
 English
EnglishỞ phần 1 và phần 2 chúng ta đã tìm hiểu Data cleaning là gì, thế nào là missing values, cũng như các cơ chế chính của missing values bao gồm MCAR, MAR, MNAR, và sử dụng kiểm định đơn giản để xác định trường hợp missing values có phải MCAR hay không trước khi phân biệt tiếp MAR và MNAR. Trở lại với phần cuối của chủ đề Data cleaning – làm sạch dữ liệu với task xử lý missing values BigDataUni sẽ giới thiệu đến các bạn một số phương pháp cơ bản và thông dụng trong việc xử lý dữ liệu bị missing bắt đầu với các phương pháp deletion, nhưng trước đó chúng ta cùng tìm hiểu nhanh cách phân biệt giữa MAR và MNAR sau khi đã xác định missing values không phải là MCAR.
Bạn nào chưa xem 2 phần trước có thể tham khảo các link dưới đây:
Data cleaning – làm sạch dữ liệu: Xử lý missing values (P1)
Data cleaning – làm sạch dữ liệu: Xử lý missing values (P2)

Phân loại missing values là MAR hoặc MNAR sau khi loại bỏ MCAR
Nhắc lại MAR, MNAR
MAR: nguyên nhân dẫn đến missing value hay chính các missing value trong 1 biến bất kỳ có một mối liên hệ có hệ thống đối với những dữ liệu có giá trị cụ thể (observed data) hay với những biến còn lại xuất hiện trong tập dữ liệu (nhưng không có mối liên hệ với các giá trị của chính biến đó, nói cách khác không phụ thuộc vào chính biến đó, biến đó là không phải là yếu tố khiến dữ liệu bị missing).
Trường hợp MNAR (missing value not at random), missing values không phải ngẫu nhiên, có thể cố ý, có chủ đích (đề cập hay không đề cập trong bộ dữ liệu, phụ thuộc vào chính biến bị missing values) nguy cơ cao ảnh hưởng đến kết quả phân tích. Ví dụ điển hình MNAR: trong nghiên cứu, khảo sát, người phỏng vấn từ chối cung cấp thông tinh như phụ nữ thường từ chối những câu hỏi nhạy cảm, có thể khiến họ cảm thấy ngại nhưng đàn ông thì khác.
Việc xác định missing values có phải là MAR và MNAR không hề đơn giản do không có thông tin về những dữ liệu bị missing, thì thứ nhất sẽ khó có thể áp dụng những phương pháp định lượng, và hình học, biểu đồ để đánh giá mối quan hệ giữa missing values và các biến còn lại trong tập dữ liệu, thứ hai cũng không tìm ra mối quan hệ giữa missing values với những yếu tố nguyên nhân có hay không đề cập trong tập dữ liệu.
Một trong các điểm quan trọng giúp chúng ta phân biệt MCAR, MAR và MNAR đó chính là “ignorable” – khả năng bỏ qua, có thể lờ đi, hiểu đơn giản nếu missing values là “ignorable” thì chúng ta có thể áp dụng các phương pháp xử lý missing values mà không cần quan tâm đến những dữ liệu bị missing, hay cụ thể hơn là không cần ước lượng tham số phân phối xác suất của dữ liệu missing (missing data distribution) ví dụ ước lượng giá trị trung bình của missing values, tỷ lệ missing values, phương sai của missing values
Phân phối xác suất của dữ liệu là gì các bạn có thể tham khảo qua bài viết thống kê suy luận của chúng tôi theo link dưới đây:
Tổng quan về Statistics: Inferential statistics (thống kê suy luận)
Cách giải thích khác, khi missing values thuộc một trong 2 cơ chế MCAR, MAR gọi là “ignorable” thì không cần phải mô hình hóa để ước lượng chính xác các tham số của missing data khi đang triển khai các phương pháp xử lý.
Ví dụ nhỏ để minh họa thế nào là “ignorable”, giả sử chúng ta đang dự báo giá trị tại biến “mức độ quan tâm chương trình khuyến mãi” của khách hàng vừa được khảo sát, và chúng ta đã bỏ qua yếu tố “thu nhập hàng tháng” của khách hàng, nhưng trong thực tế chúng có nhiều ý nghĩa phân tích và không nên bỏ qua, thì trường hợp này không gọi là ignorable, mà là “non-ignorable”. Tuy nhiên, vấn đề khác xảy ra là biến “thu nhập hàng tháng” có nhiều giá trị bị missing nhưng chúng ta vẫn có thể suy luận ra được dựa vào các biến khác như “mức chi trả cho các sản phẩm tại cửa hàng” nếu cao thì thu nhập hàng tháng có thể cao và ngược lại, vậy thì đây sẽ là “ignorable”, cụ thể hơn là trường hợp MAR. Đây cũng là làm rõ cho đặc điểm MAR mà chúng tôi đề cập 2 bài viết trước: missing values có thể được dự báo dựa vào các biến còn lại trong tập dữ liệu.
MNAR chính là cơ chế “non – ignorable”, vì khi xử lý missing values cần phải biết những giá trị bị missing, những thông tin bị thiếu trong tập dữ liệu, nếu không thì phải có mô hình ước lượng các tham số của missing data. MCAR chúng ta có thể bỏ qua các missing values, vì chúng không ảnh hưởng đến kết quả phân tích sau cùng. MAR, thì một phần dựa trên những dữ liệu observed, các giá trị có trong tập dữ liệu để tiến hành xử lý missing values, nên cũng không nhất thiết phải tìm ra các giá trị thực của dữ liệu bị missing và các tham số của chúng một cách chính xác nhất, các mô hình dùng để “impute” (phương pháp imputation chúng tôi sẽ đề cập ở bài viết sắp tới), dự báo giá trị đã bị missing để thêm vào tập dữ liệu, sẽ có sai số và độ tin cậy nhất định chúng ta sẽ phải chấp nhận.
Tác động của cơ chế MNAR, hay non-ignorable lên kết quả phân tích, chúng ta không thể biết và vì thế ảnh hưởng đến những lợi ích nhận được nguồn tài sản dữ liệu. Hơn nữa, chúng ta không có bất kỳ thông tin gì để giải thích, để mô hình và để hiểu tại sao dữ liệu lại missing, do đó cũng ảnh hưởng đến việc ước lượng các tham số của chính tổng thể dữ liệu, và các kết luận thống kê.
Như vậy chúng ta đã hiểu được phần nào “ignorable” và “non-ignorable” trong missing values là gì, thì cùng quay lại phân biệt tiếp giữa MAR và MNAR.
MAR và MNAR chúng ta không có bất kỳ phương pháp định lượng, và đồ thị hình học,… có thể giúp phân biệt missing values trong tập dữ liệu sẽ phụ thuộc một trong hai cơ chế này. Có một cách “chữa cháy” nhưng cũng đã được minh chứng bởi các chuyên gia. Đó chính là nhà phân tích, hoặc nhà nghiên cứu cần dựa vào tư duy logic, sự hiểu biết, kinh nghiệm chuyên môn của mình để nhận biết khả năng missing values có thể “ignorable” hay “non-ignorable” để chọn lựa giữa MAR, MNAR sau khi đã loại bỏ MCAR.
Có 4 trường hợp có thể giả định trường hợp missing values là “ignorable” theo chuyên gia Joseph L. Schafer trong nghiên cứu của mình về xử lý dữ liệu đa biến không đầy đủ. BigDataUni xin được tóm tắt ngắn gọn như sau:
- Double Sampling – lấy mẫu 2 lần – các thông tin được khảo sát lần 1 từ tất cả người tham gia phỏng vấn, sau đó lần 2 thu thập thêm thông tin từ một mẫu nhỏ trong mẫu lớn chứa tất cả người tham gia lần 1. Các missing values trong tập dữ liệu lúc này được gọi là MAR khi mẫu nhỏ được chọn ra dựa trên chính thông tin có được từ mẫu lớn, sau lần 1 thu thập. Ví dụ một cuộc khảo sát độ hài lòng của nhân viên trong công ty được triển khai, nhưng một số nhân viên không đưa đủ thông tin. Khi ấy, những người phụ trách sẽ phải liên hệ từng nhân viên một để yêu cầu cung cấp thêm. Các câu hỏi đặt ra có thể xoay quanh như liệu nhân viên có hiểu bảng khảo sát không, quy trình khảo sát có làm phiền hay không…? Mục đích là tìm ra nguyên nhân dữ liệu bị missing. Nếu nhận thấy đa số là do chủ đích không muốn công khai, nhân viên gặp vấn đề về đọc hiểu, không có thời gian làm khảo sát thì MNAR là chắc chắn, nếu nhân viên ngẫu nhiên quên một số câu hỏi thì là MAR.
- Tình huống thứ hai, nhà phân tích không có thông tin gì về những người không cung cấp thông tin, không trả lời khảo sát. Không giống như khảo sát độ hài lòng của nhân viên ở ví dụ trên, tất cả những người tham gia đều biết thông tin là những ai, ở tình huống này, các nhà nghiên cứu có thể không có thông tin về những người nhận được khảo sát nhưng không trả lời. Ví dụ khảo sát xu hướng tiêu thụ thực phẩm sạch tại các siêu thị đối với nhóm khách hàng thân thiết, thì người tiêu dùng có thể cung cấp thông tin cá nhân tuy nhiên các nhà nghiên cứu không có quyền truy cập thông tin cá nhân của người làm khảo sát để liên hệ lại khi họ không trả lời khảo sát đầy đủ.
Tuy nhiên, nếu có thể chọn ngẫu nhiên trong những người không trả lời bảng khảo sát để theo dõi chuyên sâu, thì dữ liệu bị thiếu có thể được coi là MAR hoặc “ignorable”. Giả sử nhà nghiên cứu có thể phân vùng để tiến hành, như ở thành phố Hồ Chí Minh, họ có thể chia mẫu thành các quận huyện. Lúc này khi tỷ lệ missing cao ở bất kỳ khu vực nào họ có thể xác định được. Sau đó thực hiện khảo sát lần nữa tại những siêu thị ở khu vực có tỷ lệ missing cao, các khách hàng thân thiết tại các nơi này (trước đây chưa thực hiện khảo sát lần đầu) sẽ được chọn ngẫu nhiên và họ có thể cho biết được nguyên nhân vì sao dữ liệu missing và hạn chế được missing data. Các chuyên gia có thể hỏi thêm những thông tin chuyên sâu hay khuyến khích họ đưa thêm thông tin liên quan đến mục đích nghiên cứu, bằng cách linh hoạt trong hình thức phỏng vấn.
- Tình huống thứ ba, số người tham gia khảo sát, hay số lượng quan sát trong một mẫu dữ liệu là không bằng nhau, không cân xứng một cách “ngẫu nhiên” giữa các nhóm khác nhau phục vụ cho việc khảo sát, thì missing values có thể được coi là MAR, hay “ignorable”. Ví dụ một mẫu dữ liệu chia thành 2 nhóm A và B dựa trên một số tiêu chí nào đó để phân chia, thì tình cờ thấy số quan sát trong nhóm A nhiều hơn nhóm B. Như vậy để cân bằng 2 nhóm, nhóm B cần bổ sung thêm số quan sát, nhưng mẫu dữ liệu chỉ có nhiêu đó, nên số quan sát thêm vào nhóm B chắc chắn là missing values. Quá trình này thường thấy trong nghiên cứu lâm sàng khi kiểm chứng độ hiệu quả giữa các liệu pháp điều trị và thuốc chữa bệnh giữa 2 nhóm bệnh nhân khác nhau. Việc cân đối không những có ý nghĩa thống kê mà nó còn tạo ra các trường hợp missing values dạng MAR, hỗ trợ làm cải thiện độ hiệu quả và sự phù hợp khi áp dụng nhiều phương pháp xử lý MAR khác nhau và vẫn có thể đảm bảo kết quả phân tích sau cùng là chính xác.
- Tình huống thứ tư, missing data có thể được cho là “ignorable” khi chúng xảy ra trong các trường hợp gần giống với Double Sampling ở phía trên. Nghĩa là missing data sẽ phụ thuộc hay liên quan đến dữ liệu hiện có, hoặc chúng diễn ra một cách ngẫu nhiên. Ví dụ một mẫu dữ liệu đầy đủ ban đầu với 10 biến đo lường, sau đó chúng ta chọn ra các mẫu nhỏ và thêm vào các biến đo lường khác vì muốn truy xuất thêm các thông tin có giá trị dựa trên những dữ kiện có được ở mẫu dữ liệu ban đầu. Lúc này khi missing values xảy ra, chúng ta có thể kết luận đây là MAR.
- Nhắc lại, trường hợp missing data được cho là “ignorable” khi chúng xảy ra ngẫu nhiên và có liên quan đến những thông tin trong tập dữ liệu. Còn “non-ignorable” khi missing data không diễn ra ngẫu nhiên, và các thông tin để giúp chúng ta giải thích tại sao lại có missing data là không có sẵn.
Còn nhiều cách thức khác để giúp chúng ta phân biệt missing values có phải MAR hay MNAR, như đã nói, cần phải dựa vào tư duy logic, kinh nghiệm, kiến thức chuyên môn của người làm nghiên cứu, nhưng đều phải có điểm chung là làm thế nào chỉ ra được có hay không có “yếu tố ngẫu nhiên”.
Như vậy chúng ta đã tìm hiểu xong và cơ bản là đầy đủ về 3 cơ chế MAR, MNAR, MCAR, chúng ta đi vào tìm hiểu những phương pháp xử lý missing values.
Ở phạm vi bài viết này, chúng tôi sẽ chỉ trình bày đến các bạn những phương pháp thông dụng trong MCAR và MAR, riêng MNAR các bạn có thể tham khảo ở những tài liệu khác.
Phương pháp xử lý missing values phổ biến (MCAR) : Phương pháp deletion
Tổng quan về các phương pháp xử lý missing values phổ biến thì có 3 dạng chính:
- Complete – case analysis: sử dụng dữ liệu hiện có và đầy đủ giá trị, trong từng giai đoạn phân tích sau khi đã loại bỏ những quan sát, những trường hợp có missing values. Quan sát/ trường hợp nào bị missing values tại một hay trên một biến bất kỳ đều bị loại bỏ. Phương pháp này cực kỳ đơn giản, và thường được nhiều nhà phân tích “ưa chuộng” vì nó làm giảm bớt thời gian cho quy trình Data cleaning. Nhưng lại ảnh hưởng rất lớn đến kích thước mẫu, và các kết quả phân tích thống kê bị giảm độ tin cậy, các kết luận (thống kê suy luận, ước lượng tham số) đưa ra về đối tượng nghiên cứu có thể không phản ánh đúng thực tế, có thể bị “bias”. Tuy nhiên đây lại là một trong những phương pháp phổ biến nhất, được tích hợp trong các phần mềm thống kê nổi tiếng như của SAS, SPSS để xử lý dữ liệu missing.
Điều kiện để áp dụng Complete – case analysis, là missing values phải thuộc cơ chế MCAR (Missing completely at random) tức xảy ra hoàn toàn ngẫu nhiên, và mẫu dữ liệu phải đủ lớn, và đảm bảo khi loại bỏ missing values, mẫu dữ liệu vẫn ở trạng thái “đủ” để thực hiện phân tích.
Phương pháp Complete – case analysis còn được gọi là listwise deletion.
Chúng ta cùng nhìn lại ví dụ ở bài viết trước, ví dụ tham khảo từ tài liệu “Applied Missing Data Analysis” của tác giả Craig K.Enders.
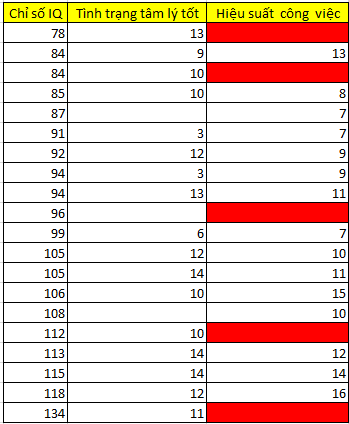
Dưới đây là bảng dữ liệu nhỏ về những ứng viên được khảo sát cho mục đích chọn lựa trở thành nhân viên chính thức, các ứng viên sẽ thực hiện bài kiểm tra về IQ, bài đánh giá về thể trạng tâm lý trong buổi phỏng vấn (điểm cao ứng với tình trạng tâm lý tốt), hiệu suất công việc được các giám sát viên theo dõi và đánh giá trong 6 tháng.
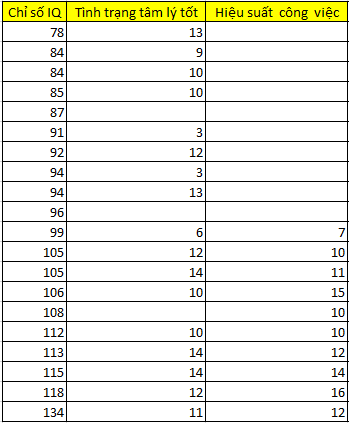
Sau khi đã thực hiện kiểm định t-test và Little’s MCAR test chúng ta đã xác định các trường hợp missing values tại biến hiệu suất công việc không phải là MCAR, mà là MAR, thấy rằng những nhân viên có chỉ số IQ thấp, sẽ có xu hướng bị missing values nhiều hơn.
Chúng ta cùng áp dụng thử Listwise deletion cho trường hợp này và loại bỏ những nhân viên có chỉ số IQ từ 78 đến 96, do nhóm này không có giá trị tại biến hiệu suất công việc.
Tập dữ liệu còn lại được trực quan dưới đồ thị dưới đây với 2 biến IQ và hiệu suất công việc:
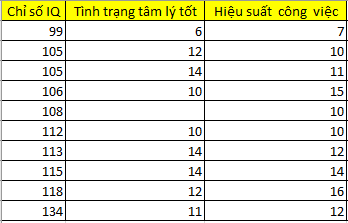
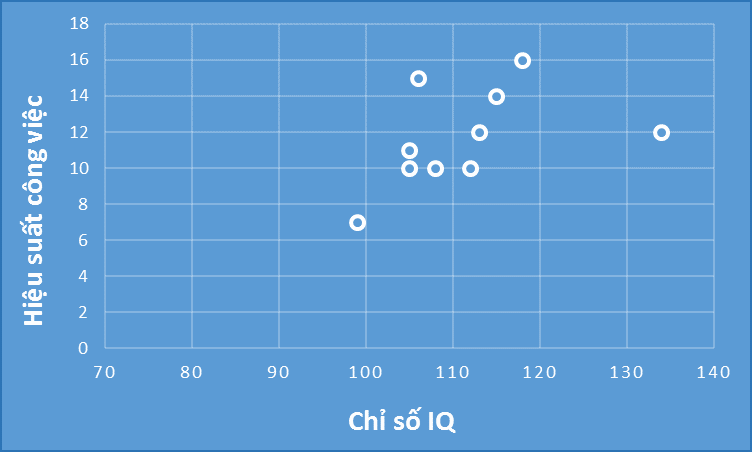
Các bạn có thể thấy những nhân viên được giữ lại trong tập dữ liệu thì chỉ số IQ cao và Hiệu suất công việc cao, chúng có mối liên hệ thuận với nhau, nếu chúng ta thực hiện ước lượng tham số vậy khả năng cao bỏ lỡ các trường hợp nhân viên có chỉ số IQ thấp nhưng có chắc hiệu suất công việc sẽ thấp? Chúng ta có thể sẽ bị “ngộ nhận” nhân viên có chỉ số IQ cao làm việc sẽ tốt hơn, và các nhân viên có chỉ số IQ thấp thì loại bỏ mà thực chất họ có hiệu suất làm việc rất cao.
Chúng ta cùng nhìn qua tập dữ liệu đầy đủ giả sử khi không bị missing, theo tài liệu “Applied Missing Data Analysis” của tác giả Craig K.Enders.
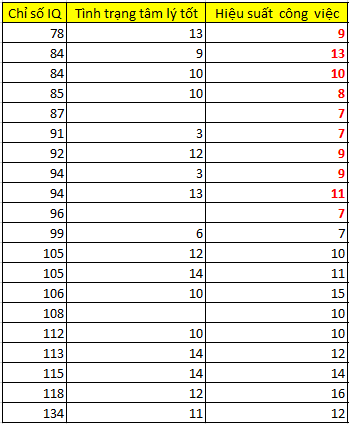
Các bạn có thể thấy có 2 nhân viên chỉ số IQ là 84 nhưng hiệu suất làm việc lại rất cao 10 với 13, trong khi đó có 1 nhân viên chỉ số IQ cao tới 96 nhưng hiệu suất làm việc thấp nhất chỉ có 7.
Như vậy, đây cũng đủ cho thấy được “mức nguy hiểm” nếu missing values là MAR, mà tiến hành loại bỏ các quan sát có bị missing giá trị có thể khiến chúng ta đưa ra kết luận sai lầm, bị bias.
Giả sử, cũng tập dữ liệu trên nhưng dữ liệu missing được kết luận là MCAR, không phải MAR, các bạn cùng nhìn vào bảng dưới đây:
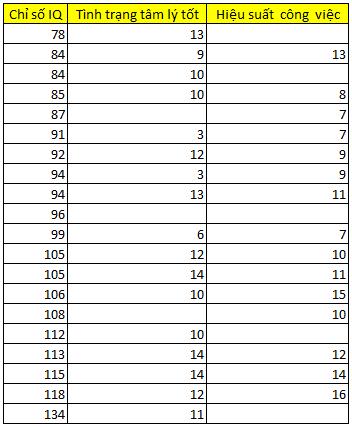
Các bạn có thể thực hiện kiểm định t giống ở phần 2 để kiểm chứng, chúng tôi sẽ không trình bày lại ở bài viết này. Nhìn sơ qua chúng ta không thể xác định mối liên hệ giữa chỉ số IQ và các missing values, cũng như biến tình trạng tâm lý. Như vậy đây không phải là MAR, khả năng cao là MCAR (giả sử ở đây chúng ta không nói đến MNAR)
Tiếp theo chúng ta cùng sử dụng listwise deletion để xem kết quả có bị bias như trên hay không, bảng dữ liệu sau khi loại bỏ missing values theo phương pháp listwise deletion
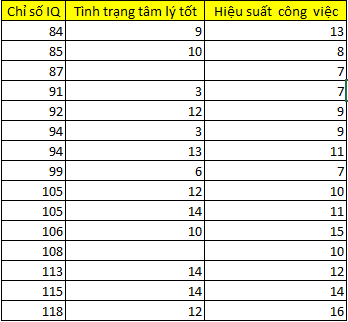
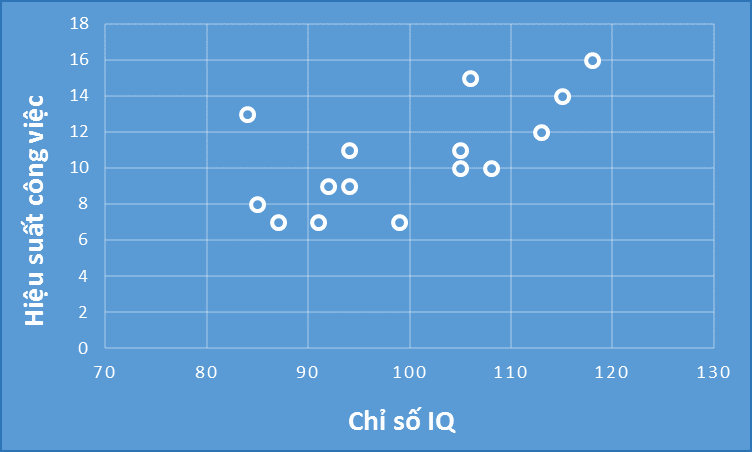
Qua biểu đồ chúng ta thấy được dữ liệu đã có phần cân đối hơn. Các kết luận về đối tượng nghiên cứu, các tham số được ước lượng có thể chính xác hơn, vấn đề bias phần nào đã được hạn chế. Tóm lại, Listwise deletion chỉ áp dụng tốt cho trường hợp missing values là MCAR. Chúng ta sang dạng thứ 2 tiếp theo:
- Available-case analysis: ngược lại với Complete-case analysis hay listwise deletion, phương pháp này các chuyên gia sẽ sử dụng toàn bộ dữ liệu hiện có để tiến hành phân tích. Nghĩa là tất cả các giá trị hiện hữu trong tập dữ liệu sẽ được phân tích, những giá trị nào không có sẽ bỏ qua. Khác với Listwise deletion, chỉ cần một quan sát, một đối tượng trong tập dữ liệu có một giá trị missing tại một biến bất kỳ, thì sẽ bị loại bỏ (ví dụ trong excel, sẽ phải loại bỏ một dòng dữ liệu, nếu dòng này bị missing values ở bất kỳ ô nào) thì ở Available – case analysis, chúng ta sẽ xử lý missing values cho các đối tượng missing data, không loại bỏ hoàn toàn, chỉ loại bỏ ở cấp độ biến, không phải toàn quan sát (ví dụ trong excel, một dòng dữ liệu có missing values ở một số cột, như vậy chúng ta sẽ không quan đến các cột biến đó, những giá trị ở các cột còn lại vẫn được dùng đến) Phương pháp này còn gọi là Pairwise deletion. Ưu điểm của Pairwise deletion so với listwise deletion là nó giữ lại nhiều thông tin hơn, tránh làm mất những thông tin hữu ích và có giá trị.
Pairwise deletion cũng giống như listwise deletion, yêu cầu dữ liệu missing phải thuộc cơ chế MCAR. Khuyết điểm lớn nhất của Pairwise deletion là số quan sát trong mẫu xét theo từng biến sẽ khác nhau, thậm chí là chênh lệch nhiều nếu số giá trị missing ở mỗi biến khác biệt lớn. Điều này mang lại nhiều vấn đề khi tiến hành phân tích mối tương quan giữa 2 biến bất kỳ (correlation analysis).
Tuy nhiên nếu mục đích chỉ là phân tích một biến nào đó, hay tìm ra các tham số của mẫu dữ liệu, các số liệu thống kê được quan tâm ví dụ trung bình, phương sai, độ lệch chuẩn của các biến trong dữ liệu, thì pairwise deletion phù hợp hơn listwise deletion, vì nó lấy tối đa dữ liệu hiện có để phân tích.
Lấy lại ví dụ trên, chúng ta sẽ áp dụng thử pairwise deletion sau đó tìm thử trung bình, độ lệch chuẩn, so sánh với listwise deletion.
Chúng ta lấy lại bảng dữ liệu đã áp dụng listwise deletion cho trường hợp MCAR, sau đó cũng trường hợp MCAR này chúng ta áp dụng pairwise deletion. Tạm thời chúng ta chỉ xét biến đang cần xử lý missing values là hiệu suất công việc.
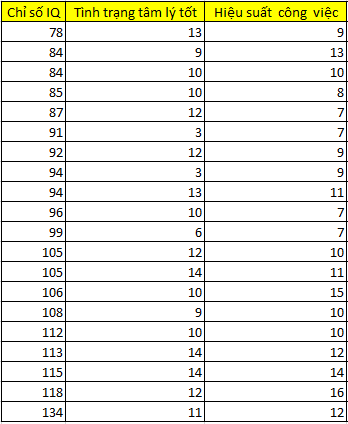
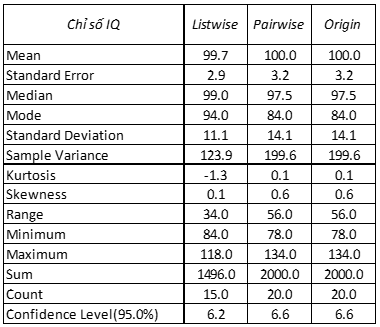
Các bạn quan sát ở dòng count tại 2 bảng thông tin biến tình trạng tâm lý tốt, và chỉ số IQ ở dưới đây, thì thấy phương pháp pairwise deletion giữ lại nhiều quan sát hơn so với listwise deletion. Ở biến chỉ số IQ, các tham số thống kê khi áp dụng pairwise deletion, giống với dữ liệu thực tế khi không bị missing và từ đó có thể đưa ra kết luận về đối tượng nghiên cứu chính xác. Còn ở biến tình trạng tâm lý tốt, mặc dù chỉ có 3 missing values, tức có 17 quan sát có giá trị tại biến này, nhưng khi áp dụng listwise deletion thì giảm xuống còn 13, còn áp dụng pairwise deletion thì bảo toàn được những giá trị còn lại trong tập dữ liệu. Các bạn cũng có thể thấy các tham số tại cột Pairwise deletion không chênh lệch nhiều so với cột Origin, tức gần bằng với dữ liệu thực tế không bị missing.
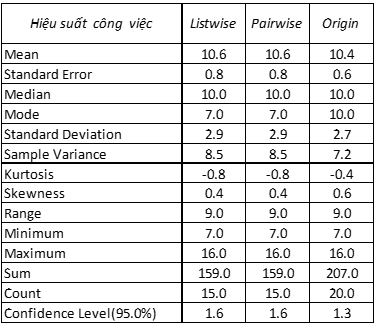
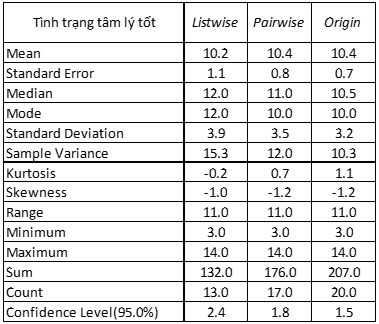
Như vậy qua đây có thể kết luận Pairwise deletion trong trường hợp mô tả dữ liệu thống kê sẽ được ưu tiên sử dụng hơn Listwise deletion.
Tiếp theo chúng ta cùng đi vào vấn đề lớn nhất của Pairwise deletion là nó ảnh hưởng đến kết quả phân tích mối quan hệ giữa các biến, dẫn đến các mô hình hồi quy, hoặc các thuật toán khác khi áp dụng vào phân tích sẽ gặp vấn đề do số quan sát tại các biến là khác nhau.
Công thức hệ số tương quan
Với Sxy, Sx, Sy lần lượt là hiệp phương sai giữa x, y, độ lệch chuẩn của x và y được tính như sau:
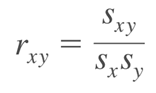
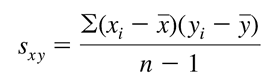
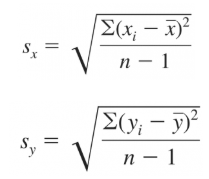
Dưới đây là kết quả hệ số tương quan đánh giá mối liên hệ giữa các biến, theo tập dữ liệu đầy đủ không bị missing.

Và đây là kết quả hệ số tương quan giữa các biến sau khi áp dụng Pairwise deletion, áp dụng cho bảng dữ liệu missing là MCAR ở trên.
Có 2 hướng tiếp cận trong việc tính hệ số tương quan giữa các biến: 1) tính hệ số tương quan cho các quan sát có đầy đủ giá trị ở tất cả các biến; 2) tính hệ số tương quan theo Sxy, Sx, Sy tính trên dữ liệu hiện có ở mỗi biến
Ở cách thức nhất: n = 13 là số quan sát có giá trị ở tất cả 3 biến sau khi áp dụng pairwise deletion loại bỏ missing values ở từng biến

Các bạn có thể thấy hệ số tương quan trường hợp này cao hơn nhiều so với tập dữ liệu không bị missing trong thực tế. Hơn nữa, ở tập dữ liệu đầy đủ, khi tính hệ số tương quan, chỉ số IQ và biến tình trạng tâm lý tốt có mối quan hệ không bền vững, còn ở trường hợp này thì khẳng định ngược lại, khi r = 0.511 cho rằng giữa chúng có mối quan hệ khá bền vững.
Ở cách thứ 2: tức chúng ta sẽ tính các Sx, Sy và Sxy giữa các cặp biến với dữ liệu hiện có trong tập dữ liệu không quan tâm đến missing values. Ví dụ Shiệu suất sẽ được tính dựa trên 15 quan sát có giá trị tại biến này, Stình trạng tâm lý cũng sẽ được tính trên 17 quan sát có giá trị tại biến này. Dưới đây là kết quả.

Các bạn có thể thấy hệ số tương quan giữa các biến của Pairwise deletion so với dữ liệu gốc không bị missing có xu hướng lớn hơn. Chỉ số IQ và Tình trạng tâm lý có hệ số tương quan ít khác biệt với kết quả dữ liệu gốc. May mắn là trong ví dụ này chúng không vượt quá 1 và -1 sẽ khiến kết quả phân tích không có ý nghĩa như một số tài liệu nghiên cứu của các chuyên gia khi đề cập đến khuyết điểm của Pairwise deletion với cách tính thứ 2 này.
Nguyên nhân dẫn đến sự sai lệch ở cách thứ 2 là do số quan sát chênh lệch giữa các biến vì missing values, còn cách thứ nhất là do kích thước mẫu quá nhỏ, không đủ để đưa ra kết quả có thể tin cậy. Tuy nhiên, các hệ số tương quan không vượt 1 và -1, và mức độ chênh lệch không quá bất hợp lý do trường hợp missing values đang áp dụng Pairwise là MCAR., nếu dữ liệu là MAR, thì có thể các hệ số tương quan dễ bị sai lệch nhiều hơn.
Một số chuyên gia, các hệ số tương quan sẽ không bị ảnh hưởng nhiều nếu áp dụng Pairwise deletion khi missing values là MCAR và các biến có mối tương quan kém bền vững và ngược lại. Các bạn nhìn lại kết quả hệ số tương quan của dữ liệu đầy đủ, có thể thấy không có hệ số tương quan nào lớn hơn 0.7 giữa 2 biến bất kỳ khác nhau (0.23, 0.54, 0.41)
Thế nhưng trong thực tế nếu dữ liệu bị missing quá nhiều, thì cho dù có xác định MCAR và áp dụng Listwise hay Pairwise, thì sẽ không có giá trị phân tích.
Còn nhiều vấn đề, khuyết điểm khác liên quan đến cả Listwise và Pairwise nói riêng và cả phương pháp Deletion, loại bỏ missing values nói chung, mà chúng ta khó có thể liệt kê ra hết. Mặt khác trường hợp dữ liệu missing là MCAR, thường không phổ biến để chúng ta áp dụng 2 phương pháp trên. Vì những lý do đó, một cách tiếp cận khác ra đời, mặc dù xuất hiện từ lâu, nhưng ngày càng được ứng dụng nhiều khi tính chất dữ liệu trở nên phức tạp hơn trước, hơn nữa đảm bảo kết quả phân tích sau cùng là hợp lý, và ít chịu ảnh hưởng từ vấn đề missing data, tuy nhiên lại phức tạp, và cần nhiều thời gian hơn so với deletion. Đó chính là “Imputation”, sử dụng nhiều phương pháp tính toán các giá trị để thay thế missing values. Bài viết cuối cùng về chủ đề Data cleaning – xử lý missing values, chúng tôi sẽ giới thiệu đến các bạn một cách đầy đủ nhất.
Mong các bạn tiếp tục ủng hộ BigDataUni.
Tài liệu tham khảo:
“Applied Missing Data Analysis: Methodology in the Social Sciences” của tác giả Craig K. Enders
“Best practices in Data cleaning” của tác giả Jason W. Osborne
“Missing data: a gentle introduction” của Patrick E. McKnight, Katherine M. McKnight, Souraya Sidani, Aurelio José Figueredo
“Handbook of statistical analysis and data mining applications” của Robert Nisbet, Gary Miner, Ken Yale
‘A Review of Methods for Missing Data – Educational Research and Evaluation” của Therese D. Pigott
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.