
 English
EnglishLý thuyết về thống kê – Statistics đặc biệt là kiểm định là một trong những nền tảng kiến thức cơ bản và quan trọng chắc có lẽ những ai học, nghiên cứu và làm việc trong ngành Data analytics, hay Data mining nói riêng và Data Science nói chung đều biết và được học qua.
Statistics chính là một phần của khoa học dữ liệu. Kiến thức thống kê hỗ trợ các nhà phân tích trong việc sử dụng những phương pháp thích hợp để thu thập dữ liệu, tóm tắt dữ liệu, phân tích, đưa ra các kết luận, kiểm chứng các kết luận, và trình bày kết quả một cách phù hợp. Thống kê là một quá trình quan trọng không thể thiếu khi chúng ta thực hiện các dự án nghiên cứu trong kinh tế, cũng như ở các lĩnh vực khác từ khoa học, sinh học, cho đến y học, v.v. Thống kê là một ngành khoa học có ý nghĩa, hữu ích với phạm vi ứng dụng rộng rãi bởi các doanh nghiệp, tổ chức khu vực chính phủ và đến tổ chức xã hội.
BigDataUni cũng đã giới thiệu đến các bạn 2 bài viết tóm lượt về thống kê mô tả (Descriptive Statistics), và thống kê suy luận (Inferential Statistics). Các bạn nào chưa biết, hoặc chưa có tìm hiểu về thống kê, thì nội dung trong bài viết phần này, và sắp tới về chủ đề kiểm định sẽ khó nắm bắt. Các bạn có thể tham khảo các bài viết về thống kê của BigDataUni dưới đây:
Tổng quan về Statistics: Khái niệm và ứng dụng của thống kê
Tổng quan về Statistics: Descriptive statistics (thống kê mô tả)
Tổng quan về Statistics: Inferential statistics (thống kê suy luận)
Lưu ý bài viết về chủ đề kiểm định lần này là phần tiếp nối của bài viết thống kê suy luận. Các lý thuyết quan trọng trong thống kê suy luận mà chúng tôi đề cập trong bài viết “Tổng quan về Statistics: Inferential statistics” các bạn có thể xem lại theo link ở trên, hoặc tham khảo các tài liệu liên quan khác về xác suất, các quy luật phân phối xác suất, ước lượng khoản tin cậy,… chúng tôi sẽ không trình bày lại chi tiết ở đây.
Ở bài viết thống kê suy luận vào năm ngoái, chúng ta đã tìm hiểu sơ về các công thức kiểm định tham số cơ bản trong thống kê tuy nhiên chưa đi vào ví dụ cụ thể, và các khía cạnh xung quanh. BigDataUni lần này quay trở lại với chủ đề kiểm định hay còn gọi Hypothesis Test sẽ giải thích rõ hơn về khái niệm, tầm quan trọng, giới thiệu lại công thức kiểm định theo cách diễn giải dễ hiểu nhất
Nhắc lại lần nữa, các lý thuyết kiểm định mà chúng tôi trình bày trong bài viết này chắc chắn có liên quan đến những thuật ngữ, là những mảng lý thuyết thống kê nền tảng của kiểm định như các tham số tổng thể, tham số mẫu, quy luật phân phối xác suất,… các bạn nào chưa biết, hoặc không hiểu vui lòng tìm hiểu lại thông quan tham khảo các bài viết trước của chúng tôi về thống kê, hay ở những tài liệu khác mà các bạn có. BigDataUni sẽ không giải thích lại.

Về Hypothesis Test, hay kiểm định được phân thành 2 nhóm chính, là kiểm định tham số (Parametric Hypothesis Test) – dành cho biến định lượng liên tục, dữ liệu là giá trị số thực, có giả định quy luật phân phối là phân phối chuẩn (Normal distribution), hoặc xấp xỉ phân phối chuẩn, kiểm định các giả thuyết liên quan đến các tham số mẫu, tham số tổng thể, thông tin về tổng thể nghiên cứu biết được qua tập dữ liệu; kiểm định phi tham số (Non-parametric Hypothesis Test) – dành cho biến định tính (định danh, thứ bậc), hay dữ liệu định lượng có phân phối chuẩn nhưng không rõ ràng, dữ liệu không có giả định về quy luật phân phối là phân phối chuẩn, dữ liệu có thể có phân phối bất kỳ, thông tin về tổng thể nghiên cứu không xác định rõ được từ tập dữ liệu, không gắn với bất kỳ tham số nào của tổng thể,…
Chủ đề kỳ này, gồm 2 phần bài viết, chúng ta sẽ tập trung trước vào kiểm định tham số. Bài viết phần 1, chúng ta sẽ đi vào tìm hiểu kiểm định là gì, các giả thuyết thống kê, cách vận hành của phương pháp kiểm định. Bài viết phần 2 lần sau sẽ trình bày về các công thức, các dạng kiểm định tham số với ví dụ cụ thể trong lĩnh vực kinh tế.
Chúng ta cùng đi vào phần 1 bài viết.
Kiểm định là gì và tại sao nó quan trọng?
Giải nghĩa tiếng Việt Kiểm định được hiểu là kiểm tra, hay kiểm chứng những giả định, giả thuyết về sự vật, sự kiện nào đó trong đời sống xung quanh. Ở khía cạnh thống kê, khi được áp dụng cho các mục đích kinh doanh của lĩnh vực kinh tế, nhu cầu nghiên cứu của khoa học, xã hội thì kiểm định chính là xác thực độ tin cậy, độ chính xác của một giả định, giả thuyết nào đó về các đối tượng nghiên cứu, điều tra, hay phân tích để từ đó hỗ trợ việc ra quyết định.
Giả sử một chuyên gia cho rằng độ tuổi trung bình khi kết hôn của một người trưởng thành, sống trong khu vực đô thị là 28 tuổi (được làm tròn), một thầy giáo tại một trường đại học danh tiếng nói rằng tỷ lệ học sinh đạt điểm trúng tuyển đại học 25/30 thường chiếm 80% là tự học tại nhà, một nhân viên marketing sau khi khảo sát khách hàng báo cáo rằng các hoạt động quảng cáo trong năm qua có tỷ lệ chuyển đổi trung bình là 40% (tức 100 khách hàng nhìn thấy quảng cáo về sản phẩm, dịch vụ trên website, thì có 40 khách hàng đã liên hệ xin tư vấn), một chuyên gia y tế công bố khả năng tử vong lên đến 90% khi nhiễm Covid-19 tập trung ở những người lớn tuổi với độ tuổi trung bình trên 85, một nhân viên nhà máy báo cáo dây chuyền sản xuất mới sản xuất bánh snack trung bình 48.9 gram so với tiêu chuẩn là 50 gram,…
Làm cách nào chúng ta có thể đưa ra kết luận liệu những khẳng định ở trên hoàn toàn chính xác với thực tế? Nếu chỉ là nhận định chưa có căn cứ, chúng ta có thể xem là các giả thuyết, thì những giả thuyết này phản ánh đúng thực tế? Bao nhiêu % chính xác và ngược lại? Chúng ta có cơ sở để tin tưởng chúng không khi các chuyên gia, các nhà nghiên cữu, họ chỉ có thể điều tra, thu thập dữ liệu ở phạm vi cho phép, với nguồn lực hạn hẹp, chứ không thể điều tra hết tất cả?
Dĩ nhiên, làm sao một chuyên gia có khả năng tìm đến tất cả những người trưởng thành trong một thành phố để hỏi họ kết hôn vào năm bao nhiêu? Làm sao một thầy giáo có thể đi hết tất cả các trường cấp 3, khảo sát hết tất cả các tân sinh viên để hỏi họ hồi ôn thi có học thêm ở các trung tâm hay ở nhà? Hay nhân viên marketing làm cách nào khảo sát được hết tất cả khách hàng thân thiết để biết được độ hiệu quả của quảng cáo?…
Hoàn toàn không thể! Đây chính là lý do tại sao các chuyên gia về dữ liệu từ mấy chục năm trước đã nghiên cứu và phát minh ra những phương pháp kiểm định, và cho đến nay, chúng là công cụ không thể thiếu không chỉ ở lĩnh vực thống kê và rộng hê ở các lĩnh vực Data mining, cho đến Machine learning. Kiểm định cho phép chúng ta đưa ra các kết luận về đối tượng nghiên cứu một cách chính xác mà không cần phải thu thập mọi dữ liệu từ tổng thể chứa tất cả các đối tượng nghiên cứu.
Nói cách khác, kiểm định giúp chúng ta đưa ra các “phán đoán” về sự vật, hiện tượng, hay mọi thứ xung quanh một cách “thông minh hơn”, “tự tin hơn” cho dù chúng ta hoàn toàn không có thông tin về tất cả đối tượng nghiên cứu thông qua những công thức tính toán tiêu chuẩn, hợp lý, đã được kiểm chứng.
Kiểm định sau cùng là công cụ hỗ trợ để chúng ta xác định các giả thuyết, kết luận mà mình đưa ra có ý nghĩa hay không, và có khả năng xảy ra trong thực tế hay không.
Thống kê dữ liệu mục đích là nói cho chúng ta biết về dữ liệu, và bản thân chúng ta không quan tâm dữ liệu là gì, có gì, có hình dạng như thế nào mà chúng ta quan tâm thông qua dữ liệu chúng ta có được thông tin gì, chúng ta phân tích gì từ dữ liệu. Và bằng cách nào xác minh những gì chúng ta có, chúng ta phân tích là đúng, thì phải nhờ vào kiểm định. Kiểm định được coi là lý thuyết quan trọng nhất trong thống kê, và là phương pháp tổng hợp tất cả những mảng lý thuyết còn lại trong thống kê từ tóm tắt dữ liệu, tính toán các đặc trưng của mẫu, của tổng thể hay nói cách khác là các tham số, các giả định về quy luật phân phối xác suất,…và dĩ nhiên kiểm định là kiến thức “giá trị nhất” của thống kê, là cơ sở để lĩnh vực thống kê mãi tồn tại, và được ứng dụng phổ biến.
Như vậy, chúng ta đã tạm nắm sơ lược về kiểm định trong lĩnh vực thống kê, thấy được tác dụng của nó quan trọng như thế nào, hỗ trợ nâng cao độ tin cây của mọi thông tin mà chúng ta tiếp nhận hàng ngày. Tiếp theo chúng ta sẽ tìm hiểu bằng cách nào mà kiểm định lại hữu dụng như vậy.
Tham khảo từ những tài liệu, giáo trình thống kê tiêu chuẩn quốc tế, thì khái niệm chung dành cho kiểm định:
“Kiểm định là quy trình dựa trên những thông tin tìm được từ dữ liệu mẫu để đánh giá các kết luận về tổng thể nghiên cứu hoặc xác định các giả thuyết đưa ra về tổng thể có hợp lý hay không?”
Thông qua khái niệm trên, chúng ta có thể hiểu, từ dữ liệu mẫu chúng ta phải tìm ra các thông tin để tiến hành kiểm định. Các thông tin đó là gì?
Có thể bao gồm: trung bình mẫu (Mean), phương sai (Variance), độ lệch chuẩn (Standard deviation), tỷ lệ mẫu (Proportion). Chi tiết chúng ta sẽ tìm hiểu ở phần công thức tính giá trị kiểm định. Nếu có cái nào chưa biết, các bạn nên tìm hiểu và nghiên cứu trước khi xuống phần tiếp theo sau đây qua các tài liệu khác hoặc những bài viết của chúng tôi về thống kê.
Vấn đề phức tạp, khó hiểu, và dễ nhầm lẫn nhất, là nguy cơ khiến toàn bộ quy trình kiểm định có thể “sụp đổ” mà theo các chuyên gia không phải đến từ dữ liệu mẫu, hay đến từ các công thức tính toán mà nó chính là đến từ việc lập ra các giả thuyết. Giả thuyết đặt ra không hợp lý, sẽ dẫn đến các sai lầm loại I và loại II, và khiến chính kết quả kiểm định sẽ trở nên mơ hồ.
Giả thuyết là gì? Tại sao cần cẩn thận khi đặt giả thuyết? Các sai lầm trong kiểm định?
Giả thuyết thống kê (statiscal hypothesis) là một kết luận, là một phát biểu, là một giả sử, là một nhận định chưa được kiểm chứng nói về giá trị thực của một tham số tổng thể bất kỳ.
Ví dụ số tiền chi mua sắm ngày tết của các khách hàng tại một siêu thị trung bình là 5 triệu đồng, tổng thể nghiên cứu là khách hàng ghé vào siêu thị từ trước tết 2 tuần đến ngày 30 tết, số tiền trung bình 5 triệu độn là tham số trung bình số tiền chi của tổng thể. Như vậy câu trên là một giả thuyết.
Lưu ý, giả thuyết phải đúng, hoặc sai, không được “lấp lửng”.
Trong lĩnh vực thống kê, khi nói về kiểm định giả thuyết thì có 2 loại giả thuyết, nếu xét về góc độ nội dung giả thuyết. Thứ nhất là các giả thuyết thể hiện kết luận về đặc điểm của tổng thể nghiên cứu, các tham số của tổng thể nghiên cứu như ở trên (kiểm định 1 mẫu). Thứ hai, các giả thuyết về mối quan hệ giữa 2 hoặc nhiều đối tượng nghiên cứu các trong tổng thể. (kiểm định 2 mẫu)
Nếu xét trong một bài toán kiểm định, thì sẽ có 2 giả thuyết quan trọng.
Giả thuyết H0 (Null Hypothesis) là giả thuyết với mục đích kiểm chứng các số liệu, là giả thuyết ban đầu được nêu ra, là kết luận hay tuyên bố về các tham số tổng thể chưa biết trong thực tế, hay về mối quan hệ giữa hai hoặc các đối tượng nghiên cứu. Giả thuyết H0 được chấp nhận khi dữ liệu mẫu cung cấp các thông tin có tính “thuyết phục”về tổng thể nghiên cứu thông qua các công thức tính toán.
Giả thuyết H1 (Alternative Hypothesis) là giả thuyết đối, hay kết quả ngược lại của giả thuyết H0, còn được gọi là giả thuyết thay thế cho giả thuyết H0 là chỉ được chấp nhận khi dữ liệu mẫu cung cấp các thông tin có tính “thuyết phục” về tổng thể nghiên cứu mà ở đó bác bỏ giả thuyết H0, kết luận giả thuyết H0 không chính xác.
Các bạn nhìn có thể thấy đơn giản nhưng thực chất khó hiểu hơn bạn nghĩ.
Theo một số tài liệu khác, H0 và H1 được phân biệt như sau với H0 có thể là những giả thuyết thể hiện “hiện trạng hiện tại” của đối tượng nghiên cứu, và các giả thuyết được đưa ra mang tính “thăm dò”, các giả định được “tin” là đúng, nhưng không chắc chắn, cần xác định xem giả thuyết có sai hay không.
Còn giả thuyết H1 thì là giả thuyết được đưa ra vì mong muốn tìm kiếm các chứng cứ, các số liệu tính toán từ tập dữ liệu để bảo vệ luận điểm, hoặc dựa trên mục đích nghiên cứu, chứng minh giả thuyết. H1 còn được gọi là giả thuyết nghiên cứu (Research Hypothesis). Đây là điều dễ gây nhầm lẫn.
Theo các chuyên gia, thông thường các ứng dụng của phương pháp kiểm định thường dựa trên mục đích là tìm kiếm các chứng cứ, các dữ liệu để bảo vệ hay bác bỏ (do nghi ngờ về giả thuyết) một luận điểm, một giả thuyết đang được nghiên cứu để đánh giá độ chính xác. Ở những trường hợp như vậy, thì chúng ta nên bắt đầu xây dựng giả thuyết H1 trước và giả thuyết H0 sẽ ngược lại với giả thuyết H1. Các trường hợp còn lại, thì có thể bắt đầu với H0 trước.
Một cách khác để xác định giả thuyết H0 là nên đặt trước hay giả thuyết H1 là nên đặt trước, đó chính là dựa vào mức độ sai lầm của kiểm định.
Các sai lầm thường mắc khi kiểm định giả thuyết:
- Giả thuyết H0 đúng (tức thực tế θ = θo) nhưng qua kiểm định chúng ta kết luận sai, nghĩa là θ ≠ θo vậy ta bác bỏ H0. Đây là sai lầm loại I tức chúng ta bác bỏ giả thuyết H0 khi giả thuyết này đúng.
- Giả thuyết H0 sai nhưng qua kiểm định chúng ta kết luận đúng, và không bác bỏ. Đây là sai lầm loại II, tức chúng ta không bác bỏ H0 khi giả thuyết này sai

Các bạn có thể nhìn qua hình ảnh vui nhộn dưới đây để tự nghiệm lại nhé.

Ví dụ, kiểm tra hiệu suất vận hành của dây chuyền sản xuất thì giả thuyết đưa ra là dây chuyền sản xuất hoạt động hiệu quả. Như vậy, nếu giả thuyết này sai, mà không bác bỏ, tức chấp nhận nó thì hậu quả sẽ như thế nào. Ngược lại, nếu dây chuyền sản xuất hoạt động tốt mà nói không thì hậu quả sẽ nhẹ hơn rất nhiều. Vậy giả thuyết H0 nên được đặt là “dây chuyền sản xuất hoạt động không hiệu quả” vì nếu sai lầm mà bác bỏ H0 khi thực tế giả thuyết này đúng thì sẽ rất nguy hiểm.
Thực chất, vấn đề đặt giả thuyết cũng phụ thuộc vào kinh nghiệm của người làm phân tích, người làm nghiên cứu, cụ thể nếu giả thuyết được đặt ra mà khả năng cao đúng với thực tế (theo phán đoán, hay theo cảm nhận, kiến thức chuyên môn) thì thường sẽ đặt là giả thuyết H1 và giả thuyết H0 sẽ ngược lại.
Ví dụ, một chuyên gia dân số thấy rằng độ tuổi trung bình kết hôn tại thành phố Hồ Chí Minh là trên 25 tuổi, lấy mẫu theo từng quận, mỗi quận chọn ra 1000 người dân ngẫu nhiên đã đăng ký kết hôn để thực hiện kiểm định. Như vậy H1: µ > 25 suy ra H0: µ ≤ 25.
Chúng ta cùng tóm tắt lại lần nữa, cách đặt giả thuyết như thế nào là hợp lý qua ví dụ dưới đây:
- Trong lĩnh vực kinh tế, đặc biệt ở các công ty hoạt động vì lợi nhuận, mong muốn luôn phát triển được các sản phẩm mới, dịch vụ mới, triển khai các hệ thống mới để tăng hiệu quả hoạt động. Và cái họ quan tâm và nghiên cứu là liệu chúng có “tốt” hơn những cái hiện tại hay không. Ví dụ dịch vụ CSKH qua mạng Facebook, Zalo được cho rằng sẽ hỗ trợ khách hàng nhanh chóng hơn. Vậy H1: dịch vụ CSKH mới nhanh hơn hệ thống cũ, và H0: dịch vụ CSKH không nhanh hơn hệ thống cũ. Sản phẩm smartphone mới khả năng thu hút nhiều khách hàng hơn phiên bản cũ, vậy H1: smartphone phiên bản mới có sức hút tốt hơn phiên bản cũ và H0 là ngược lại.
- Trong một nhà máy sản xuất hóa chất, quản lý nhà máy khẳng định rằng 1 thùng hóa chất A dạng lỏng được đong bằng dây chuyền sản xuất chứa trung bình ít nhất 40 lít. Chúng ta biết rằng dây chuyền sản xuất ít khi nào có sai sót, nên tin tưởng vào lời nói của quản lý nhà máy. Tuy nhiên, sẽ tốt hơn nếu chúng ta kiểm tra lại xem các dây chuyền có gặp vấn đề thiệt sự không. Như vậy H0: µ ≥ 40 lít sẽ được đặt trước và suy ra H1 ngược lại.
Như vậy chúng ta đã tìm hiểu giả thuyết thống kê là gì, và cách đặt giả thuyết sao cho phù hợp, tiếp tục chúng ta cùng đi qua các công thức quan trọng trong kiểm định tham số.
Các bước thực hiện một bài toán kiểm định:
Tùy theo phương pháp, kinh nghiệm, kiến thức chuyên môn, mục đích nghiên cứu mà chúng ta sẽ có các bước thực hiện kiểm định khác nhau, nhưng đều có thể có chung các bước sau dưới đây:
Bước 1: Đặt các giả thuyết H0 và H1 dựa trên mục đích kiểm định
Bước 2: Xác định các yếu tố hỗ trợ kết luận (cụ thể là xác định mức ý nghĩa, và độ tin cậy, cũng như miền bác bỏ) – cơ sở để bác bỏ hay không bác bỏ giả thuyết H0
Bước 3: Thu thập dữ liệu mẫu, tính toán các tham số của mẫu
Bước 4: Tính giá trị kiểm định
Bước 5: Xem xét có hay không bác bỏ giả thuyết H0
Bước 6: Đưa ra kết luận sau cùng cho bài toán kiểm định
Lưu ý ở bước kết luận: chúng ta chỉ có thể bác bỏ hay không bác bỏ một giả thuyết điều đó không có nghĩa giả thuyết này là đúng hoàn toàn hay sai hoàn toàn. Nên nhớ rằng chúng ta tính toán trên mẫu dữ liệu chứ không phải toàn bộ dữ liệu từ tổng thể.
Cơ sở bác bỏ giả thuyết
Kiểm định tham số dựa trên giả định tổng thể nghiên cứu có phân phối chuẩn hoặc xấp xỉ chuẩn.
Nhắc lại, phân phối chuẩn là quy luật phân phối phổ biến nhất, và thông dụng nhất phù hợp áp dụng cho các mục đính nghiên cứu trong kinh tế, xã hội, do các hiện tượng, các đối tượng nghiên cứu phát triển không đồng đều. Ví dụ đơn giản, trong xã hội sẽ có người giàu, người nghèo, người cao trung bình, người rất cao, người rất thấp, thu nhập một người có thể tăng cao nhất, có thể giảm thấp nhất,…
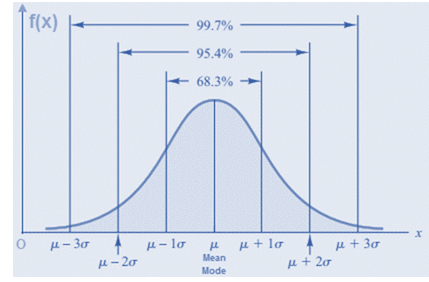
Các tính chất của phân phối chuẩn:
Đồ thị của phân phối chuẩn có hình dạng giống như cái chuông được cân bằng bởi giá trị trung bình µ (Mean) = trung vị (Median) = Mode chia hình chuông thành 2 phần mỗi bên có diện tích bị giới hạn bởi đường cong hàm mật độ, bằng 0.5.
Khoảng 68% giá trị rơi vào khoảng (µ – s) và (µ + s), khoảng 95% giá trị rơi vào khoảng (µ– 2s) và (µ + 2s), và khoảng 99.7% giá trị rơi vào khoảng (µ – 3s) và (µ+ 3s)..
Bên trên là hàm mật độ xác suất của phân phối chuẩn. Như vậy khi tổng thể được cho là có quy luật phân phối chuẩn, thì dữ liệu mẫu cũng phải thể hiện được các đặc điểm của quy luật phân phối chuẩn. Do đó việc các công thức tính toán trong kiểm định đều hướng đến trước tiên là đưa các tham số mẫu trở thành các giá trị chuẩn hóa z, để dữ liệu mẫu đáp ứng tính chất của phân phối chuẩn.

 Công thức chuẩn hóa z để đưa phân phối chuẩn về phân phối chuẩn tắc – phân phối chuẩn đơn giản.
Công thức chuẩn hóa z để đưa phân phối chuẩn về phân phối chuẩn tắc – phân phối chuẩn đơn giản.
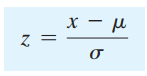
(x là giá trị cần chuyển hóa, µ là tham số trung bình của tất cả những giá trị x trong tổng thể, σ là độ lệch chuẩn của tổng thể).
Công thức kiểm định suy ra từ công thức chuẩn hóa z:
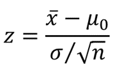
Trung bình x trên tử số là giá trị trung bình của mẫu dữ liệu, µ0 là giá trị của tham số tổng thể cần kiểm định, do tính trên dữ liệu mẫu nên chúng ta không thể lấy độ lệch chuẩn của tổng thể, mà phải lấy độ lệch tiêu chuẩn của phân phối trung bình mẫu là σx = σ/ căn bậc 2 (n). Cái này dựa trên định lý giới hạn trung tâm Central Limit Theoremcủa phần phân phối mẫu (Sampling distribution). Các bạn có thể xem lại bài viết của chúng tôi về thống kê suy luận để hiểu thêm hoặc tham khảo các tài liệu khác.

Đồ thị hàm mật độ xác suất sau khi chuẩn hóa:
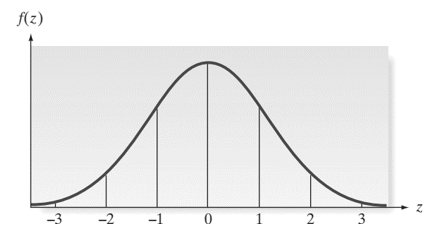
Trung bình µ = 0, độ lệch chuẩn sẽ bằng 1.
Nếu trung bình của tổng thể được chuẩn hóa, như vậy sẽ có giá trị = 0. Trung bình của mẫu sau khi được chuẩn hóa, nếu gần giá trị 0 tức trung bình của mẫu sẽ gần bằng với µ0, nghĩa là giá trị của tham số trung bình tổng thể của giả thuyết có thể chấp nhận.
Chúng ta sẽ đi vào ví dụ để các bạn hiểu hơn. Trước tiên cùng nhìn qua 2 cách đặt giả thuyết 1 chiều và giả thuyết 2 chiều.
Lấy lại ví dụ quản lý nhà máy sản xuất hóa chất nói rằng trung bình một thùng hóa chất loại A chứa ít nhất 40 lít, đạt tiêu chuẩn, yêu cầu của các khách hàng mỗi thùng 40 lít, biết rằng độ lệch chuẩn là 4 lít. Vậy chúng ta đặt
H0: µ= µ0 = 40
H1: µ≠ µ0 = 40
Lấy mẫu 1000 thùng kiểm tra thì thấy, trung bình mỗi thùng là 39.9 lít. Như vậy theo công thức kiểm định, giá trị z sẽ tính được gần bằng – 0.8 (lấy công thức (2) tính) không quá xa giá trị 0, nên chưa thể chắc chắn bác bỏ H0 được. Tuy nhiên nếu trung bình mỗi thùng là 39 lít, giá trị kiểm định z bằng -8, rất xa giá trị 0, vậy có thể chắc chắn bác bỏ giả thuyết H0 do tham số mẫu lấy từ thực tế và tham số tổng thể từ giả thuyết là quá khác biệt.
Tuy nhiên làm thế nào chúng ta biết được khi nào giá trị kiểm định z gần giá trị 0 hoặc xa giá trị 0 thì mới bác bỏ H0.? ở ví dụ trên thì có thể thấy rõ sự khác biệt nhưng ở các trường hợp khác sự khác biệt như thế nào thì mới bác bỏ giả thuyết. Chúng ta phải đặt ra điểm tới hạn, trong phương pháp thống kê gọi là miền bác bỏ.
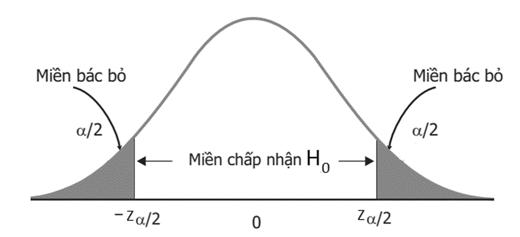
Hình minh họa đồ thị phân phối chuẩn kiểm định giả thuyết 2 bên (H1: θ = θo)
Mức ý nghĩa alpha (α) được hiểu là điểm tới hạn mà ở đó H0 bị bác bỏ. Mỗi giá trị z tính được sẽ có 1 xác suất cụ thể dựa theo hàm mật độ xác suất của quy luật phân phối chuẩn. Để nhanh chóng, chúng ta có thể tra bảng phân phối chuẩn chuẩn tắc z, cần lưu ý loại bảng tra (thường có 2 loại 1 phía và 2 phía) Như vậy khi zα/2 tính được chúng ta sẽ so sánh với giá trị kiểm định z nếu giá trị kiểm định z nhỏ hơn zα/2 thì có nghĩa chấp nhận H0 còn nếu lớn hơn thì phải bác bỏ.
Nếu các bạn chưa hiểu, các bạn có thể tham khảo lại bài viết thống kê suy luận của chúng tôi, phần quy luật phân phối chuẩn, có trình bày cách tính xác suất cho giá trị được chuẩn hóa z.
Vậy giá trị tới hạn trong thực tế được hiểu như thế nào? Lấy lại ví dụ ở trên, giả sử bạn là khách hàng, yêu cầu của bạn là mua một thùng hóa chất 40 lít, bạn cho phép dung sai nhỏ hơn 0.25 lít tức chấp nhận thùng hóa chất chứa 39.75 lít đến 40 lít. Tuy nhiên nếu thiếu vượt quá 1 lít, liệu bạn có chấp nhận? dĩ nhiên là không, vậy 0.25 lít chính là zα/2. Thông qua bảng tra Z, chúng ta sẽ tìm được mức ý nghĩa đặt đây làm cơ sở bác bỏ giả thuyết.
Tuy nhiên trong thực tế, khi việc xác định giá trị tới hạn sao cho phù hợp với kinh nghiệm của nhà phân tích, vừa thể hiện được tính giá trị nhận được từ phương pháp kiểm định là rất khó. Nên các chuyên gia thường quy định mức ý nghĩa α = 5% là phổ biến, mức ý nghĩa này cũng xuất hiện mặc định trong nhiều phần mềm phân tích thống kê nổi tiếng như SPSS, SAS, Minitab.
Nguyên nhân khác trong việc thường cố định mức ý nghĩa α chính là khi đưa ra giả thuyết, chúng ta sẽ thường mắc sai lầm như loại I, loại II đề cập ở trên, kiểm định là công cụ giúp khả năng mắc các sai lầm. Người làm kiểm định mong muốn tối thiểu xác suất dẫn đến sai lầm cả loại I và loại II, nhưng điều này là không thể do mẫu phân tích là mẫu cố định, giả thuyết H0 và H1 đối lập, khi cố gắng giảm sai lầm loại I thì khả năng mắc sai lầm loại II sẽ cao lên. Do đó, các chuyên gia thường cố định mức ý nghĩa/ xác suất xảy ra sai lầm loại I, và cố gắng tối thiểu khả năng mắc sai lầm loại II.
Quay trở lại với công thức kiểm định, chúng ta thấy rằng để bác bỏ H0 chúng ta có thể tính giá trị kiểm định z và xác định mức ý nghĩa α, tra bảng z để tìm giá trị tới hạn, rồi so sánh. Có một cách khác, chính là chúng ta sẽ tính p-value, mức ý nghĩa nhỏ nhất khiến H0 bị bác bỏ (tính được dựa vào giá trị kiểm định z kết đồ thị hàm mật độ xác suất), rồi đem so sánh với mức ý nghĩa.
- p-value ≤ α thì bác bỏ giả thuyết H0, chấp nhận H1
- p-value > α thì chưa có cơ sở bác bỏ H0
Giải thích: nhìn vào đồ thị hàm mật độ xác suất, tổng diện tích bằng 1 thể hiện xác suất từ 1% đến 100%, α/2 ở 2 bên có phần tô đen là phần thể hiện phần diện tích của miền bác bỏ, p-value nếu nằm trong miền bác bỏ tức phần diện tích sẽ nhỏ hơn của α/2, p-value càng nhỏ, tức phần diện tích sẽ hẹp dần sang mép trái, hoặc mép phải, tức giá trị kiểm định z nằm rất xa giá trị 0. Do đó cơ sở bác bỏ H0 là hoàn toàn hợp lý.
Cách hiểu khác về p-value: p-value được so sánh với α, mà α là xác suất cho phép mắc sai lầm loại I khi bác bỏ H0 mà giả thuyết H0 lại đúng nên p-value cũng được coi là xác suất nhỏ nhất để mắc sai lầm loại I tính trên bộ dữ liệu mẫu, như vậy khi p-value nhỏ hơn cả α nghĩa là khả năng mắc sai lầm loại I là rất thấp, vậy có thể tự tin bác bỏ H0 mà không lo ngại, xét tương tự ở chiều ngược lại
Việc tính p-value dựa trên giá trị kiểm định z có thể dựa theo công thức của hàm mật độ xác suất của quy luật phân phối chuẩn tắc.
Hoặc tra bảng phân phối chuẩn tắc để tìm nhanh φ (Z). Tuy nhiên cần lưu ý loại bảng tra (thường có 2 loại 1 phía và 2 phía) để tìm φ (Z) tính p-value, và xem xét cả dạng kiểm định là 1 phía hay 2 phía để tính toán giá trị p-value sau cùng để so sánh với α chứ không phải α/2.
Nếu kiểm định 1 phía, thì giá trị kiểm định tìm được sẽ so sánh với zα không phải là zα/2 và cách xác định p-value cũng sẽ khác.
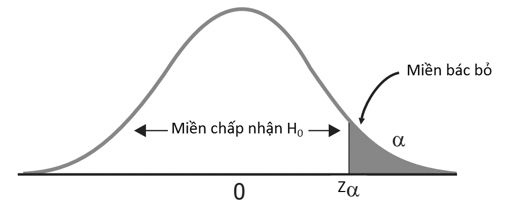
ình minh họa đồ thị phân phối chuẩn kiểm định giả thuyết 1 bên (H1 : θ > θo)
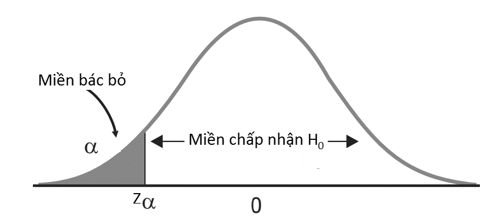
Hình minh họa đồ thị phân phối chuẩn kiểm định giả thuyết 1 bên (H1 : θ < θo)
Cụ thể cách tính p-value như thế nào chúng tôi sẽ trình bày chi tiết ở phần 2.
Như vậy đến đây, kết thúc phần 1 của bài viết về chủ đề kiểm định tham số. Mong rằng, bài viết đã giải thích phần nào rõ hơn và dễ hiểu hơn về phương pháp kiểm định cho những bạn đang tìm hiểu về phương pháp này.
Bài viết phần 2, phần 3 chúng ta sẽ đi vào các dạng kiểm định từ cơ bản đến phức tạp như kiểm định 1 mẫu (giả thuyết chứa thông tin về trung bình tổng thể, tỷ lệ tổng thể), kiểm định 2 mẫu (độc lập, hoặc mẫu cặp).
Tài liệu tham khảo
“Statistics” của các tác giả James T. McClave, Terr y Sincich
“Essentials of Statistics for The Behavioral Sciences” của các tác giả Frederick J Gravetter, Larry B. Wallnau, Lori-Ann B. Forzano
“Basic statistics for business and economics” của các tác giả Douglas A. Lind, William G. Marchal, Samuel A. Wathen
“Statistics for Business and Economics” của các tác giả David R. Anderson, Dennis J. Sweeney, Thomas A. Williams và cộng sự
www.analyticsvidhya.com/blog/2015/09/hypothesis-testing-explained/
https://www.statisticshowto.com/probability-and-statistics/hypothesis-testing
hub.packtpub.com/how-data-scientists-test-hypotheses-and-probability/
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.