
 English
EnglishTiếp tục với chủ đề Association rules – khai phá luật kết hợp, ở các bài viết trước chúng ta đã tìm hiểu tổng quan, cách vận hành, chỉ tiêu đánh giá, hướng tiếp cận chính và đặc biệt là tìm hiểu thuật toán Apriori, cũng như những cách cải thiện quá trình phân tích luật kết hợp.
Đến với phần cuối cùng của chủ đề bài viết, BigDataUni sẽ review lại tỷ lệ support, confidence đặc biệt chi tiết hơn về lift, và các hạn chế của chúng, sau đó giới thiệu thêm đến các bạn những công thức đánh giá các luật kết hợp tìm được, sau cùng cùng nhau phân tích một ví dụ khác thử nghiệm khai phá Association rules.
*Lưu ý quan trọng: các bạn cần biết trước sơ lược về Association rules, và thuật toán Apriori thì mới có thể hiểu và nắm bắt nội dung nhanh chóng trong bài viết lần này.
Các bạn nào chưa biết có thể tham khảo ở những tài liệu liên quan khác hoặc những bài viết trước của chúng tôi theo link dưới đây:
Tổng quan về Association rules (P.1)
Tổng quan về Association rules (P.2)
Tổng quan về Association rules (P.3)

Phân tích luật kết hợp được ứng dụng phổ biến nhất trong lĩnh vực kinh doanh từ bán lẻ, đến thương mại điện tử và cả ngành tài chính, trên cơ sở tìm hiểu liệu khách hàng nếu mua sản phẩm A, B có tiếp tục mua sản phẩm C nào đó hay không, và những sản phẩm được phân tích chính xác sẽ cho ra các sự liên kết nhất định. Đây là cơ sở để các công ty có thể dự báo được hành vi tiêu dùng của khách hàng và hỗ trợ các hoạt động sales, marketing hiệu quả, mang lại nhiều giá trị kinh doanh.
Tuy nhiên tập dữ liệu về lịch sử giao dịch của mỗi công ty có thể sẽ khổng lồ, nếu lượng khách hàng mua hàng là rất lớn và số lượng ngành hàng, sản phẩm kinh doanh là rất nhiều và đa dạng.
Hàng triệu triệu luật kết hợp sẽ được tìm thấy nhưng để xác định luật kết hợp nào sẽ chính xác, xảy ra trong thực tế và đặc biệt là những luật kết hợp nào công ty cần chú ý dựa trên các tiêu chí về lợi nhuận, giá trị kinh doanh nhận được thì rất cần những phương pháp đánh giá khác bên cạnh 3 chuẩn chung là Support, Confidence và Lift như đã đề cập ở những bài viết trước.
Tóm lại sẽ có 2 nhóm tiêu chí đánh giá:
- Dựa trên công thức toán, và các suy luận thống kê về mối quan hệ giữa các item, giữa các sản phẩm, để xác định các luật kết hợp được cho là tối ưu, và ứng dụng vào thực tế. Các tiêu chí có thể kể đến như Support, Confidence, phân tích tương quan – Correlation,…
- Dựa trên mục đích nghiên cứu của chuyên gia phân tích hay nhà kinh doanh. Một luật kết hợp được quan tâm khi nó cung cấp những thông tin hữu ích giúp các công ty có thể thúc đẩy những hoạt động, chiến lược gia tăng lợi nhuận kinh doanh. Ví dụ Association rule giữa {sữa} và {bánh cookie} tuy đạt các yêu cầu về tỷ lệ support cao, và confidence cao, nhưng ít mang lại giá trị phân tích do thực tế công ty có thể suy luận ra. Mặt khác luật kết hợp giữa {sữa} và {mỳ cay} mặc dù tỷ lệ support thấp hơn, nhưng lại được quan tâm nhiều hơn do công ty có thể triển khai ỷ tưởng cross-selling 2 sản phẩm này.
Về lợi ích kinh doanh thì sẽ dựa theo mục đích đặc thù trong thực tế của các công ty, nên trong bài viết này chúng ta chỉ quan tâm các tiêu chí đo lường sử dụng công thức toán học và thống kê.
Nhắc lại một chút về tỷ lệ Support, Confidence và Lift
Gọi A, B là 2 tập phần tử – itemset, 2 nhóm sản phẩm (mỗi nhóm có tối thiểu 1 sản phẩm hay 1 item) mà một khách hàng mua, với A xảy ra trước hay còn gọi Antecedent, và B là các xảy ra sau, hay còn gọi Consequent. Hình thành quy luật hay luật kết hợp: “Nếu khách hàng mua A, thì sẽ mua B”. Luật kết hợp được chấp nhận khi đảm bảo:
- Phần lớn các khách hàng trong dữ liệu lịch sử giao dịch có mua cả A và B – tính phổ biến. Nếu ít khách hàng mua cả A và B, thì được coi là không phổ biến, không thể gọi là quy luật và ngược lại. Tần suất xuất hiện cả A và B trong tổng số những giao dịch, còn gọi là tỷ lệ Support.
Support = P(A ∩ B) = (Số giao dịch có chứa A và B)/ Tổng các giao dịch
- Nếu khách hàng mua A rồi mua B, nhưng tỷ lệ khách hàng mua A rồi mua C cao hơn thì chúng ta cũng chưa thể khẳng định khách hàng mua A thì sau đó khả năng cao sẽ mua B. Vậy chưa thể tự tin kết luận A => B là một luật kết hợp. Đây còn gọi là đánh giá tỷ lệ Confidence.
Confidence = P(A ∩ B)/ P(A) = (Số giao dịch có chứa A và B)/ Tổng các giao dịch có chứa A
- Lift được dùng để so sánh các luật kết hợp có chung Consequent hay nhấn mạnh vào tầm quan trọng của Antecedent. Ví dụ Lift tăng thì tỷ lệ khách hàng mua B là do mua A trước đó cao hơn tỷ lệ khách hàng mua B là do mua những sản phẩm khác trước đó. Hay tác động của A khiến khả năng khách hàng mua B cao hơn tác động của những sản phẩm còn lại.
Lift = Confidence/ P(B) = P(A ∩ B)/ [P(A).P(B)]
Theo công thức xác suất 2 sự kiện mua A, và mua B độc lập khi P(A ∩ B) = P(A)P(B). Nếu tỷ lệ lift gần bằng 1 thì nghĩa là 2 sự kiện này độc lập. Việc khách hàng mua A không làm thay đổi khả năng hay xác suất khách hàng mua B. Luật kết hợp không có ý nghĩa quan tâm. Lift lý tưởng sẽ phải lớn hơn 1, tức P(A ∩ B) > [P(A).P(B)]
* Cách giải thích khác về Lift dựa trên công thức: là có bao nhiêu lần khách hàng mua A rồi mua B nhiều hơn mong đợi nếu tập sản phẩm A và B là độc lập với nhau.
Ngoài ra Lift còn được gọi là chỉ số tương quan đơn giản của sự kiện A và B.
- Nếu Lift < 1, A và B tương quan âm, có mối quan hệ nghịch biến, khách hàng có khả năng mua A cao thì ít có khả năng mua B.
- Nếu Lift > 1, A và B tương quan dương, có mối quan hệ đồng biến, khách hàng mua A thì khả năng cao mua B
- Nếu Lift = 1, A và B không có mối tương quan với nhau, độc lập. Khách hàng mua A sẽ không tác động đến việc khách hàng có mua B hay không.
Ví dụ xác suất khách hàng mua mỳ gói là P(mỳ gói) = 0.8, xác suất khách hàng mua nước ngọt là P(nước ngọt) = 0.9, xác suất khách hàng mua cả mỳ gói và nước ngọt P(mỳ gói, nước ngọt) = 0.75. Theo công thức Lift = P(mỳ gói, nước ngọt)/ [P(mỳ gói)*P(nước ngọt)] = 0.75/0.9 * 0.8 = 1.04 > 1, như vậy có khả năng khách hàng mua mỳ gói thì sẽ mua nước ngọt nhưng không cao. Khả năng khách hàng mua nước ngọt do mua mỳ gói trước đó cao 1.04 lần so với những khách hàng mua nước ngọt mà không mua mì gói.
Để chọn lựa các itemset đạt yêu cầu chúng ta phải xác định mức tối thiểu cho Support và để chọn lựa các luật kết hợp đạt yêu cầu thì xác định mức tối thiểu cho Confidence. Sau cùng để tìm ra luật kết hợp tốt nhất để ứng dụng hỗ trợ các hoạt động sales, marketing thì cần dùng thêm Lift để so sánh
Mặc dù Lift cho thấy độ hiệu quả trong việc đánh giá và chọn lựa những luật kết hợp nhưng nó luôn kết hợp thêm các tiêu chí Support, Confidence và cả mục đích kinh doanh của công ty.
Ví dụ một luật kết hợp có tỷ lệ support cao hơn nhưng lift thấp hơn cũng có thể được công ty quan tâm do công ty chỉ cần biết nhiều khách hàng mua 2 hay nhiều sản phẩm cùng nhau để tập trung các hoạt động marketing. Hay cũng có thể ngược lại, để hỗ trợ cross-sell hiệu quả, các luật kết hợp có confidence hay lift cao hơn sẽ được quan tâm nhiều hơn vì nó thể hiện liên kết của các sản phẩm.
Hạn chế của Support, Confidence
Mặc dù là các tiêu chí đánh giá quan trọng nhất trong Association rules nhưng khi sử dụng chúng ta phải tránh mắc những cái bẫy do chính chúng tạo ra. Cái bẫy đó là gì chúng ta cùng nhìn qua ví dụ dưới đây:
Theo một cửa hàng thiết bị điện tử giải trí có 2000 giao dịch, trong đó có 1200 khách hàng mua CD games trên PC và 1500 khách hàng mua Video games, và 800 khách hàng mua cả 2 CD games và Video games. Một luật kết hợp tìm được CD games => Video games, và luật kết hợp này đảm bảo yêu cầu về tỷ lệ support, confidence tối thiểu.
Support = 40% , Confidence = 66.67%
Tỷ lệ support, và confidence là cao, nếu dựa trên 2 tiêu chí này, thông thường cửa hàng sẽ đưa luật kết hợp này áp dụng vào thực tế tuy nhiên nhìn kỹ lại chúng ta có thể thấy, Support của Video games là rất cao đến 75%, cao hơn nhiều so với khi mua CD games trước đó, hay nói cách khác, mua CD games giảm khả năng mua Video games từ 75% xuống 66.67%. Hơn nữa, sự thật là khả năng mua CD games và Video games sẽ tỷ lệ nghịch với nhau, ví dụ nếu bạn đã có một con PC xịn để chơi CD games, và kết nối luôn tay cầm để tăng trải nghiệm thì liệu bạn có mua Video games để chơi trên Play station? Vì thế luật kết hợp có Confidence cao thường sẽ là cái bẫy lớn nếu chúng ta so sánh với chính tỷ lệ support của Consequent, vế sau của luật kết hợp.
Đó là lí do chúng ta cần sử dụng thêm Lift ở trên hay các chỉ tiêu khác dưới đây để đánh giá, đặc biệt là Correlation analysis, sẽ cho ta thấy rõ hơn mối liên hệ giữa A và B.
Lift sẽ bằng 0.89, nhỏ hơn 1, khẳng định thêm về mối quan hệ nghịch biến giữa CD games và Video games.
Các phương pháp đánh giá khác ngoài Support, Confidence, Lift
Leverage
Một phương pháp đánh giá khác là tìm chỉ số đòn bẩy, hay còn gọi Leverage. Leverage được tính dựa trên các tỷ lệ support. Tương tự gọi A, B là 2 tập phần tử – itemset, 2 nhóm sản phẩm (mỗi nhóm có tối thiểu 1 sản phẩm hay 1 item) mà một khách hàng mua, với A xảy ra trước hay còn gọi Antecedent, và B là các xảy ra sau, hay còn gọi Consequent.
Leverage = Support (A =>B) – Support (A)*Support (B)
Nếu A và B là 2 sự kiện độc lập thì tần suất xuất hiện của A và B cùng lúc trong một giao dịch sẽ là phép nhân của tỷ lệ Support (A) và tỷ lệ Support (B).
Giá trị Leverage của một luật kết hợp sẽ luôn nhỏ hơn chính tỷ lệ support của nó. Về tính chất, Leverage giúp chúng ta giảm bớt những luật kết hợp đảm bảo tỷ lệ Support, tỷ lệ Confidence.
Leverage đo lường sự khác biệt trong tỷ lệ support (A, B) và tỷ lệ support của A và B nếu chúng độc lập. Leverage bằng 0 khi A và B thực sự độc lập
Ví ở trên tỷ lệ support của (mỳ gói, nước ngọt) = P(mỳ gói ∩ nước ngọt) = 0.75. Tỷ lệ support của mỳ gói P(mỳ gói) = 0.8, P(nước ngọt) = 0.9. Leverage = 0.75 – 0.9*0.8 = 0.03.
0.03 được hiểu là mức độ cải thiện trong tỷ lệ support của luật kết hợp so với tỷ lệ support mỳ gói và nước ngọt khi chúng độc lập (0.72). Công ty mong muốn khách hàng mua cả 2 sản phẩm mỳ gói, và nước ngọt, khi chúng độc lập, thì xác suất khách hàng mua cả 2 sẽ là 0.72, 72%, tuy nhiên thực tế vượt hơn mong đợi, là 3%
Leverage cũng giống như Support, và Confidence đều có giá trị tối thiểu, hay Threshold, để làm cơ sở loại bỏ luật kết hợp không đạt yêu cầu.
Trong lĩnh vực kinh doanh, ở mang sales, Leverage dùng để tìm ra doanh số của 2 hay nhiều sản phẩm bất kỳ có cao hơn doanh số nếu bán chúng riêng lẻ hay không.
Conviction
Một chỉ tiêu đo lường khác chính là hệ số Conviction:
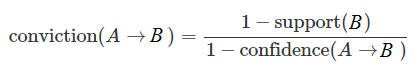
Hệ số nhấn mạnh vào mức độ phụ thuộc của Consequent tức B vào Antecedent là A, hệ số càng cao thì mức độ phụ thuộc càng cao.
Conviction(A -> B) = P(A)P(not B)/P(A và not B) = (1-support(B))/(1-confidence(A -> B))
Conviction đo lường xác suất xuất hiện A mà không có B nếu chúng độc lập so với xác suất xuất hiện A và không có B trong thực tế. Nếu Conviction càng lớn, thì luật kết hợp càng được chọn, do Confidence càng tiến về 1, thì Conviction càng lớn, khi support của Consequent không thay đổi. Conviction được các chuyên gia cho là có thể thay thế Confidence khi nó nắm bắt được đầy đủ hướng đi của các liên kết hơn.
Ví dụ Conviction (mỳ gói => nước ngọt) = 1 – support (nước ngọt)/ 1 – confidence (mỳ gói => nước ngọt) = (1 – 0.9)/1 – [(0.75/ 0.8)] = 1.6. Conviction bằng 1 chứng tỏ A và B độc lập, khách hàng mua mỳ gói không tác động lên khả năng họ có mua nước ngọt hay không.
Conviction thực chất đánh giá luật kết hợp theo hướng ngược lại với chỉ số Lift.
Lift = Confidence/ P(B) = P(A ∩ B)/ [P(A).P(B)]
Conviction = [P(A).P(not B)]/ P(A ∩ not B)
Bảng Contigency 2 chiều – Bảng tương quan 2 chiều
Đáng lẽ phần này được đưa lên nói đầu tiên, trước cả phần lift do lift là hệ số tương quan đơn giản đánh giá các luật kết hợp nhưng tránh để nội dung cơ bản ban đầu về Assoication rules trở nên phức tạp, khiến các bạn bị rối khi nắm bắt nên chúng tôi để lại đến lúc này mới trình bày.
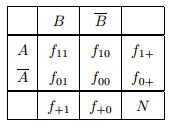
Bên trên là bảng mẫu Contigency của 2 biến A và B hay 2 tập itemset. Ký hiệu gạch ngang trên đầu của A và B, thể hiện “không có A” và “không có B” trong giao dịch, f là ký hiệu cho tần số, số lần xuất hiện. Ví dụ f11 là số giao dịch xuất hiện cả A và B, f10 số giao dịch xuất hiện A nhưng không có B, f01 số giao dịch xuất hiện B nhưng không có A, f00 số giao dịch cả A và B đều không có xuất hiện bên trong.
Còn f1+ là tổng số các giao dịch xuất hiện A, f0+ là tổng số các giao dịch không có chứa A. Xét tương tự cho f+1 và f+0 cho B.
Công thức Lift dựa trên bảng Contigency sẽ là:
Lift = P(A ∩ B)/ [P(A).P(B)] = (f11/N)/[(f1+/N)*(f+1/N) = N*f11/(f1+*f+1)
Công thức Conviction dựa trên bảng Contigency sẽ là:
Conviction = [P(A).P(not B)]/ P(A ∩ not B) = (f1+ * f+0) /(N*f10)
Chi tiết phần Lift các bạn xem lại ở trên, giờ chúng ta sẽ tiếp đến một công thức đánh giá luật kết hợp khác sử dụng phân tích tương quan.
Correlation analysis
Phân tích tương quan hay Correlation analysis đã được chúng tôi nhắc đến trong các bài viết về phân tích hồi quy (Regression analysis). Phân tích tương quan sử dụng hệ số tương quan Pearson kết hợp kiểm đinh để kết luận 2 biến bất kỳ có mối quan hệ (thuận, nghịch) với nhau hay không.
Phân tích tương quan được sử dụng ở bước đầu phương pháp hồi quy và giờ đây có thể áp dụng cho Association rules với Antecedent và Consequent lúc này sẽ đóng vài 2 biến.
Đối với 2 biến định lượng trong hồi quy thì chúng ta dùng hệ số tương quan Pearson, còn trong Association rules 2 biến A, B là biến Flag, hay biến nhị phân chỉ có giá trị 0 và 1, tần số xuất hiện được tính bằng cách đếm, và thống kê, nên hệ số tương quan ký hiệu φ được tính như sau:
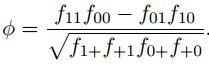
Ví dụ
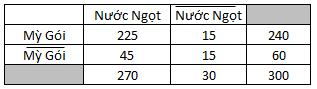
Hệ số tương quan = [(225*15) – (45*15)]/ căn 2(270*240*30*60) = 0.25
- Nếu hệ số < 0, thì 2 sản phẩm hoặc 2 itemset có mối quan hệ theo chiều nghịch nhau, tức một cái có khả năng tăng thì các còn lại sẽ giảm hoặc ngược lại.
- Hệ số > 0 thì 2 sản phẩm hoặc 2 itemset có mối quan hệ thuận, một cái tăng, cái còn lại có thể tăng theo hoặc ngược lại.
- Hệ số = 0, thì cả 2 không có mối quan hệ tuyến tính với nhau.
- Hệ số càng tiến gần giá trị -1, mối liên hệ nghịch càng chắc chắn, tương tự với giá trị 1, mối liên hệ thuận càng chắc chắn.
Như vậy theo kết quả trên, Nước ngọt và Mỳ gói có mối tương quan thuận với nhau, giả sử theo luật kết hợp (Mỳ gói => Nước ngọt) tìm được thì có thể nói khả năng khách hàng mua mỳ càng cao thì khả năng họ mua nước ngọt cũng sẽ tăng.
Chỉ số IS
Một công thức khác để đánh giá luật kết hợp chính là hệ số IS với công thức như sau:
IS (A, B) = (Lift (A, B)*Support(A, B))1/2 = Support (A, B)/ (Support (A)* Support (B))1/2
Luật kết hợp có hệ số Lift lớn và tỷ lệ Support lớn thì chứng tỏ hệ số IS sẽ phải lớn, chúng ta lấy cơ sở này để đánh giá.
Ngoài ra, chỉ số IS được dùng để đánh giá chung cho 2 luật kết hợp theo dạng đối xứng của itemset A và B.
IS (A, B) = [(Support(A, B)/Support(A))*(Support(A, B)/Support(B))]1/2
= [Confidence (A=>B)* Confidence (B=>A)]1/2
Các bạn thử áp số vào công thức sử dụng bảng mẫu contigency mỳ gói x nước ngọt ở trên để tự tính thử nhé, mục đích làm quen với công thức thôi!
Giải thích về thuật ngữ đối xứng:
Các phương pháp đánh giá Association rules sử dụng thống kê và công thức toán học còn được thành 2 phần chính:
- Đánh giá 1 chiều, bất đối xứng, tức công thức đánh giá 2 luật kết hợp sẽ mang lại giá trị khác nhau
- Đánh giá 1 chiều, đối xứng, tức công thức đánh giá 2 luật kết hợp sẽ mang lại giá trị như nhau.
Ví dụ: gọi X là 1 phương pháp đánh giá nào đó:
- Đối xứng là khi X( A => B) = X(B => A)
- Bất đối xứng là khi X(A => B) ≠ X(B => A)
Confidence và Conviction là phương pháp đánh giá bất đối xứng, các bạn nhìn lại công thức sẽ thấy rõ. Confidence và Conviction của (A => B) sẽ khác với (B =>A)
Lift và Correlation, hệ số tương quan ở trên, là dạng đối xứng, giá trị hệ số (A => B) sẽ bằng với (B =>A)
Ở nhiều trường hợp đối xứng sẽ rất quan trọng ví dụ nếu tập dữ liệu không xác định được itemset nào được mua trước, itemset nào mua sau, chúng ta không biết luật kết hợp sẽ là A=>B, hay B=>A, nên sẽ cần phương pháp đánh giá chung độ hiệu quả cho cả 2 luật kết hợp này. Khi giá trị từ công thức đánh giá cho rằng luật kết hợp là tốt vậy chúng ta có thể kết luận A=>B cũng tốt, và B=>A cũng tốt
Trường hợp tập dữ liệu xác định được trình tự khách hàng mua hàng, thì chúng ta không cần đặt nặng vấn đề lên các phương pháp đối xứng.
Dưới đây liệt kê một số những công thức đánh giá luật kết hợp khác mà các bạn có thể nghiên cứu thêm, bài viết có giới hạn nên chúng tôi tạm dừng phần đánh giá ở đây để sang phần ví dụ review Association rules lần cuối trước khi kết thủ chủ đề này.
- Phương pháp đánh giá đối xứng: Tỷ số Odds, Hệ số Kappa (k), Piatetsky-Shapiro (PS), Collective Strength (S), hệ số Jascard,…
- Phương pháp đánh giá bất đối xứng: phương pháp Goodman-Kruskal, hệ số J (J-measure), hệ số Gini, Laplace (L),…
Các bạn có thể tự kiếm tài liệu hoặc tham khảo qua link gợi ý của chúng tôi dưới đây của giáo sư Micheal Hashler, một bài blog có thể coi là tổng hợp đầy đủ nhất tất cả các phương pháp đánh giá Association rules:
Ví dụ phân tích Association rules
Ở những bài viết trước chúng ta đã làm quen với Association rules sử dụng mẫu dữ liệu nhỏ, gọn, đơn giản để tiện trình bày lý thuyết nhanh chóng, và để các bạn hình dung rõ hơn về phương pháp này.
Để kết thúc series đầu tiên về Association rules một cách trọn vẹn chúng ta cùng đi vào một ví dụ khác với tập dữ liệu lớn hơn.
Một cửa hàng bán lẻ có mẫu dữ liệu lịch sử 1000 giao dịch của khách hàng. Mẫu dữ liệu như sau, ví dụ tham khảo từ IBM
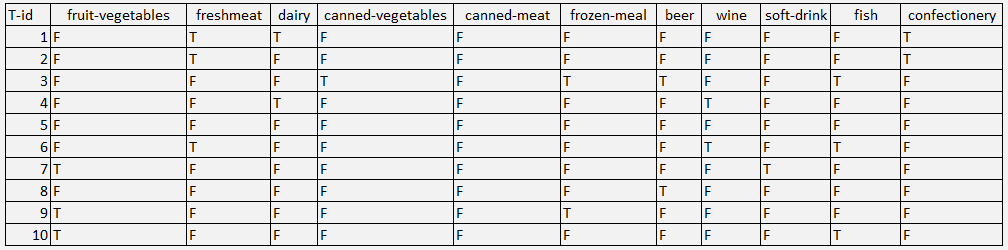
Các bạn có thể download dữ liệu mẫu ở đây: Google drive
Mẫu dữ liệu có 12 biến, biến đầu tiên là thứ tự các giao dịch, các biến còn lại là 11 sản phẩm:
- Fruit-vegetables: rau, củ, quả, trái cây
- Fresh meat: thịt tươi sống
- Dairy: các sản phẩm bơ, sữa
- Canned-vegetables: rau củ đóng hộp
- Canned-meat: thịt đóng hộp
- Frozen-meal: thức ăn đông lạnh
- Beer: bia
- Wine: rượu
- Soft-drink: thức uống giải khát
- Fish: cá
- Confectionery: bánh kẹo nói chung
Tần số xuất hiện theo từng sản phẩm
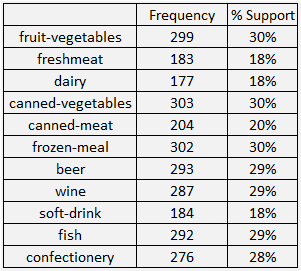
Tỷ lệ Support tối thiểu cho ví dụ này là 10%
Tỷ lệ Confidence tối thiểu là 80% cho các luật kết hợp tìm được từ 3-itemset
Tiếp theo chúng ta xác định các 2-itemset, 2 sản phẩm mà khách hàng mua cùng lúc.
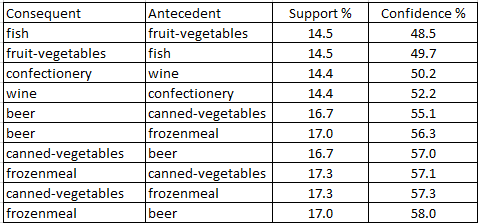
Kết quả như bảng dưới đây, sắp xếp theo thứ tự tăng dần của tỷ lệ Support. Tổng cộng có 55 2-itemsets, và có 110 luật kết hợp từ 55 2-itemsets tìm được.
Chúng ta sẽ lọc tiếp theo tiêu chí tỷ lệ Support. Lưu ý tỷ lệ Confidence ở đây chưa xét được.
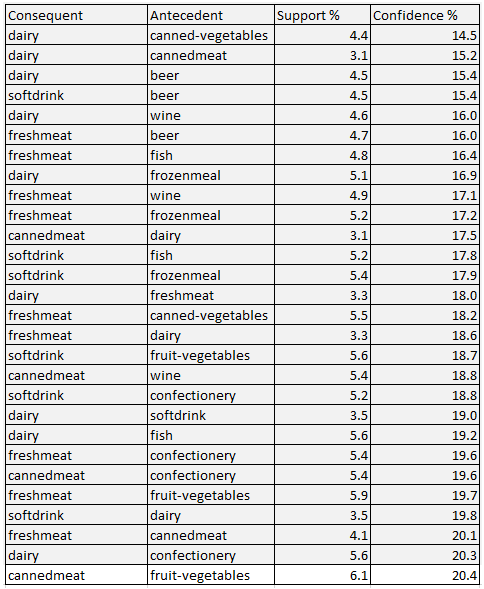
Các 2-itemset và luật kết hợp đạt yêu cầu về tỷ lệ Support trên 10%

Để nhìn rõ hơn chúng ta có thể sử dụng Web-graph, đồ thị lưới của phần mềm IBM Spss Modeler. Các đường nối càng đậm thể hiện tần số xuất hiện của 2 sản phẩm cùng nhau là lớn. Các bạn nhìn ở bản trên và đối chiếu với đồ thị sẽ nhận thấy được ngay.
Từ các 2-itemset đạt yêu cầu chúng ta sẽ xác định các 3-itemset, và các luật kết hợp xác định được. Trong ví dụ này các luật kết hợp được hình thành theo cấu trúc: {A, B} => {C}. Phần Antecedent sẽ bao gồm 2 sản phẩm mà thôi, và phần Consequent sẽ chỉ có 1 sản phẩm.


Như vậy chúng ta sẽ có 3 luật kết hợp tìm được từ 1 3-itemset duy nhất đảm bảo tỷ lệ Support, và Confidence
“Nếu khách hàng mua bia, thức ăn đông lạnh thì sẽ mua rau củ, quả đóng hộp”
“Nếu khách hàng mua thức ăn đông lạnh, rau củ quả đóng hộp thì sẽ mua bia”
“Nếu khách hàng mua bia, rau củ quả đóng hộp, thì sẽ mua thức ăn đông lạnh”
Công việc tiếp theo dành cho các bạn đây. Hãy tính toán thử các chỉ số Lift, Leverage, Conviction, và hệ số tương quan cũng như hệ số IS, để đưa ra kết luận sau cùng. Liệu 3 luật kết hợp trên có thể áp dụng vào thực tế?
Đến đây là kết thúc series đầu tiên về Association rules với thuật toán Apriori. Hẹn gặp lại các bạn ở các series khác về Association rules với các thuật toán, phương pháp phân tích cải tiến hơn.
Tài liệu tham khảo:
“Introduction to Data mining” – Pearson, tác giả Tan, Steinbach, Kumar
“Data Mining Concepts and Techniques” – Jiawei Han, Micheline Kamber, Jian Pei
“Data mining and predictive analytics” – Daniel T. Larose
“Principles of Data mining” – Max Bramer
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.