
 English
EnglishNhư vậy chúng ta đã đến bài viết cuối cùng về chủ đề hồi quy logistic cũng như ứng dụng của nó trong lĩnh vực ngân hàng, ở phần cuối cùng này chúng ta sẽ đi vào ví dụ đơn giản cuối cùng áp dụng hồi quy logistic trong phân loại mức độ tín dụng của khách hàng để đánh giá khả năng khách hàng không trả được nợ (bao gồm cả lãi) được coi là nợ xấu và dẫn đến việc ngân hàng phải gặp rủi ro tín dụng. Những bài viết trước khá dài chắc khiến nhiều bạn cảm thấy ngộp và chán. Nhưng ở phần cuối này, chúng tôi sẽ không trình bạy cụ thể từng bước phân tích ví dụ như ở bài viết trước và cố gắng giải thích ngắn gọn hơn, đồng thời vào thẳng vào trọng tâm. Lưu ý, các bạn nào chưa có kiến thức về hồi quy logisitc sẽ khó hiểu nội dung bài viết này.
Dành cho những bạn chưa tham khảo các bài viết trước:
Tổng quan về Logistic regression (hồi quy Logistic) (Phần 1)
Tổng quan về Logistic regression (hồi quy Logistic) (Phần 2)
Tổng quan về Logistic regression (hồi quy Logistic) (Phần 3)
Tổng quan về Logistic regression (hồi quy Logistic) (Phần 4)
Tổng quan về Logistic regression (hồi quy Logistic) (Phần 5)
Ví dụ hồi quy logistic regression trong ngân hàng (Phần 1)
Ví dụ hồi quy logistic regression trong ngân hàng (Phần 2)
Nói về lý do các ngân hàng phải dự báo khả năng nợ xấu của khách hàng hay ngăn chặn trước những rủi ro tín dụng thì mục đích chính là đảm bảo lợi nhuận. Ngân hàng mở rộng các dịch vụ cho vay để gia tăng lợi nhuận tuy nhiên nếu khách hàng không trả được nợ, xét cả gốc và lẫn lãi hoặc khách hàng không thể thanh toán nợ gốc và lãi đúng hạn sau khi được ngân hàng cấp các khoản tín dụng, thì tất cả đều sẽ khiến ngân hàng chịu tổn thất, và về lâu dài, nếu cứ tiếp diễn thì khó có thể tăng trưởng. Quản lý rủi ro tín dụng được xem là quy trình quan trọng hàng đầu để ngăn chặn, cảnh báo, đưa ra các biện pháp để hạn chế tối đa nguy cơ khách hàng không thanh toán được khoản vay đúng hạn hay nói cách khác nguy cơ khách hàng không tuân thủ các nghĩa vụ trong hợp đồng tín dụng.
Nguyên nhân chính khiến ngân hàng thường chịu tổn thất vì rủi ro tín đụng dến từ khách hàng đó là do quá trình xét duyệt và cấp phát tín dụng, khoản vay của ngân hàng chưa tối ưu, qua trình thu thập các thông tin về khách hàng cũng như kiếm tra tính xác thực trước khi cho vay cũng có vấn đề, bộ phận cấp phát tín dụng làm việc không hiệu quả, sự yếu kém đội ngũ nhân viên trong ngân hàng, không triển khai hay chưa tối ưu quy trình giám sát các hoạt động tín dụng trong ngân hàng ví dụ quy trình cấp phát tín dụng có thể lỏng lẻo không tuân thủ nghiêm ngặt các quy định đề ra,… Tuy nhiên xét về tổng thể, thì chính tầm nhìn và chiến lược hoạt động của ngân hàng là nguyên nhân đầu tiên của rủi ro tín dụng, ví dụ nếu ngân hàng nâng giới hạn mức độ chấp nhận rủi ro tín dụng, mở rộng nhiều loại hình tín dụng cho vay, nới lỏng các yêu cầu về khách hàng thì quá trình xét duyệt khách hàng sẽ không còn khắt khe.
Như các bạn thấy, đồng ý một phần là chính các quy trình của ngân hàng cần cải thiện để hạn chế rủi ro tín dụng hay nợ xấu, nhưng trọng tâm là do ngân hàng không thấu hiểu khách hàng bao gồm không thể dự báo hành vi khách hàng bên cạnh không thể đánh giá một khách hàng nguy cơ nợ xấu thường sẽ có các đặc điểm chính gì để phân loại, không biết được khả năng không thể trả nợ, và tìm ra giải pháp nhanh chóng để đi trước một bước.
Mặc dù mọi ngân hàng đều có công thức tính điểm rủi ro tín dụng hay còn gọi Credit Score dựa trên hàng loạt các yếu tố đánh giá khác nhau nhưng cũng cần nhiều hơn thông tin để đánh giá sâu hơn về khách hàng của mình. Điều này có được chủ yếu phải qua phân tích dữ liệu. Logistic regression là một trong những công cụ phân tích hiệu quả giúp ngân hàng dựa trên thông tin có được từ khách hàng để dự báo khả năng khách hàng không thanh toán được khoản vay hay không.
Chúng ta cùng đi vào ví dụ, dữ liệu trong ví dụ này được chúng tôi được chúng tôi lấy từ trang UCI Machine Learning Repository, từ tiến sĩ Hans Hofmann, Đại học Hamburg (1994). Ví dụ được xem là một trong những case study đầu tiên và phổ biến về sử dụng phân tích dữ liệu để dự báo khả năng khách hàng nợ xấu trong ngân hàng.
Tập dữ liệu gồm 1000 quan sát (1000 khách hàng đã tham gia dịch vụ tín dụng tiêu dùng của ngân hàng, mỗi khách hàng đã được dán nhãn “tốt” và “xấu” về mức độ rủi ro tín dụng), dữ liệu không có missing, giá trị ngoại lệ xuất hiện tại 1 biến duy nhất là Credit Amount (khoản tín dụng khách hàng vay) là cần quan tâm đến, nhưng không có giá trị âm, và một số thông tin chúng ta không biết ví dụ hạn mức tín dụng, tạm thời trong bài viết này chúng ta sẽ chưa đề cập đến xử lý dữ liệu ngoại lệ và giả định chúng chưa ảnh hưởng nhiều đến kết quả phân tích.
Bộ dữ liệu gồm 20 biến dự báo và 1 biến mục tiêu đó là đánh giá mức độ rủi ro tín dụng của khách hàng, với 0 là xấu – mức độ rủi ro cao, 1 là tốt – mức độ rủi ro thấp. Xấu thể hiện nguy cơ khách hàng có thể không thanh toán khoản tín dụng đúng hạn, và tốt là ngược lại. Mục đích chúng ta sẽ sử dụng logistic regression để xem các yếu tố nào sẽ tác động đên việc phân loại mức độ rủi ro tín dụng cho từng khách hàng. Kết quả phân tích sau cùng đạt được sẽ là: ngân hàng sẽ biết được khách hàng được phân loại thế nào là xấu, và tốt dựa trên những đặc điểm gì để đưa ra giải pháp. Nếu xác suất ước lượng được từ phương trình hồi quy > 0.5, thì khách hàng khả năng cao được phân loại là tốt và ngược lại, lưu ý đây không phải chỉ ra xác suất khách hàng có hay không có khả năng trả nợ.
Chúng ta cùng đi vào tìm hiểu thông tin về các biến dự báo, ở đây chúng tôi giải thích các giá trị đã được coding cho tập dữ liệu, đồng thời phân nhóm lại (reclassify) các biến dự báo là biến định tính nhưng có quá nhiều giá trị định tính, cũng như để diễn giải kết quả phân tích đơn giản hơn, tuy nhiên vẫn phải đảm bảo không có sự chênh lệch quá lớn giữa các quan sát:
Dữ liệu gốc đã được coding:
- Existing checking account – Tài khoản tiền gửi (checking account) của khách hàng: là biến định tính với 1: khách không có tài khoản tiền gửi, 2: không có tiền gửi, cũng không có nợ, 3: giá trị tài khoản từ 0 – 200 (Mác – Đức), 4: > 200 (Mác-Đức), tài khoản trên 1 năm.
- Duration in month – Thời hạn tín dụng: đây là biến định lượng theo tháng
- Credit history – Lịch sử thanh toán khoản vay (tín dụng) trước đó, biến định tính: 0: không có các khoản vay tín dụng trước đó hay tất cả các khoản tín dụng (ở các ngân hàng khác) đều được thanh toán, 1: các khoản vay tín dụng trước đó tại ngân hàng này được thanh toán; 2: Các khoản vay tín dụng hiện tại đều đang được thanh toán đều đặn đến bây giờ; 3: chậm trễ trong việc thanh toán các khoản tín dụng trong quá khứ, 4: khoản vay rất lâu chưa thanh toán (tài khoản tín dụng có vấn đề thực sự, nghiêm trọng về rủi ro tín dụng) hay có vay tín dụng tại ngân hàng khác
- Purpose – Mục đích vay tín dụng, biến định tính: 0: khác (mục đích khác hay không rõ mục đích), 1: mua ô-tô mới, 2: mua ô-tô cũ, 3: mua trang thiết bị, mua nội thất, 4: mua ti-vi, radio, 5: mua thiết bị đồ dùng gia đình; 6: mục đích sửa chữa, tu sửa 7: mục đích giáo dục, 8: du lịch, kỳ nghỉ, 9: mục đích đào tạo nghề nghiệp, 10: mục đích kinh doanh
- Credit Amount – Khoản tín dụng của khách hàng, biến định lượng
- Savings account – Tài khoản tiết kiệm, biến định tính: 1: không có tài khoản tiết kiệm/ có nhưng đã rút tiền, 2: dưới < 100 Mác Đức, 3: từ 100 đến 500 Mác – Đức, 4: từ 500 đến 1000 Mác-Đức, 5: trên 1000 Mác Đức
- Present employment since – Kinh nghiệm đi làm, biến định tính: 1: không có nghề nghiệp/ đang thất nghiệp; 2: kinh nghiệm < 1 năm, 3: kinh nghiệm từ 1 – 4 năm, 4: kinh nghiệm từ 4 – 7 năm, 5: kinh nghiệm trên 7 năm
- Installment rate – Tỷ lệ trả hàng tháng dựa trên thu nhập (Installment rate) biến định tính: có 4 cấp độ tăng dần từ 1 đến 4, cấp độ 4 tỷ lệ trả là nhiều nhất
- Personal status and sex – Tình trạng hôn nhân và giới tính, biến định tính: 1: nam/ đã ly hôn và ở riêng, 2: nữ/ đã ly hôn và ở riêng, 3: nam/ còn độc thân, 4:nam/ đã kết hôn, 5: nữ/ độc thân. Trong tập dữ liệu phạm vi chỉ từ 1 đến 4.
- Other debtors / guarantors – Đồng sở hữu khoản tín dụng/ người bão lãnh, biến định tính: 1: không có, 2: có đồng sở hữu, 3: có người bảo lãnh
- Present residence since – Số năm cư trú tại địa phương, biến định tính: có 4 mức độ tăng dừng từ 1 đến 4, với 4 là số năm sống nhiều nhất.
- Property – Tài sản hiện tại có (giá trị nhất), biến định tính: 1: bất động sản, 2: không phải bất động sản/ bảo hiểm nhân thọ, 3: không phải 1 và 2, xe ô-tô hay tài sản khác, 4: không có tài sản
- Age (years) – Độ tuổi, biến định lượng
- Other installment plans – Tham gia các dịch vụ trả góp khác, biến định tính: 1: tại ngân hàng khác, 2: tại các cửa hàng khác, 3: không có
- Housing – Tình trạng sở hữu bất động sản, biến định tính: 1: đang ở miễn phí, 2: thuê, 3: chủ sở hữu
- Number of existing credits at this bank – Số lượng tài khoản tín dụng (tại ngân hàng, bao gồm cả hiện tại), biến định lượng
- Job – Nghề nghiệp: 1: thất nghiệp và không có kỹ năng, không cư trú trong thành phố, 2: thất nghiệp, cư trú trong thành phố, 3:có kỹ năng/ lành nghề/ là nhân viên công chức, 4: quản lý / tự làm chủ / nhân viên, cán bộ có trình độ cao
- Number of people being liable to provide maintenance for – Số người bảo trợ, nuôi dưỡng, biến định tính: 1: từ 0 đến 2 người, 2: trên 2 người
- Telephone – Cung cấp số điện thoại, biến định tính: 1: không, 2: có
- Foreign Worker – Là người nước ngoài, biến định tính: 1: không phải. 2: có
Các biến định tính được xử lý lại, các biến còn lại không đề cập tức giữ nguyên
- Existing checking account – Tài khoản tiền gửi (checking account): 1: không có tài khoản tiền gửi, 2: không có tiền gửi, 3: có tiền gửi trong tài khoản
- Credit history – Lịch sử thanh toán khoản vay (tín dụng): 1: đã trả hết tại các ngân hàng trước, 2: thanh toán hết hay không có vấn đề tại ngân hàng này; 3: có vấn đề trong việc thanh toán
- Purpose – mục đích vay tín dụng: 1: mua ô-tô, 2: sinh hoạt, gia đình, 3: khác
- Savings account – tài khoản tiết kiệm: 1: không có tài khoản, 2: có tài khoản, giá trị dưới 1000 Mác Đức, 3: trên 1000 Mác Đức
- Present employment since – Kinh nghiệm đi làm: 1: không có việc và kinh nghiệm dưới 1 năm; 2: kinh nghiệm từ 1 đến 4 năm, 3: kinh nghiệm trên 4 năm
- Personal status and sex – Tình trạng hôn nhân và giới tính: 1: nam ly hôn/ độc thân, 2: nam đã kết hôn, 3: nữ
- Job – trình dộ nghề nghiệp: 1: không có kỹ năng, 2: lành nghề, 3: trình độ cao
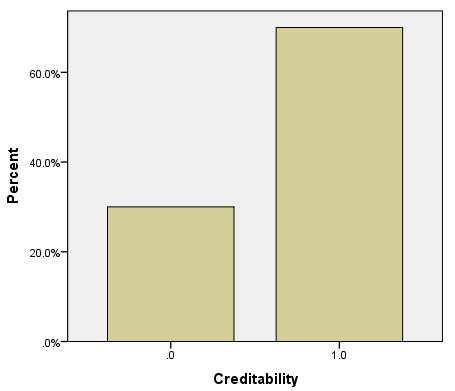
Trong biến mục tiêu là mứ độ tín dụng của khách hàng, thì có 30% là đánh giá xấu, 70% là đánh giá tốt. Dưới đây là một số đồ thị trực quan, lưu ý các bạn xem lại ở trên để nắm thông tin coding của các biến định tính (chú ý các biến được reclassify) để hiểu đồ thị, cách diễn giải tương tự như các ví dụ trước, các bạn có thể xem lại tự diễn giải thử.
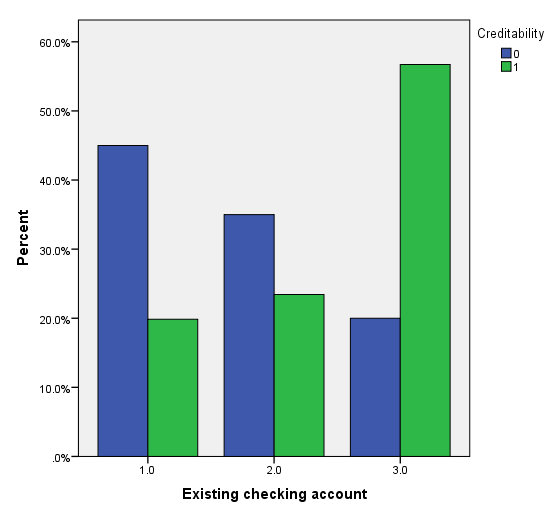
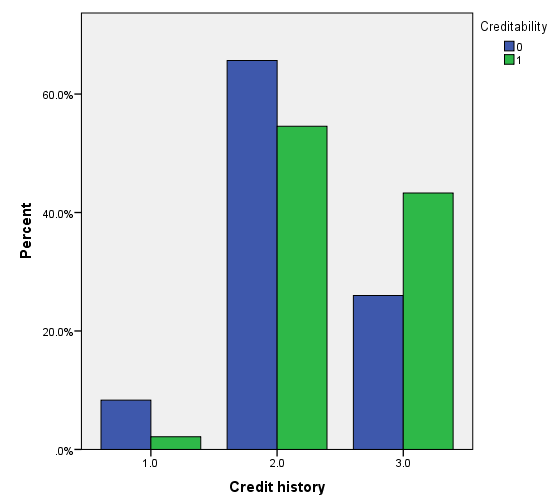
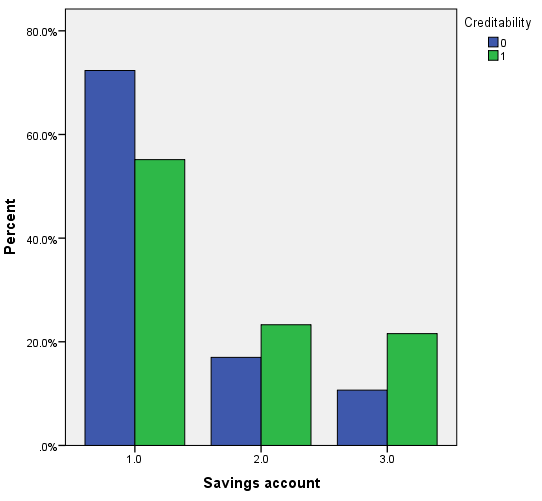
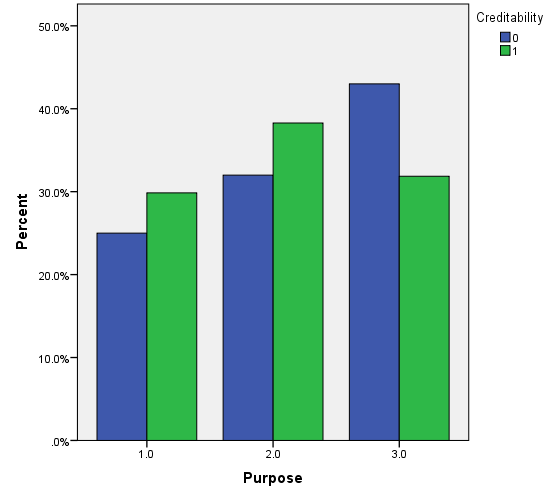
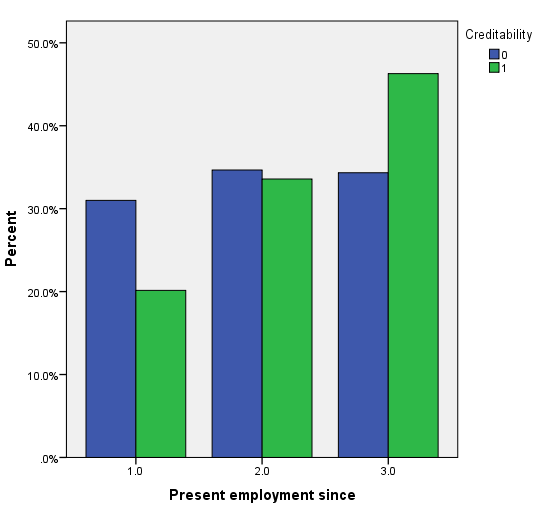
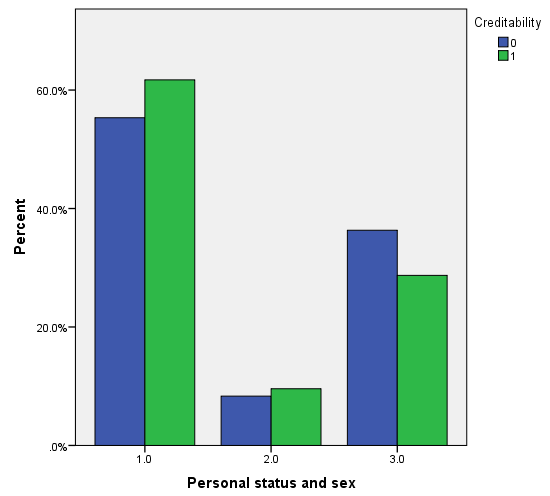
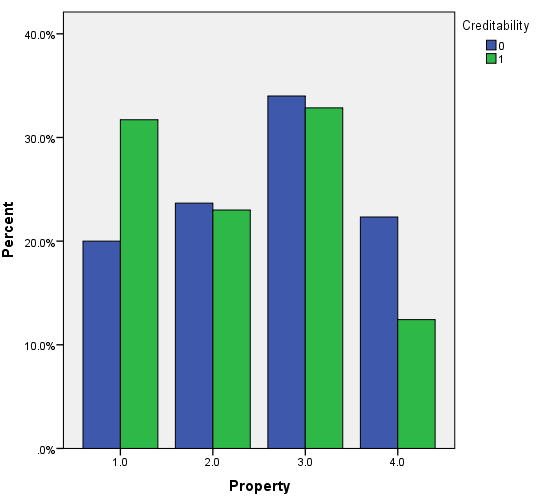
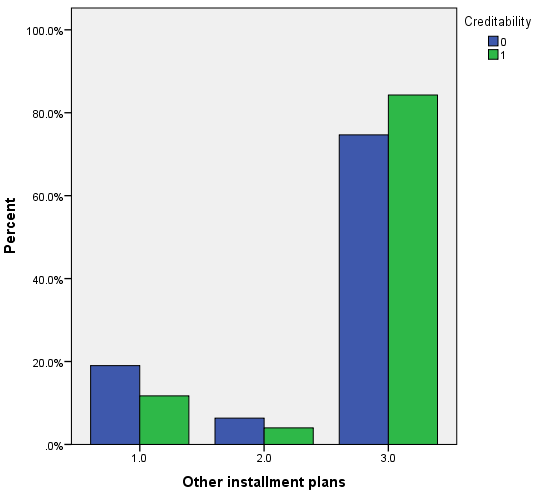
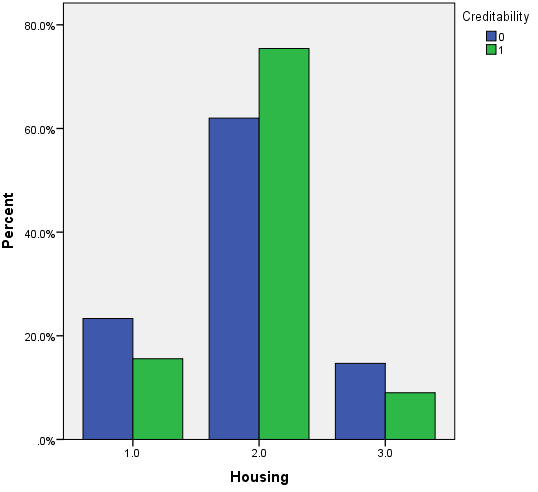
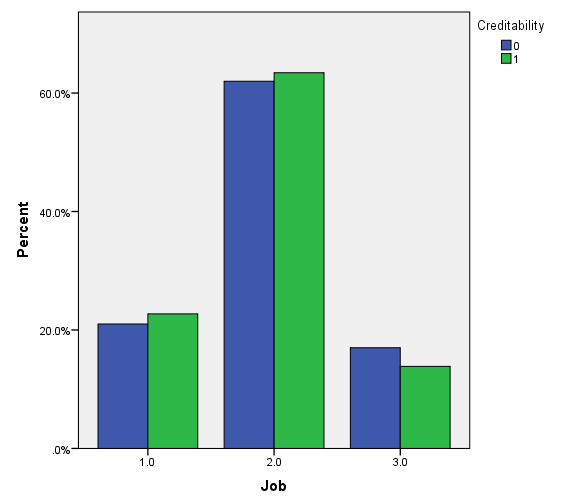
Vì khá nhiều biến cần xét đến nên chúng ta trước tiên sẽ chọn ra các biến phù hợp để phân tích bằng cách sử dụng Score test hay kiểm định Chi bình phương, nếu biến có ý nghĩa phân tích thì cột sig, p-value < 0.05. Kết quả từ SPSS.
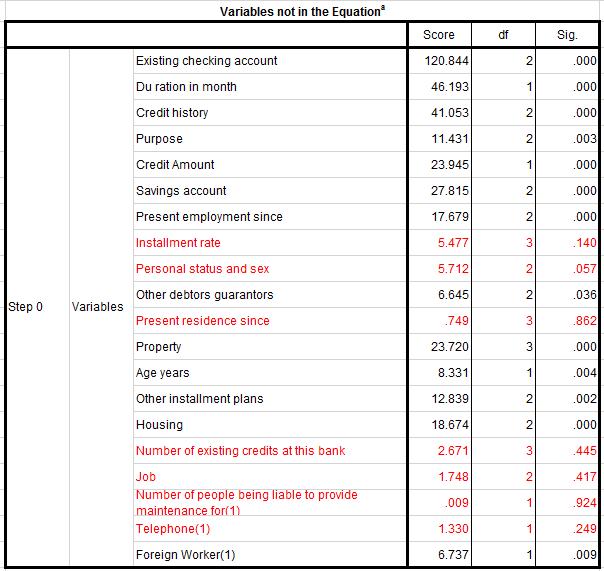
Như vậy chúng ta nên bỏ 7 biến có cột sig có giá trị p-value > 0.05, tức không có mối quan hệ với biến mục tiêu hay không phù hợp để đưa vào mô hình phân tích. Lưu ý thêm đối với biến Foreign worker, khi các bạn thống kê từ dữ liệu ban đầu sẽ thấy có đên 96.3% số khách hàng là người nước ngoài, 3.7% không phải là người nước ngoài. Vì chênh lệch quá lớn nên đối với tập dữ liệu này chúng ta sẽ tạm thời không xét đến biến này trong khi lập model.
Sau khi tiến hành xử lý và tìm hiểu ban đầu tập dữ liệu, chúng ta chia tập dữ liệu thành training và testing như thường lệ, tuy nhiên khác với 2 ví dụ trước ở đây chúng ta chỉ có 1000 quan sát nếu chia tỷ lệ 70/30 thì số quan sát tập test data sẽ khá ít. Nên lần này chúng ta thử chia dữ liệu gần tỷ lệ 50/50. Chúng ta cùng đi vào xây dựng mô hình, đối với các biến định tính các bạn lưu ý nhớ set cho các biến định tính categorical (nếu các bạn dùng những phần mềm thống kê)
Kết quả coding từ phần mềm:
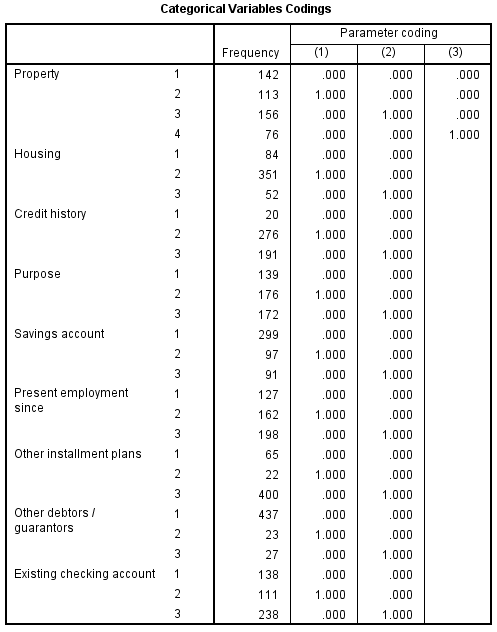
Kết quả đầu tiên khi tất cả các biến được chọn được đưa vào mô hình (phương pháp Enter trên SPSS – đưa tất cả các biến dự báo vào mô hình ở 1 bước duy nhất)
Các bạn có thể thấy khi đưa vào chung mô hình có một số biến giá trị p-value kiểm định Wald test tại cột sig > 0.05, khoảng tin cậy odds ratio (95% CI exp (B)) có chứa giá trị 1 (Ho: β = 0 => Ho: Odds ratio = 1, odds ratio phải hoàn toàn khác 1) tức những biến này không có ý nghĩa phân tích khi chúng được xem có thể không có mối quan hệ với biến mục tiêu xét trong mô hình này.
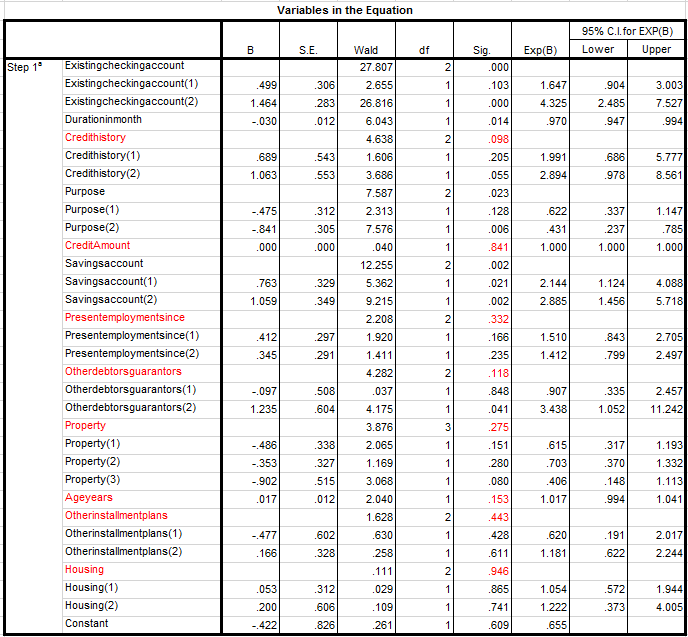
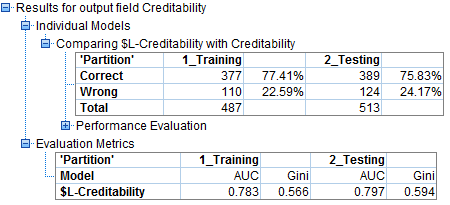
Độ chính xác của mô hình trong việc phân loại mức độ tín dụng của khách hàng ở testing giảm hơn so với training nhưng nhìn chung cả 2 tập khi vận hành mô hình tỷ lệ chính xác không được cao đều dưới 80%, cả giá trị AUC cũng phản ánh điều này.
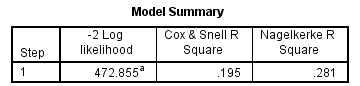
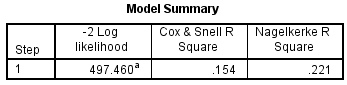
Hệ số R2 cũng không được cao, mô hình chỉ hiệu quả ở mức tương đối, chỉ có 28.1% sự thay đổi trong xác suất thể hiện khả năng biến mục tiêu y đạt giá trị 1 là được giải thích bởi những biến dự báo đang có trong mô hình.

Kết quả kiểm định Hosmer & Lemeshow có giá trị p-value > 0.05, tức mô hình phù hợp để phân loại chính xác giá trị positive, ở đây là y = 1 (khách hàng được đánh giá tốt)
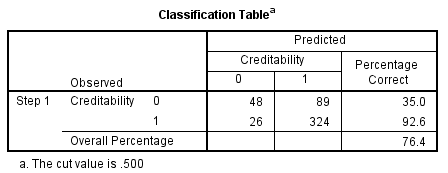
Cùng xem qua Confusion matrix:
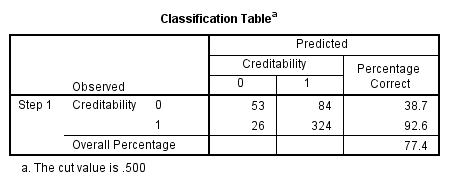
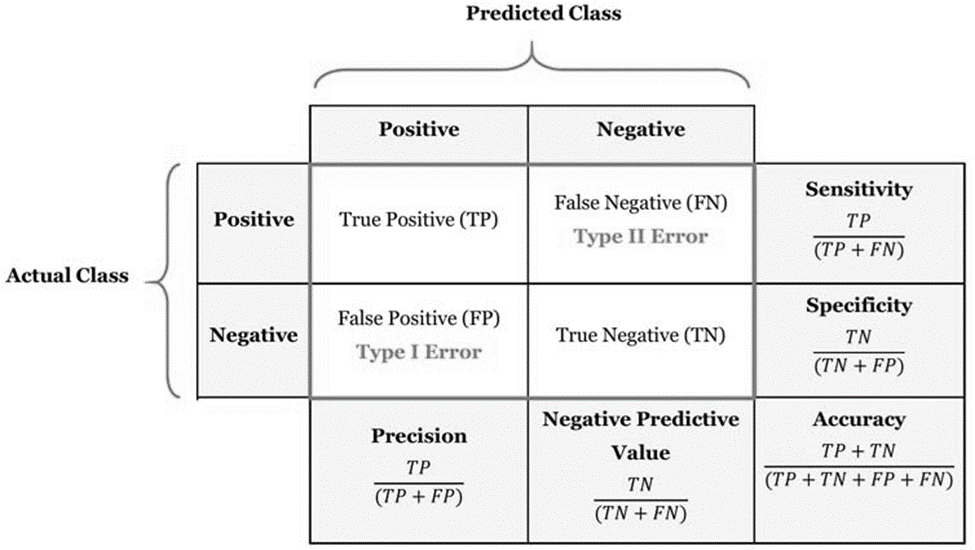
Accuracy tổng thể là 77.4%, khả năng mô hình phân loại chính xác cho cả 2 class là 77.4%
Precision = 324/ (324 + 84) = 80%
Recall (Sentivity) = 324 / (324 + 26) = 92.5%
Khác với ví dụ trước, cả Precision và Recall đều cao cho thấy mô hình thực sự hiệu quả trong việc xác định khách hàng nào là có mức độ tín dụng tốt. Tuy nhiên trong trường hợp mục đích hiện tại của ngân hàng là tìm ra khách hàng nào có khả năng nợ xấu để quản lý rủi ro, đảm bảo lợi nhuận chứ không phải gia tăng phát triển kinh doanh hơn nữa thì mô hình này hoàn toàn không phù hợp.
Nguyên nhân mô hình còn chưa thể phân loại chính xác khách hàng có mức tín dụng xấu.
NPV = 53 /(53 + 26) = 67%, Specificity = 53/ (53 + 84) = 38%
Tức mô hình đã bỏ sót 84 khách hàng có đánh giá mức độ tín dụng xấu, con số khá lớn, và hậu quả còn lớn hơn nữa nếu thực tế sau này 84 khách hàng này không thanh toán khoản nợ, trong khi đó tỷ lệ phân loại chính xác khách hàng mức độ tín dụng xấu chỉ ở 67%
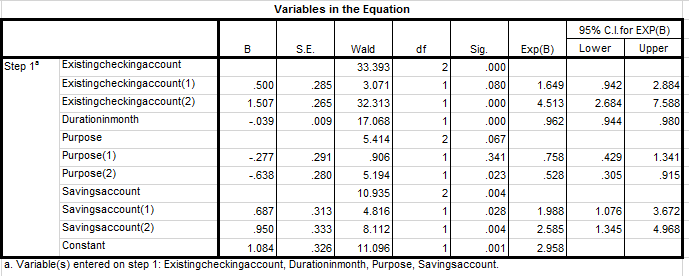
Bây giờ chúng ta thử bỏ các biến dự báo không phù hợp như đã nói:

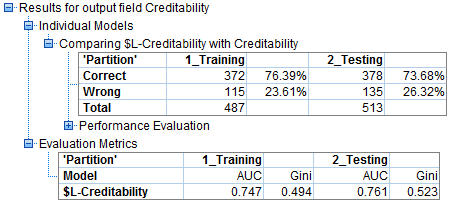
Các bạn chưa cần tính Likelihood ratio test cũng thấy mô hình sau kém hiệu quả hơn mô hình trước, việc giảm biến dự báo qua đó cũng chưa thực sự phù hợp. Nguyên tại sao thì hẹn các bạn ở bài viết trình bày về Overfitting và Underfitting trong một ngày nào đó, hay các bạn cũng có thể tự tìm hiểu trước, theo chúng tôi đây là 2 vấn đề phổ biến mà bất cứ người học vè dữ liệu cũng đều biết
LR = 2 ln (LFull) – 2 ln (LSubset) = – 472.855 – (-497.460) = 24.6
Bậc tự do df = 6 (chênh lệch giữa số biến dự báo mô hình full vs mô hình subset)
P-value tra bảng < 0.05. Tức chúng ta sẽ bác bỏ Ho (Ho: mô hình subset hiệu quả hơn) như vậy mô hình đầy đủ các biến theo LR test là hiệu quả hơn so với mô hình đã giảm bớt các biến. Qua đó khẳng định thêm các biến chúng ta loại bỏ vẫn có ý nghĩa phân tích nếu trong một mô hình đầy đủ. Chi tiết về LR test các bạn có thể xem lại bài viết phần 5.
Kết luận case study dựa trên mô hình đầu:
Nếu ngân hàng quan tâm đến những khách hàng được đánh giá mức độ tín dụng thấp để kiểm soát rủi ro tín dụng, đảm bảo doanh thu:
Chúng ta quan tâm những biến dự báo có hệ số hồi quy âm, và có cột sig có giá trị < 0.05 tức biến này có mối quan hệ với biến mục tiêu. Tại sao là hệ số hồi quy âm? Nhắc lại ngân hàng đang quan tâm đến khách hàng nào có nguy cơ không trả được nợ để dự báo trước rủi ro tín dụng và đưa ra giải pháp.
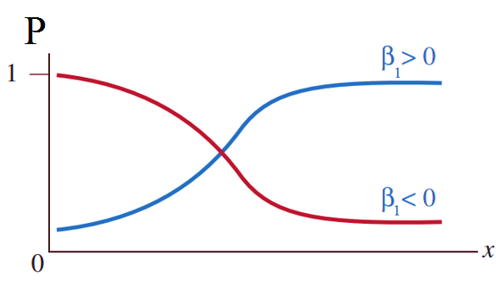
Hình này có vẽ quá quen thuộc với các bạn vì phần nào chúng tôi cũng giới thiệu lại. Nếu xác suất p ước lượng từ phương trình bao gồm các biến dự báo ở trên với hệ số hồi quy tương ứng > 0.5, thì khách hàng được phân loại là tốt, thì ngược lại để khách hàng phân loại là xấu thì xác suất sẽ tiền gần về 0, trên độ thị khi x tăng, β < 0 , p sẽ giảm.
Như vậy nếu xét kỹ cả về tiêu chí ý nghĩa phân tích và hệ số hồi quy giảm chỉ có 2 biến là Duration in month – Thời hạn tín dụng và biến dummy Purpose (2) tách ra từ biến chính Purpose – mục đích, biến Purpose (2) = Purpose (khác) = purpose (mục đích kinh doanh, mục đích học tập – đào tạo, mục đích du lịch) (sau khi đã reclassify) với giá trị 0 không có khách hàng không có mục đích khác và giá trị 1 khách hàng có 1 trong các mục đích kinh doanh,…
Kết luận nếu khách hàng vay với mục đích kinh doanh, mục đích học tập hay du lịch thì nguy cơ bị đánh giá mức độ tín dụng xấu, và có cơ sở nghi ngờ họ không trả được khoản nợ. Còn biến duration, có thể thấy giá trị odds ratio nhỏ hơn 1, tức thời hạn tín dụng tăng 1 tháng thì xác suất để y = 1 sẽ giảm, xác suất sẽ tiến dần về 0, nếu biến này tiếp tục tăng.
Tập dữ liệu còn ít số quan sát nhưng lại có nhiều biến dự báo để xét nên việc chúng ta cũng chỉ có 2 biến thực sự có ý nghĩa để kết luận. Nguyên nhân có thể do phương pháp chúng ta sử dụng trong SPSS là Enter, tất cả các biến đưa vào mô hình trong duy nhất 1 bước mà không có thêm bất kỳ điều kiện nào. Nếu chúng ta sử dụng phương pháp khác điển hình như Forward Selection – phương pháp Stepwise sử dụng Score test để thêm biến dự báo có ý nghĩa vào mô hình, và LR hay Wald test để kiểm tra mô hình có cần loại bỏ các biến không phù hợp, thì kết quả sẽ nhận được tỷ lệ cao nhiều biến dự báo có ý nghĩa phân tích hơn. (cũng như không cần phải tự tay xây dựng 2 mô hình khác nhau như ở trên chúng ta vừa làm). Những phương pháp chọn lựa và đưa biến dự báo vào mô hình hiện tại ở các phần mềm phân tích, cũng như các ngôn ngữ lập trình dùng trong lĩnh vực dữ liệu như R.
Nếu ngân hàng quan tâm đến những khách hàng được đánh giá mức độ tín dụng cao để tiếp cận giới thiệu thêm các dịch vụ về khác về tín dụng:
Trường hợp này chúng ta quan tâm đến hệ số hồi quy > 0 đồng thời, giá trị p-value tại biến này < 0.05 thỏa mãn yêu cầu về có ý nghĩa phân tích. Ở biến Otherdebtorsguarantors(2) tức theo kết quả coding và phần giải thích biến thì đây là biến dummy Otherdebtorsguarantors (người đồng sở hữu) với giá trị 0 – khách hàng không có đồng sở hữu khoản tín dụng và giá trị 1 là ngược lại. Nghĩa là với hệ số hồi quy 1.235, p-value = 0.041 < 0.05, có thể kết luận nếu khách hàng có đồng sở hữu khoản tín dụng thì đánh giá mức độ rủi ro sẽ thấp, được phân loại là tốt, khả năng trả được nợ càng cao. Savings account (1) và (2) cũng có hệ số hồi quy > 0 và p-value < 0.05, nghĩa là nếu khách hàng có tài khoản tiết kiệm, xác suất được phân loại là tốt, khả năng trả được nợ cao. Tương tự như biến Existing checking account, khách hàng có tiền gửi trong tài khoản, xác suất được phân loại là tốt, khả năng trả được nợ cao.
Khác với 2 ví dụ trước, một về dự báo khách hàng đăng ký term deposit, một về dự báo khả năng khách hàng rời dịch vụ, chúng ta chỉ quan tâm đến khả năng y = 1, tập trung vào khách hàng đăng ký term deposit, hay khách hàng rời dịch vụ. Nhưng ở ví dụ này chúng ta quan tâm đến cả 2 nhóm khách hàng, vì nhìn chung đều có ảnh hưởng nhất định đến lợi nhuận.
Tính thử lợi nhuận trên mô hình
Cũng vì lý do trên mà ở ví dụ này chúng ta xem xét cả về mặt hiệu quả kinh doanh nếu sử dụng mô hình này. Giả sử sau một khoảng thời gian dài phân tích, nghiên cứu, ngân hàng nhận thấy rằng nếu mình phân loại đúng 1 khách hàng có độ tín dụng cao và thực sự thanh toán hết nợ thì trung bình họ đạt lợi nhuận là 20% tức 0.2 tuy nhiên nếu phân loại sai 1 khách hàng có độ tín dụng cao nhưng thực chất lại không trả nợ, thì ngân hàng lỗ hoàn toàn tức – 100%. Giải thích đơn giản qua Confusion matrix:
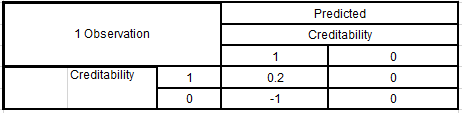
Còn nếu ngân hàng dự báo 1 khách hàng có rủi ro tín dụng cao, tức được phân loại xấu thì dĩ nhiên họ không cung cấp khoản tín dụng do đó không có lợi nhuận cũng không có lỗ.
Trước khi mô hình được xây dựng, thì nếu ngân hàng giữ nguyên tỷ lệ 70% khách hàng được đánh giá tốt, 30% khách hàng được đánh giá xấu như tập dữ liệu gốc, thì sau một khoảng thời gian: lợi nhuận trung bình tính được = 0.2*70% – 30%*(-1) = – 0.16 tức lỗ 16%. Nếu ngân hàng tính được khoản cho vay trung bình là 5000 (Mác Đức) thì lỗ 800 cho 1 khách hàng, tổng lỗ sẽ là 800*1000 = 800000 Mác Đức
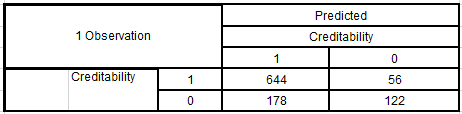
Kết quả phân loại hay dự báo cho tập dữ liệu tổng thể:
Vậy giả sử nếu sử dụng mô hình logistic này vào thực tế và kết quả như trên chính xác hoàn toàn tức khách hàng được phân loại tốt, thực sự trả hết nợ và ngược lại. Lợi nhuận ngân hàng thu được trung bình 1 khách hàng là, nếu khoản cho vay trung bình giữ nguyên là 5000 Mác Đức.
Lợi nhuận = (644/1000)*0.2 + (178/1000)*(-1) = -0.05, tức trung bình lỗ 250 Mác Đức 1 khách hàng, tổng lỗ có thể là 250000.
Thực tế việc xây dựng và chọn lựa giữa các mô hình dựa trên lợi nhuận tính được là rất phức tạp và kết hợp nhiều phương pháp phân tích khác nữa chứ không chỉ đơn giản như trên. Nhưng chúng tôi muốn trình bày để các bạn thấy được phần nào lợi ích của phân tích dữ liệu trong kinh doanh.
Đến đây cũng kết thúc bài viết về ứng dụng hồi quy logisitc trong ngân hàng cũng như kết thúc chuỗi bài viết về hồi quy logistic. Hẹn gặp các bạn ở những bài viết sắp tới.
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.