
 English
EnglishTrở lại với chủ đề bài viết về thuật toán cây quyết định, ở bài viết trước BigDataUni đã giới thiệu đến các bạn tổng quan thế nào là Decision Tree, các công thức quan trọng để xác định cách phân nhánh tối ưu hay nói cách khác là đem lại kết quả phân loại (classification) chính xác dựa trên các thuộc tính dữ liệu và đặc biệt là thuật toán CART (classification and regression tree) sử dụng công thức “Goodness of Split”. Trong bài viết lần này, chúng ta sẽ tiếp tục đi vào tìm hiểu các phương pháp xây dựng thuật toán Decision tree, CART với ví dụ phức tạp sử dụng công thức Gini index. (cho biến định tính, còn biến định lượng chúng tôi sẽ gửi đến các bạn trong các bài viết sắp tới.)
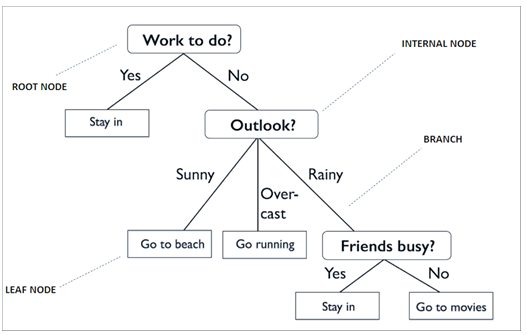
(Nguồn hình Towardsdatascience)
Nhắc lại một số kiến thức về cây quyết định trong bài viết trước:
Decision Tree là một thuật toán thuộc loại Supervised Learning, phương pháp học có giám sát, kết quả hay biến mục tiêu của Decision Tree chủ yếu là biến phân loại. Các thuật toán được xây dựng giống hình dạng một các cây có ngọn cây, thân cây, lá cây kết nối bằng các cành cây, và mỗi thành phần đều có ý nghĩa riêng của nó, như các yếu tố tác động lên quyết định sau cùng.
Một cây quyết định bao gồm:
- “Root node”: điểm ngọn chứa giá trị của biến đầu tiên được dùng để phân nhánh.
- “Internal node”: các điểm bên trong thân cây là các biến chứa các giá trị dữ liệu được dùng để xét cho các phân nhánh tiếp theo
- “Leaf node”: là các lá cây chứa giá trị của biến phân loại sau cùng.
- “Branch” là quy luật phân nhánh, nói đơn giản là mối quan hệ giữa giá trị của biến độc lập (Internal node) và giá trị của biến mục tiêu (Leaf node).
Lưu ý trong bài viết này chúng tôi sẽ nhắc nhiều đến chữ “thuộc tính”, ở đây chúng tôi quy định “thuộc tính” là giá trị của biến dữ liệu bất kỳ để xét cho điểm hay đối tượng dữ liệu. Ví dụ khách hàng A và khách hàng B trong tập dữ liệu đề có khả năng “có rủi ro tín dụng”, vậy tức họ có chung thuộc tính ” có rủi ro tín dụng” mà “có rủi ro tín dụng” là 1 giá trị của biến mục tiêu “rủi ro tín dụng” (giá trị còn lại “không rủi ro tín dụng”). Theo thuật ngữ chuyên ngành dữ liệu thì “thuộc tính” gần giống các biến dữ liệu do đó sẽ có các bạn thắc mắc nên chúng tôi lưu ý ngay trong phần đầu bài viết. Mục đích chúng tôi sử dụng từ “thuộc tính” là tránh lặp quá nhiều từ “giá trị”, khiến bài viết bị lủng cùng.
Xét về khía cạnh trong lĩnh vực dữ liệu, hồi quy (regression) và phân loại (classification) là hai phương pháp Data mining có thể được thực hiện thông qua Decision tree hay nói cách khác Decision tree có thể được áp dụng cho cả 2 dạng phân tích trong các dự án nghiên cứu khác nhau. Vì tính chất này mà khi nhắc đến Decision tree, cây quyết định, thông thường thì người ta thường gọi Classification & Regression Tree viết tắt là CART.
Xét về số nhánh thì có 2 dạng cây quyết định bao gồm cây chỉ phân được 2 nhánh và cây phân được nhiều nhánh khác nhau. Về dạng cây phân được nhiều nhánh, thì phổ biến hiện nay có CHAID, và C4.5, C5.0 là các thuật toán xây dựng Decision tree nhiều nhánh, còn CART thông thường được dùng cho dạng cây phân được 2 nhánh mỗi lần.
Cây quyết định là một trong những thuật toán phổ biến và quan trọng nhất trong Data mining, được dùng để dự báo, hay phân loại đối tượng dữ liệu vào các lớp, các nhóm phù hợp (class) của biến mục tiêu, dựa vào các biến dự báo, biến độc lập. Ưu điểm trực quan dễ nhìn, dễ hiểu và dễ giải thích dựa trên nguyên lý IF – THEN – ELSE (nếu … thì) khiến cho Decision tree hấp dẫn không chỉ đối với những nhà phân tích mà còn những nhà kinh doanh khi họ sử dụng kết quả phân tích phục vụ cho việc ra quyết định. Hoạt động bằng cách phân tập dữ liệu thành các tập nhỏ có chứa những giá trị khác nhau của biến mục tiêu, sao cho các đối tượng dữ liệu thuộc mỗi tập đều đồng nhất về một thuộc tính bất kỳ. Xét trên mô hình cây quyết định, tức là chúng ta phải tìm ra các leaf node “thuần túy”, “đồng nhất” nhất, đây là cơ sở và tiêu chí để chúng ta phân nhánh cho cây quyết định. Ở bài viết trước chúng ta đã làm quen với các công thức tính toán tính mức độ đồng nhất “Purity” của mỗi node, để tìm ra cách thức phân nhánh tối ưu nhất bắt đầu với công thức “Goodness of split”. Còn trong bài viết lần này chúng ta sẽ cùng nhau nghiên cứu về hệ số Gini Index, và cách triển khai công thức để xây dựng cây quyết định CART.
Để hiểu các kiến thức được trình bày trong bài viết này các bạn nên nắm cơ bản Classification là gì, thuật toán cây quyết định là gì và cách vận hành của nó, các bạn có thể tham khảo các tài liệu bên ngoài, hoặc xem qua bài viết của chúng tôi theo link dưới đây:
Thuật toán KNN và ví dụ đơn giản trong ngành ngân hàng
Thuật toán cây quyết định (P.1): Classification & regression tree
Các thuật ngữ về Decision tree, thuật toán CART là gì, và cách triển khai nó bằng công thức Goodness of split các bạn cũng có thể tham khảo bài viết của chúng tôi ở link trên.
CART sử dụng công thức Gini Index
Tiếp tục với chủ đề cây quyết định, chúng ta sẽ làm quen với công thức Gini Index tiếp tục sử dụng cho thuật toán CART để phân loại đối tượng dữ liệu.
So với công thức mà chúng tôi giới thiệu ở bài viết trước, thì Gini Index thường được sử dụng phổ biến hơn bởi các chuyên gia phân tích. Theo Wikipedia (Eng ver) Công thức Gini Index là phương pháp hướng đến đo lường tần suất một đối tượng dữ liệu ngẫu nhiên trong tập dữ liệu ban đầu được phân loại không chính xác, trên cơ sở đối tượng dữ liệu đã nằm trong một tập con được phân ra từ tập dữ liệu ban đầu, có dán nhãn thể hiện thuộc tính chung bất kỳ của các đối tượng còn lại trong tập con này, giá trị phân loại chính là nhãn của tập con.
Gini index cũng chính là chỉ số đo lường mức độ đồng nhất, hay mức độ nhiễu loạn thông tin, hay sự khác biệt về các giá trị mà mỗi điểm dữ liệu trong một tập hợp con, hoặc một nhánh (node) trên cây quyết định có. Công thức Gini ngoài việc áp dụng cho biến định tính (categorical variable), còn có thể dùng cho biến định lượng (continuous variable)
Trên cơ sở tính toán, Gini index cho phép chúng ta đánh giá sự tối ưu của từng cách phân nhánh thông qua xác định mức độ “purity” của từng node trong mô hình cây quyết định. Nếu tất cả các quan sát, điểm dữ liệu thuộc về một node và có chung 1 thuộc tính bất kỳ thì node này thể hiện sự đồng nhất và không có nhiễu loạn thông tin, lúc này hệ số Gini của node sẽ bằng 0. Ngược lại nếu tất cả các quan sát không có cùng 1 thuộc tính nào đó, khác biệt nhau, và nằm cùng 1 node thì lúc này hệ số Gini sẽ lớn, và lớn nhất bằng 1, sẽ gây khó khăn cho việc phân nhánh, và cây quyết định sẽ trở nên phức tạp, hỗn độn.
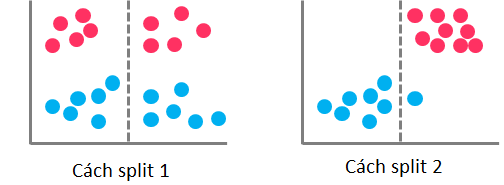
Như ví dụ trên hình cách phân nhánh thứ nhất không được tối ưu khi các điểm dữ liệu chứa 2 thuộc tính khách nhau nằm trong cùng 1 bên, hệ số Gini sẽ cao, còn cách phân nhánh thứ 2 thì tối ưu hơn, các điểm màu xanh gần như đang nằm cùng 1 phía, tương tự các điểm màu đỏ, hệ số Gini sẽ thấp.
Công thức tổng quát của hệ số Gini
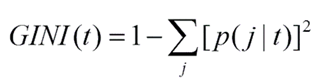
t là một node bất kỳ có chứa các điểm dữ liệu mang thuộc tính j của biến mục tiêu và p chính là xác suất để một điểm dữ liệu trong t có thuộc tính j, nếu tất cả các điểm dữ liệu đều mang thuộc tính j thì lúc này p = 1 và Gini(t) sẽ bằng 0, node t chính thức được công nhận là “pure” node.
Do hệ số Gini được dùng cho thuật toán CART mà CART giới hạn mỗi lần chỉ phân được tối đa 2 nhánh nên ví dụ một biến có 3 thuộc tính, 3 giá trị định tính như thu nhập = {cao, trung bình, thấp} chúng ta sẽ có 2 mũ 3 tức 8 subset, tập con có thể chia: {cao, trung bình, thấp}, {cao, thấp}, {cao, trung bình}, {trung bình, thấp}, {cao}, {thấp}, {trung bình}, {}. Chúng ta loại bỏ cách chia {cao, trung bình, thấp}, {} tức còn 2v – 2 tập con, cách phân nhánh trên cây quyết định đối với một biến dữ liệu bất kỳ.
Công thức trên để tính độ đồng nhất của một node, vậy khi chúng ta có nhiều cách phân nhánh, mỗi cách có thể phân ra một số node nhất định, tức có thể chia tập dữ liệu thành các tập con khác nhau theo các giá trị của biến dữ liệu, lúc này chúng ta có thêm công thức thứ 2 để tìm ra cách “split” tối ưu nhất.
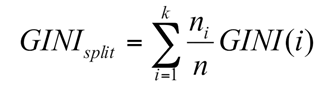
Với ni là số quan sát, số điểm dữ liệu có trong “child node”, node của nhánh được phân, còn n là số qua sát, số điểm dữ liệu có trong “parent node”, node được dùng để phân nhánh. Hệ số Gini split càng nhỏ tức cách phân nhánh càng tối ưu.
Để hiểu rõ hơn về cách triển khai công thức chúng ta cùng lấy lại ví dụ phân loại khách hàng có khả năng rủi ro tín dụng, hay không có rủi ro tín dụng và sử dụng công thức Gini để phân nhánh. Ví dụ dưới đây phức tạp hơn ví dụ ở bài viết trước khi chúng ta có nhiều biến cần xét hơn.
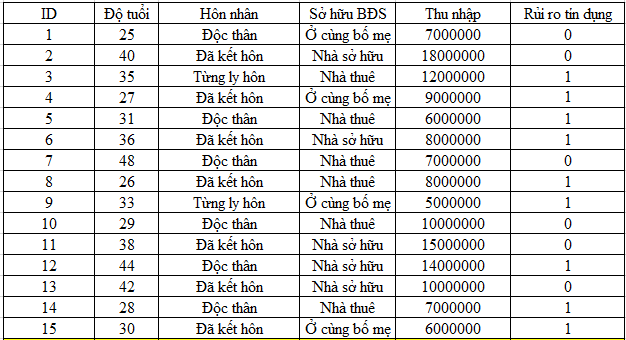
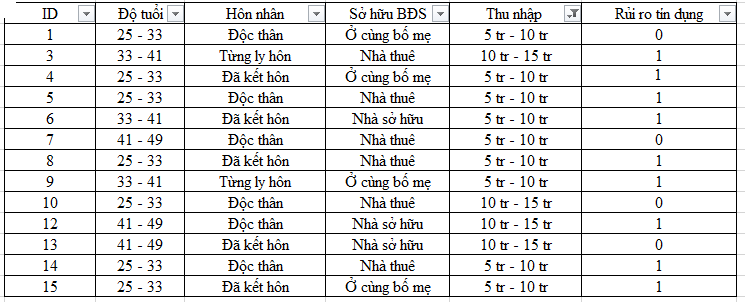
Dữ liệu mẫu về khách hàng đã từng mở khoản vay tại ngân hàng và đã được phân loại rủi ro tín dụng dựa trên cơ sở các khách hàng này đã trả nợ và lãi đúng hạn hay không đúng hạn
Giả sử chúng ta có bộ dữ liệu mẫu như trên với các biến dự báo, biến phân loại bao gồm độ tuổi, tình trạng hôn nhân, tình trạng sở hữu bất động sản, thu nhập, và biến mục tiêu là rủi ro tín dụng.
Đối với dữ liệu độ tuổi và thu nhập chúng ta sẽ tiến hành phân nhóm để chuyển đổi giá trị dữ liệu của 2 biến định định lượng thành giá trị định tính. Chúng ta có thể áp dụng công thức phân nhóm trong thống kê như sau:
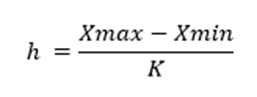
Với K = (2 x n)1/3 , vậy với độ tuổi chúng ta có thể phân thành các nhóm như sau, với số nhóm là K = 3 khi n =15, khoảng cách mỗi giá trị đầu và cuối trong một nhóm là 8.
- 25 – 33 tuổi (không tính khách hàng có tuổi là 33)
- 33 – 41 tuổi (không tính khách hàng có tuổi là 41)
- 41 – 49 tuổi (không tính khách hàng có tuổi là 49)
Tương tự với dữ liệu thu nhập chúng ta cũng tiến hành phân nhóm, với số nhóm là 3, và khoảng cách giá trị đầu và cuối là 5.000.000.
- 5.000.000 đ – 10.000.000 đ (không tính khách hàng có thu nhập là 10.000.000 đ)
- 10.000.000 đ – 15.000.000 đ (không tính khách hàng có thu nhập là 15.000.000 đ)
- 15.000.000 đ – 20.000.000 đ (không tính khách hàng có thu nhập là 20.000.000 đ)
Như vậy chúng ta sẽ có bảng dữ liệu mới như sau:
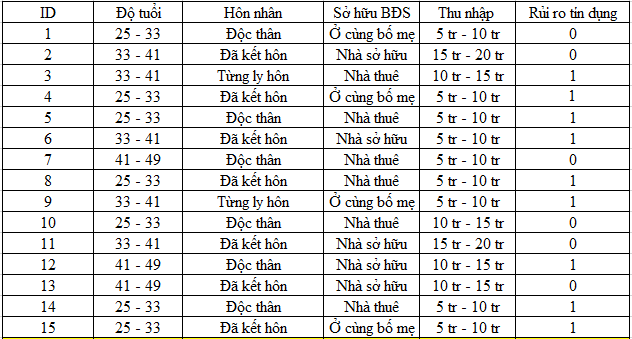
Tiếp theo, tương tự như xây dựng cây quyết định CART sử dụng công thức “Goodness of split” chúng ta cũng sẽ đầu tiên đi tìm root node, biến dữ liệu nào sẽ ở đầu cây quyết định.
- Độ tuổi
Chúng ta xét bên trong từng nhóm tuổi có bao nhiêu khách hàng có rủi ro tín dụng và không có rủi ro tín dụng để lập bảng
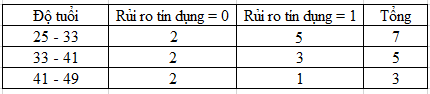
Gini (Độ tuổi = 25-33) = 1 – (2/7)2 – (5/7)2 = 0.408
Gini (Độ tuổi = 33-41) = 1 – (2/5)2 – (3/5)2 = 0.48
Gini (Độ tuổi = 41-49) = 1 – (2/3)2 – (1/3)2 = 0.444
GiniSplit (Độ tuổi) = (7/15)*0.408 + (5/15)*0.48 + (3/15)*0.444 = 0.439
- Tình trạng hôn nhân
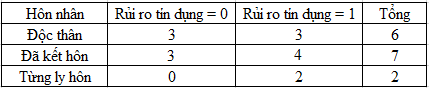
Gini (tình trạng hôn nhân = Độc thân) = 1 – (3/6)2 – (3/6)2 = 0.5
Gini (tình trạng hôn nhân = Đã kết hôn) = 1 – (4/7)2 – (3/7)2 = 0.489
Gini (tình trạng hôn nhân = Từng ly hôn) = 1 – (0/2)2 – (2/2)2 = 0
GiniSplit (tình trạng hôn nhân) = (6/15)*0.5 + (7/15)*0.489 + (2/15)*0 = 0.4282
- Sở hữu bất động sản
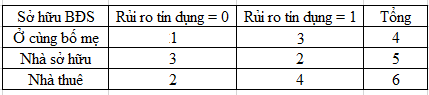
Gini (sở hữu BĐS = Ở cùng bố mẹ) = 1 – (1/4)2 – (3/4)2 = 0.375
Gini (sở hữu BĐS = Nhà sở hữu) = 1 – (3/5)2 – (2/5)2 = 0.48
Gini (sở hữu BĐS = Nhà thuê) = 1 – (2/6)2 – (4/6)2 = 0.444
GiniSplit (sở hữu BĐS) = (4/15)*0.375 + (5/15)*0.48 + (6/15)*0.444 = 0.4376
- Thu nhập
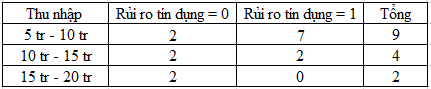
Gini (thu nhập = 5 tr – 10 tr) = 1 – (2/9)2 – (7/9)2 = 0.3456
Gini (thu nhập = 10 tr – 15 tr) = 1 – (2/4)2 – (2/4)2 = 0.5
Gini (thu nhập = 15 tr – 20 tr) = 1 – (2/2)2 = 0
GiniSplit (thu nhập) = (9/15)*0.444 + (4/15)*0.5 = 0.3407
Như vậy so sánh giá trị GiniSplit giữa 4 biến độ tuổi, tình trạng hôn nhân, sở hữu BĐS, và thu nhập thì biến có giá trị GiniSplit thấp nhất là biến thu nhập
Vậy biến thu nhập sẽ là root node

Chúng ta xét tiếp cho nhánh “5tr – 10tr” và “10tr – 15tr” để phân nhánh tiếp, do “15tr – 20tr” đã là pure, khi có 2 khách hàng trong node này có thu nhập ở khoảng từ 15 triệu đến 20 triệu họ không có rủi ro tín dụng. Vậy tiếp theo chúng ta chỉ còn xét 13 đối tượng dữ liệu. Tương tự sau này khi đã phân loại được các đối tượng dữ liệu vào các node chứa giá trị cuối cùng của biến mục tiêu thì chúng ta loại các đối tượng này ra để xét các đối tượng còn lại.
Tương tự như công thức ở trên chúng ta xét tiếp cho các biến:
- Độ tuổi
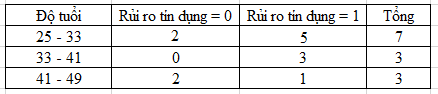
Chúng ta tính trực tiếp luôn GiniSplit cho nhanh khi đã quen với công thức:
GiniSplit (thu nhập = {5tr – 10tr, 10tr – 15tr}, Độ tuổi) = 0.322
- Tình trạng hôn nhân
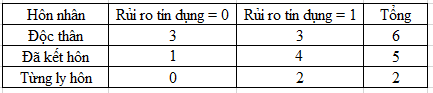
GiniSplit (thu nhập = {5tr – 10tr, 10tr – 15tr}, tình trạng hôn nhân) = 0.353
- Sở hữu BĐS
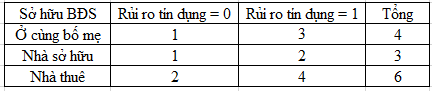
GiniSplit (thu nhập = {5tr – 10tr, 10tr – 15tr}, Sở hữu BĐS) = 0.423
So sánh các giá trị GiniSplit chúng ta thấy độ tuổi có ginisplit thấp nhất nên chúng ta chọn tiếp độ tuổi làm phân nhánh tiếp theo. Chúng ta có 100% khách hàng từ 33 – 41 tuổi với thu nhập dưới 15 triệu có khả năng rủi ro tín dụng

Chúng ta tiếp tục xét tiếp cho nhánh “25-33 tuổi và 41-49 tuổi”
Chúng tôi sẽ trình bày nhanh khúc này, các bạn có thể tự tính theo công thức ở trên.
Như vậy, ở đây khi tính tiếp GiniSplit, chúng ta sẽ chọn biến tình trạng hôn nhân để làm node phân nhánh tiếp theo.
Tuy nhiên ở đây chúng ta không có trường hợp pure node tức trong 6 khách hàng “độc thân” có các khách hàng có rủi ro tín dụng, và không có rủi ro tín dụng, tương tự như 4 khách hàng “đã kết hôn”. Các biến dữ liệu khác như thu nhập, sở hữu bất động sản, và độ tuổi cũng không có pure node, nhưng do giá trị GiniSplit của biến tình trạng hôn nhân nên chúng ta vẫn chọn để làm node phân nhánh tiếp theo.
Sau khi phân làm 2 nhánh, nhánh “Độc thân”, nhánh “Đã kết hôn” chúng ta phải xét cho mỗi nhánh. Ở nhánh “Đã kết hôn”, chúng ta còn 4 đối tượng để kiểm tra thì thấy rằng trong 4 đối tượng, chỉ có 1 đối tượng với độ tuổi “41-49 tuổi”, và thu nhập từ 10 triệu đến 15 triệu không có rủi ro tín dụng, 3 đối tượng còn lại cùng độ tuổi “25- 33 tuổi”, và thu nhập từ 5 triệu đến 10 triệu có rủi ro tín dụng, nên chúng ta sẽ dùng một trong 2 biến độ tuổi và thu nhập để phân nhánh tiếp.

Còn ở nhánh “độc thân” chúng ta không có trường hợp như vậy, nên phải để lại xét tiếp.

Tiếp tục tính GiniSplit để phân loại 6 đối tượng còn lại, thì chúng ta có được biến sở hữu BĐS sẽ là biến tiếp theo được phân nhánh.
Nhận thấy rằng, có 1 khách hàng có tình trạng sở hữu BĐS “nhà sở hữu”, có rủi ro tín dụng, nên được tách ra thành 1 nhánh, vậy chúng ta còn 5 đối tượng cần phân loại tiếp.
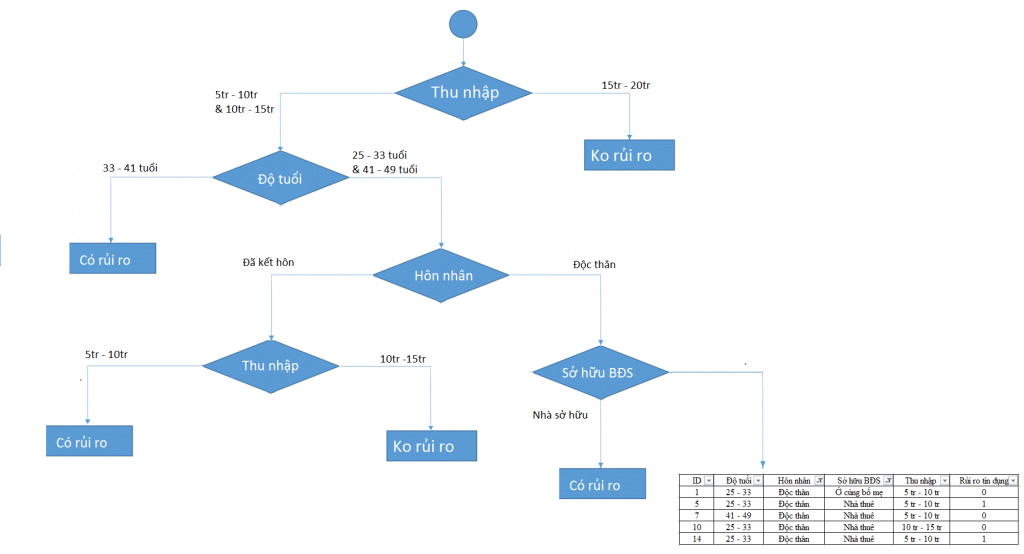
Các bạn cứ tiếp tục theo công thức như đã làm ở trên cho 5 đối tượng còn lại thì sau cùng chúng ta sẽ có một cây quyết định hoàn chỉnh như của BigDataUni dưới đây

Các bạn thấy đó, đối với tập dữ liệu chỉ cần có nhiều biến dữ liệu đầu vào đã làm cho hình dáng cây quyết định trở nên cồng kềnh hơn và khả năng cao mô hình đã bị overfitting (quá khớp với dữ liệu training có thể không đưa ra kết quả phân loại chính xác cho dữ liệu thật). Để kiểm chứng điều này trong thực tế thì chúng ta phải có tập dữ liệu đủ lớn, và kết hợp các phương pháp đánh giá mô hình phân loại để xác định liệu mô hình có hiệu quả hay không?
Ở bài viết sắp tới chúng ta sẽ làm quen với thuật toán C4.5 sử dụng công thức Entropy có thể phân nhiều nhánh một lúc. Các khuyết điểm và ưu điểm của các thuật toán cây quyết định, và khi nào thì thích hợp để sử dụng chúng để phân loại dữ liệu, ngoài ra còn các vấn đề khác về cách ngắt phân nhánh sao cho tối ưu chúng tôi sẽ giới thiệu ở bài viết khác.
Mong các bạn tiếp tục ủng hộ các bài viết tới của BigDataUni.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.