xác suất 2 sự kiện A, B độc lập khi P(A ∩ B) = P(A)P(B). Nếu tỷ lệ lift gần bằng 1 thì nghĩa là 2 sự kiện này độc lập. Sự xuất hiện của A không làm thay đổi xác suất của sự xuất hiện của B. Luật kết hợp không có ý nghĩa quan tâm.
Kết hợp với các tiêu chí Support, Confidence thì Lift phải lớn hơn 1 rất nhiều => Luật kết hợp mới thực sự mạnh.
Như vậy đến đây kết thúc bài viết phần 1. Bài viết phần 2 chúng ta sẽ đi vào các công thức khác cũng như thuật toán Apriori với ví dụ cụ thể.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.
Tài liệu tham khảo
https://www.kdnuggets.com/2016/04/association-rules-apriori-algorithm-tutorial.html/2
https://www-users.cs.umn.edu/~kumar001/dmbook/ch6.pdf
“Introduction to Data mining” – Pearson, tác giả Tan, Steinbach, Kumar
“Data Mining Concepts and Techniques” – Jiawei Han, Micheline Kamber, Jian Pei
“Data mining and predictive analytics” – Daniel T. Larose
“Principles of Data mining” – Max Bramer