
 English
EnglishTrở lại với chủ đề Data cleaning, làm sạch dữ liệu, với task xử lý missing values – vấn đề dữ liệu bị thiếu giá trị, dữ liệu bị thiếu thông tin hay không đầy đủ thông tin ở các quan sát – ở bài viết phần 1, chúng ta đã cùng tìm hiểu Data cleaning, missing values là gì, và đặc biệt là các cơ chế hay các loại Missing value quan trọng. Trong phần 2, chúng ta sẽ phân biệt lại lần nữa các cơ chế Missing values và giới thiệu cách xác định đơn giản với ví dụ cụ thể. Phần 3 tới, BigDataUni sẽ giới thiệu đến các bạn các phương pháp xử lý missing values thông dụng cho từng loại cơ chế.
Các bạn chưa xem qua phần 1 có thể tham khảo tại link dưới đây:
Data cleaning – làm sạch dữ liệu: Xử lý missing values (P1)
Phân biệt các cơ chế missing values
Khi khám phá missing values của dữ liệu, bước cốt lõi đầu tiên phải thực hiện là tìm được nguyên nhân giả định dẫn đến missing values từ ngẫu nhiên, tình cờ, hoặc có chủ đích. Nếu missing values là MCAR (missing value completely at random), MAR (Missing value at random), chúng ta sẽ không cần quan tâm đến thông tin thực bị missing do chúng ít ảnh hưởng đến kết quả phân tích, tuy nhiên phát sinh vấn đề khi loại bỏ có thể khiến mẫu dữ liệu không đủ vì thế cần có các phương pháp áp dụng xử lý phù hợp.
MCAR xuất hiện khi các missing value được phân phối ngẫu nhiên trên tất cả các quan sát, tức là mỗi quan sát đều có khả năng bị missing value ngẫu nhiên như nhau. Cơ chế, nguyên nhân dẫn đến missing value hay chính các missing value không liên quan đến các giá trị ở bất kỳ biến nào trong tập dữ liệu, ngay cả biến được xác định hay chưa được xác định trong tập dữ liệu, không liên quan đến các thông tin có hay không có trong tập dữ liệu.
MAR thì nguyên nhân dẫn đến missing value hay chính các missing value trong 1 biến bất kỳ có một mối liên hệ có hệ thống đối với những dữ liệu có giá trị cụ thể (observed data) hay với những biến còn lại xuất hiện trong tập dữ liệu (nhưng không có mối liên hệ với các giá trị của chính biến đó, nói cách khác không phụ thuộc vào chính biến đó, biến đó là không phải là yếu tố khiến dữ liệu bị missing).
Trường hợp MNAR (missing value not at random), missing values không phải ngẫu nhiên, có thể cố ý, có chủ đích (đề cập hay không đề cập trong bộ dữ liệu, phụ thuộc vào chính biến bị missing values) nguy cơ cao ảnh hưởng đến kết quả phân tích. Và đối với MNAR, chúng ta cần phải có giá trị thực để bổ sung, nhưng trong thực tế thường bất khả thi, đặc biệt trong nghiên cứu, khảo sát, người phỏng vấn từ chối cung cấp thông tinh như phụ nữ thường từ chối những câu hỏi nhạy cảm, có thể khiến họ cảm thấy ngại nhưng đàn ông thì khác
Chúng ta cùng phân biệt lại 3 dạng Missing values chính MCAR, MAR, MNAR thông qua một ví dụ nhỏ dưới đây:
Một nhóm các thầy cô giáo tại một trường Đại học, tiến hành nghiên cứu mức độ hài lòng của sinh viên khi học tại trường trong năm học vừa rồi, chia làm 2 kỳ khảo sát, Học kỳ I/ Giai đoạn 1 khảo sát 1 lần, tương tự như Học kỳ II/ Giai đoạn 2. MCAR xảy ra khi dữ liệu thu thập lần 2 bị missing nhưng nó không liên quan đến bất kỳ biến nào khác bao gồm ví dụ biến mức độ hài lòng ở Giai đoạn 1, ngành học của sinh viên, điểm trung bình học kỳ 1,…Giả định khác, tất cả các sinh viên được khảo sát lần 1 ở học kỳ I, nhưng lần 2 ở học kỳ II các thầy cô chỉ chọn mẫu 70% ngẫu nhiên trong số các sinh viên đã trả lời khảo sát ở học kỳ I, và những sinh viên này được cho rằng đã hoàn thành bảng câu hỏi cả 2 lần. Do chọn mẫu ngẫu nhiên, nên giả định MCAR được đảm bảo ở trường hợp này.
Giả sử, các thầy cô giáo thực hiện nghiên cứu mức độ hài lòng của sinh viên khi học tập tại trường nhưng chỉ quan tâm đến những sinh viên có tỷ lệ tham gia lớp học trên 60%, không phải chú ý đến toàn bộ sinh viên, vì cho rằng các kết quả khảo sát có thể hợp lý và chính xác hơn. Như vậy, missing values có thể phụ thuộc vào mẫu khảo sát với yêu cầu về tỷ lệ tham gia lớp học nếu dữ liệu thu thập từ bộ phận sinh viên đạt yêu cầu có xảy ra vấn đề thiếu giá trị, thiếu thông tin ở các biến, thì trường hợp này có thể gọi là MAR – ngẫu nhiên nhưng không hoàn toàn. Một giả định khác, các thầy cô giáo khảo sát tất cả sinh viên về mức độ hài lòng khi học tập tại trường và bảng câu hỏi có thêm câu hỏi về kết quả học tập, các thầy cô nhận thấy rằng đa số các sinh viên mức độ hài lòng thấp thường có kết quả học tập không tốt, như vậy khi dữ liệu bị missing ở biến kết quả học tập, thầy cô có thể dự báo được dựa trên giá trị hữu hình ở biến mức độ hài lòng trong tập dữ liệu, thì đây là trường hợp MAR. Tuy nhiên cần quan sát thêm, nếu biến kết quả học tập bị missing quá nhiều giá trị, thì có thể đến từ chủ đích sinh viên không muốn công khai, đây là loại 3, MNAR.
Nếu mức độ hài lòng ban đầu là nguyên nhân (hoặc nguyên nhân một phần giải thích missing values) thì có lẽ chỉ những sinh viên có sự hài lòng khi học tập tại trường sẽ trả lời bảng khảo sát đầy đủ, kể cả có được khảo sát 2 lần, tuy nhiên một số sinh viên khác không hài lòng, thì có thể tham gia cuộc khảo sát lần 1 ở học kỳ 1, nhưng có thể không tham gia lần 2 nếu mức độ hài lòng không cải thiện, do cảm thấy phiền, và chán nản. Missing values lần này là MNAR (không phải ngẫu nhiên), do missing values phụ thuộc vào chính yếu tố hài lòng và không thể bỏ qua vì chúng có thể làm sai lệch đáng kể kết quả phân tích. Hạn chế và xử lý MNAR phức tạp hơn nhiều, phải dựa vào kinh nghiệm của người làm phân tích, kinh nghiệm của người làm nghiên cứu, đặc thù mục đích nghiên cứu,… và thường không có một phương pháp được coi là tiêu chuẩn chung áp dụng xử lý cho mọi trường hợp MNAR.
Để biết thêm chi tiết 3 loại cơ chế Missing values, các bạn có thể xem lại bài viết phần 1 của chúng tôi.
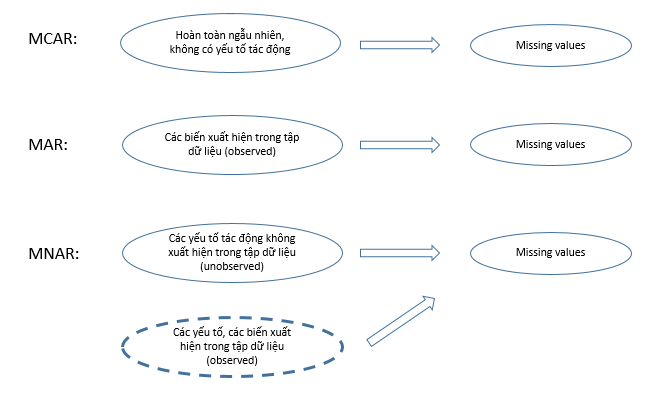
MCAR, MAR, MNAR là các cơ chế phân loại missing values do Donald Rubin tìm ra năm 1976, xác định dựa trên thông tin về biến có missing value, các biến có ảnh hưởng, tác động, hay có mối liên hệ với biến có missing value, và các giả thuyết nằm đằng sau việc dữ liệu bị missing.
Tránh nhầm lẫn giữa MAR và MNAR. Trong MAR, các biến trong tập dữ liệu có thể dùng để dự báo giá trị missing values nếu có mối quan hệ nhưng không phải là yếu tố dẫn đến missing values. Còn MNAR, như ở ví dụ trên biến mức độ hài lòng của sinh viên trong lần khảo sát 2 bị missing có thể do sinh viên không được cải thiện cảm giác hài lòng, lần 1 họ đã cung cấp thông tin, lần 2 từ chối làm vì thấy phiền. Yếu tố dẫn đến missing values chính là biến có missing values trong tập dữ liệu, và kể cả các biến còn lại có thể là tác động, ví dụ ở đây là biến mức độ hài lòng trong đánh giá lần một. Còn MAR, biến kết quả học tập có các giá trị missing có thể dự báo qua mức độ hài lòng khi thấy sinh viên có mức độ hài lòng thấp thì không công khai kết quả học tập, và ngược lại. Nhưng mức độ hài lòng không phải yếu tố tác động đến việc sinh viên không công khai điểm của mình, mà phải kiểm tra thêm nếu sinh viên do xấu hổ, ngại ngùng khi điểm thấp mà không muốn công khai thì đây là MNAR.
Đa phần, các nguyên nhân dẫn đến missing values dạng MNAR thường không thể xác định trong bộ dữ liệu, thường đến từ phía người cung cấp thông tin. Nhưng nếu nhà phân tích và người làm nghiên cứu có thể tìm hiểu được và đưa vào tập dữ liệu để mô hình hóa dự báo missing values cho chính trường hợp MNAR thì sẽ giảm được ảnh hưởng của nó đến kết quả phân tích. Nhưng thực sự rất phức tạp và không hề dễ dàng.
Vì tính chất phức tạp của MNAR, và do các yếu tố xác định thường không nằm trong tập dữ liệu, nên các phương pháp xử lý áp dụng cho MCAR, MAR (dựa trên các biến có mối quan hệ có trong tập dữ liệu) không thể dùng cho MNAR.
Hơn nữa mặc dù biết là cần phân biệt rõ MAR, và MNAR là cực kỳ quan trọng để tránh nhầm lẫn, áp dụng sai phương pháp xử lý nhưng quả thật rất khó khăn. Khó là do các yếu tố khác dẫn đến missing values không đề cập trong dữ liệu thì chúng ta không có thông tin để xác định có phải là MNAR, chúng ta cũng không biết các giá trị bị missing là gì để làm rõ mối quan hệ giữa chúng và các biến còn lại để khẳng định đây là MAR. Mối quan hệ giữa các biến chỉ cho chúng ta cơ sở loại bỏ trường hợp MCAR mà thôi.
Như vậy chúng ta đã nhận diện được các cơ chế missing values, nhưng làm thế nào để xác định chính xác trong một tập dữ liệu cụ thể thì không hề đơn giản, Chúng ta cùng đi qua ví dụ cụ thể để biết cách phân loại cơ chế missing values
Xác định dạng missing values
Xác định cơ chế missing values trong tập dữ liệu thường bắt đầu với việc xác định trước có phải là trường hợp MCAR hay không, nếu không phải thì xét tiếp giữa MAR và MNAR, nếu có thì áp dụng phương pháp xử lý là loại bỏ (Deletion method).
Có 2 phương pháp kiểm định thông dụng để xác định xem missing values có phải trường hợp MCAR hay không, bao gồm t-test và Little MCAR’s test.
Lưu ý các giải thích về MCAR, MAR, hay MNAR ở trên chỉ giúp chúng ta hiểu rõ hơn, và nhận diện ban đầu các cơ chế missing values, nhưng không được dùng để phán đoán một cách định tính, thiếu căn cứ cần có phương pháp định lượng cụ thể.
Tuy nhiên trong số 3 cơ chế, thì chỉ có MCAR có thể dùng các phương pháp định lượng như kiểm định để kiểm chứng, cụ thể là kiểm tra sự khác biệt giữa phần dữ liệu đầy đủ giá trị và phần dữ liệu bị missing, nếu có sự khác biệt, tức có thể có mối liên hệ giữa xác suất missing values và các biến còn lại. MAR, thì các chuyên gia thường không thể xác thực rõ mối quan hệ giữa missing values với các biến còn lại một cách chính xác nếu không biết thông tin về những giá trị bị missing. MNAR cũng vậy, các giả định không thể đưa ra nếu không có thông tin về missing values, các yếu tố gây nên missing values không được đề cập đến trong tập dữ liệu. Để xác định giữa MNAR, MAR sau khi loại bỏ MCAR thực sự rất khó, hầu như không có một quy trình, phương pháp định lượng, phương pháp đồ thị cụ thể, mà phải áp dụng thêm những hiểu biết về đặc thù công trình nghiên cứu, thiết kế nghiên cứu, kiến thức chuyên ngành.
- T-test
Trong kiểm định t đối với missing values, các chuyên gia thông thường sẽ tạo một biến mới, một biến giả với 2 giá trị 0 và 1 từ biến có missing values, được gọi là “indicator varibale”. Dựa trên biến này, chúng ta sẽ phân dữ liệu theo 2 phần: phần đầy đủ giá trị và phần có missing theo mỗi biến đang xét. Tiếp theo tính giá trị trung bình của mỗi biến còn lại theo mỗi nhóm rồi so sánh nếu có sự khác biệt hay không. Chúng ta cùng nhìn qua ví dụ tham khảo từ tài liệu “Applied Missing Data Analysis” của tác giả Craig K.Enders khi giải thích về phương pháp t-test áp dụng cho MCAR
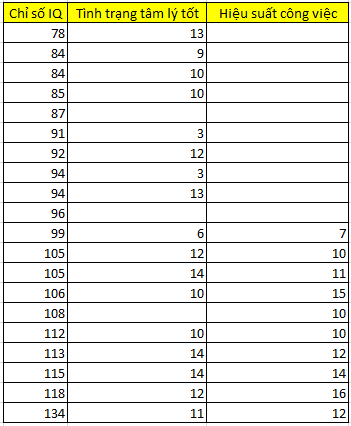
Dưới đây là bảng dữ liệu nhỏ về những ứng viên được khảo sát cho mục đích chọn lựa trở thành nhân viên chính thức, các ứng viên sẽ thực hiện bài kiểm tra về IQ, bài đánh giá về thể trạng tâm lý trong buổi phỏng vấn (điểm cao ứng với tình trạng tâm lý tốt), hiệu suất công việc được các giám sát viên theo dõi và đánh giá trong 6 tháng. Chúng ta cùng nhìn qua cách thực hiện t-test để đánh giá liệu missing values ở biến hiệu suất công việc có phải MCAR hay không.
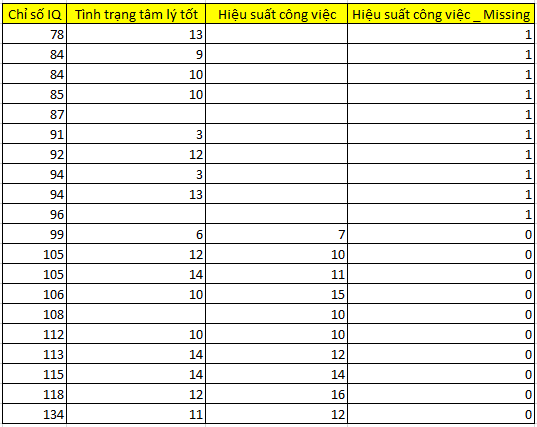
Trước tiên chúng ta tạo biến “hiệu suất công việc_missing”, nhân viên nào không có giá trị tại hiệu suất công việc thì sẽ có giá trị là 1, và ngược lại là 0. Chúng ta sẽ dựa vào biến này để phân thành 2 nhóm, nhóm A: có giá trị 1, tức có missing values tại biến hiệu suất công việc, nhóm B là ngược lại. Việc coding mục đích làm rõ các quan sát thuộc nhóm nào.
Tiếp theo chúng ta sẽ tính giá trị trung bình của chỉ số IQ, điểm số của biến tình trạng tâm lý của mỗi nhóm A và B.
Nhóm A: mean (trung bình) IQ = 88.5; mean (trung bình) tình trạng tâm lý = 9.125 (lưu ý chỗ không có giá trị không có nghĩa mang giá trị, chúng ta sẽ bỏ qua khi tính, tức chỉ tính trung bình trên 8 không phải 10)
Nhóm B: mean IQ = 111.5; mean tình trạng tâm lý = 11.4
Công thức kiểm định t (Welch’s t-test) vì 2 nhóm này là độc lập nên không áp dụng kiểm định t thông thường (Student’s t-test)
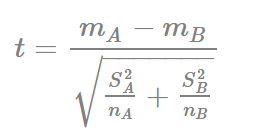
Với mA và mB trên tử số là giá trị trung bình của mỗi nhóm, sA và sB là độ lệch chuẩn của mỗi nhóm, NA và NB là số quan sát trong mỗi nhóm. Bậc tự do được tính như sau
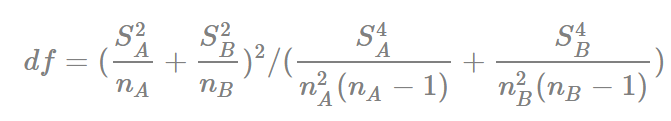
 Công thức tính độ lệch chuẩn:
Công thức tính độ lệch chuẩn:
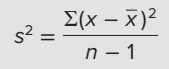
Vậy trước tiên chúng ta tính thử xem các missing values tại Hiệu suất công việc có mối liên hệ với biến IQ hay không. SA = 5.77, SB = 9.69
tIQ = (111.5 – 88.5)/ (5.772/10 + 9.692/10) ½ = 6.44
Bậc tự do tính được = 14.67
H0: mA = mB
H1: mA ≠ mB
Giả sử lấy độ tin cậy 95%, mức ý nghĩa α = 0.05, tra bảng t xác định được giá trị t tra bảng = 2.131 đến 2.145, luôn nhỏ hơn giá trị t kiểm định ở trên.
p-value < 0.001 nên đủ cơ sở bác bỏ H0
Tức có sự khác biệt giữa 2 nhóm theo chỉ số IQ, giả định MCAR bị bác bỏ, như vậy missing values của biến hiệu suất làm việc có thể có mối quan hệ với biến IQ, giả định MCAR bị bác bỏ. Các bạn có thể thấy những nhân viên không có giá trị tại biến hiệu suất công việc thì có chỉ số IQ hoàn toàn thấp hơn hẳn so với nhóm còn lại. Chúng ta có thể khẳng định một phần đây là MAR nhưng phải xem xét thêm các yếu tố gây nên missing values có phải đến từ chính biến bị missing hay không, để xem xét trường hợp MNAR. Ví dụ việc không ghi nhận hiệu suất công việc có thể do sai sót của người giám sát, hoặc do nhân viên nghỉ làm thường xuyên trong giai đoạn đánh giá vì nhiều nguyên do khác nhau, hoặc đã nghỉ việc hẳn. Xác định nguyên nhân là việc không hề đơn giản và mất thời gian
Chúng ta xét tương tự cho biến tình trạng tâm lý. Kết quả kiểm định t như sau:
Ttình trạng tâm lý = 1.39, bậc tự do = 11.7, t tra bảng = 2.201 đến 2.179 lớn hơn t kiểm định nên không bác bỏ H0, tức không có sự khác biệt giữa 2 nhóm, không có mối liên hệ giữa missing values của biến hiệu suất làm việc với biến này.
Nhưng do trường hợp IQ chúng ta xác định giả định MCAR là không đúng nên ở trường hợp biến tình trạng tâm lý dù không bác bỏ H0, thì đây vẫn không phải MCAR.
Nhìn đơn giản nhưng kiểm định t lại có phát sinh nhiều vấn đề cần lưu tâm. Chúng ta phải chuẩn bị số liệu thống kê và tự tính nếu không có sự hỗ trợ của các phần mềm phân tích thì khi dữ liệu chỉ có nhiều hơn 3 biến và nhiều quan sát thì chúng ta tính cũng đã thấy mất thời gian khá nhiều. Ví dụ ở đây chúng ta chỉ có 3 biến vậy sẽ phải thực hiện kiểm định t (3-1) lần, trừ 1 là do xếp cặp của biến có missing data với các biến còn lại, nên không tính, như vậy nếu có nhiều hơn 10 biến trong tập dữ liệu thì phải thực hiện kiểm định t đến 9 lần, rất cồng kềnh và mất thời gian, chưa kể nếu tập dữ liệu có nhiều hơn 1 biến bị missing data, thì chắc phải bỏ cuộc.
Kiểm định t không xét đến mối tương quan giữa các biến với nhau trong tập dữ liệu, có nghĩa nếu chúng ta không thực hiện hết các kiểm định, thì có thể bỏ sót trường hợp missing values có mối quan hệ với các biến còn lại cho dù chỉ có thể chỉ có 1.
Ngoài ra còn phát sinh vấn đề đến từ lĩnh vực thống kê đó là Alpha inflation, dịch nôm na là mức ý nghĩa alpha có thể tăng dần, nghĩa độ tin cậy có thể giảm dần khi thực hiện nhiều kiểm định t trên cùng một tập dữ liệu, hay một mẫu dữ liệu, và có thể dẫn đến sai lầm loại I trong kiểm định: bác bỏ H0 trong khi giả thuyết này đúng, nói cách khác có thể không có mối quan hệ giữa 2 nhóm missing và không có missing nhưng chúng ta lại nói có.
Việc sử dụng kiểm định t có thể chỉ dừng lại ở mục đích chính là tìm các biến trong tập dữ liệu có thể giúp xử missing value tại biến có missing data. Đây lại là nhược điểm của phương pháp Little’s MCAR test mà chúng tôi từng đề cập lần trước và chuẩn bị trình bày lại dưới đây.
Kiểm định t khi gặp mẫu dữ liệu nhỏ có thể không cung cấp kết quả kiểm định một cách chính xác nhất ví dụ nếu không xét biến hiệu suất công việc mà là biến tình trạng tâm lý nhưng chỉ có 3 quan sát trong biến này là có missing values, vậy khi phân thành nhóm A và nhóm B, thì nhóm A N rất bé, và chênh lệch rất nhiều so với nhóm B (3 với 17) thì liệu kết quả kiểm định t so sánh nhóm A và nhóm B theo giá trị trung bình của IQ và hiệu suất công việc liệu có đáng tin cậy.
Bên trên là một số khuyết điểm cần lưu ý khi áp dụng phương pháp kiểm định t. Chúng ta cùng sang phương pháp tiếp theo Little’s MCAR test.
- Little’s MCAR test
Phương pháp kiểm định này dựa trên hướng tiếp cận của t-test để kiểm tra kết luận ban đầu có hay không có mối liên hệ giữa missing values với các biến còn lại trong tập dữ liệu, nhưng xét tất cả các biến cùng lúc thay vì xét từng cặp. Phương pháp của Little có thể áp dụng cho toàn bộ tập dữ liệu và chỉ có 1 kết quả duy nhất để phân tích, giá trị kiểm định Chi bình phương – p-value. Công thức cũng vì thế mà phức tạp hơn nên chúng tôi không tiện trình bày trong bài viết này.
Phương pháp kiểm định này trước tiên sẽ xác định trước các nhóm nhỏ trong tập dữ liệu dựa vào giá trị missing values tại các biến. Ví dụ: nhóm 1: có 2 quan sát chỉ có giá trị ở biến IQ, nhóm 2: có 8 quan sát giá trị ở biến IQ và tình trạng tâm lý, nhóm 3: có 1 quan sát có giá trị ở biến IQ và hiệu suất công việc, nhóm 4: có 9 quan sát có giá trị ở cả 3 biến. Việc tiếp theo là tính trung bình giá trị tại các biến ở mỗi nhóm, sau đó so sánh với giá trị trung bình mong đợi của mỗi biến ở tổng thể dữ liệu (không quan tâm có missing values hay không, áp dụng phương pháp Maximum Likelihood Estimation để ước lượng). MCAR xảy ra, khi không có sự khác biệt giữa giá trị trung bình của các nhóm ở từng biến cụ thể với giá trị trung bình của biến đó ước lượng cho tổng thể.
Công thức của phương pháp này cũng như việc tính toán khá phức tạp nên chúng tôi không tiện đề cập trong bài viết này, các bạn có thể tham khảo thêm ở những tài liệu khác
Trong phần mềm SPSS, Little’s MCAR test được triển khai sử dụng kiểm định Chi-square – chi bình với H0: missing values là loại MCAR, nếu giá trị p-value < 0.05, tức loại bỏ H0, missing values không phải MCAR và ngược lại.

Dưới đây là kết quả từ SPSS, cột sig tức p-value = 0.016 < 0.05, tức bác bỏ giả thuyết H0, missing values không phải là MCAR (EM – là Expectation Maximization – thuật toán cực đại hóa kỳ vọng, một hướng tiếp cận trong Maximum likelihood estimation, để ước lượng các tham số trong lĩnh vực thống kê)
Như vậy kết quả đưa ra cũng giống với kiểm định t. Tuy nhiên một trong những khuyết điểm lớn nhất mà chúng tôi vừa nói ở trên chính là chúng ta không biết giữa các missing values của mỗi biến có hay không có mối quan hệ với những biến còn lại khi xử lý missing values có thể gặp khó khăn. Tuy nhiên các phương pháp mà bài viết phần 3 chúng tôi đề cập có thể khắc phục nhược điểm này.
Cũng như t-test, nếu chỉ dựa vào mỗi little’s test cũng không thể chắc chắn dữ liệu missing values là MCAR, nhưng đa phần Little’s test được ưu tiên sử dụng hơn so với t-test mặc dù vẫn còn nhiều vấn đề liên quan đến độ hiệu quả khi áp dụng cho bộ dữ liệu ít biến, và những giả định khác được đề ra trong phương pháp này. Chính là nhờ nó giải quyết các nhược điểm của t-test điển hình là tránh được sự cồng kềnh trong tính toán, và đảm bảo không có mối quan hệ tiềm ẩn nào giữa các biến trong tập dữ liệu và missing values chưa được tính đến.
Như vậy chúng ta cũng đã làm quen với 2 phương pháp thông dụng trong xác định missing values có phải là MCAR hay không. Tuy nhiên điều vẫn phải quan tâm nhất chính là làm thế nào kết luận giữa MAR và MNAR.
Chúng tôi sẽ bật mí đến các bạn trong phần đầu của bài viết phần 3 sắp tới, bên cạnh nội dung trọng tâm là các phương pháp xử lý missing values thông dựng ứng cho mỗi cơ chế.
Tài liệu tham khảo:
“Applied Missing Data Analysis: Methodology in the Social Sciences” của tác giả Craig K. Enders
“Best practices in Data cleaning” của tác giả Jason W. Osborne
“Missing data: a gentle introduction” của Patrick E. McKnight, Katherine M. McKnight, Souraya Sidani, Aurelio José Figueredo
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.