
 English
EnglishĐồng hành với các bạn trong suốt chặng đường hình thành và phát triển Blog, BigDataUni đã cùng các bạn tìm hiểu Data mining, Predictive analytics là gì và những ứng dụng của nó trong từng lĩnh vực khác nhau, đặc biệt là các thuật toán cơ bản trong khai phá và phân tích dữ liệu như KNN – K láng giềng gần nhất, Decision Tree – Cây quyết định, và các dạng phân tích hồi quy thông dụng như Liner regression và Logistic regression với những ví dụ cụ thể trong ngành tài chính và bán lẻ. Tiếp tục với các chủ đề liên quan đến những thuật toán quan trọng trong Data mining, lần này BigDataUni sẽ giới thiệu đến các bạn phương pháp phân tích Clustering hay thuật toán phân cụm.
Bài viết phần 1, chúng ta sẽ tìm hiểu thế nào là clustering, định nghĩa chính xác, một vài ứng dụng xung quanh thuật toán, và đặc biệt là giới thiệu sơ lược những dạng clustering cốt lõi, trong đó quan trọng và phổ biến nhất là Hierarchical clustering, Partitioning clustering sẽ được giới thiệu sơ lược trước khi đi vào bài viết phần 2 tới ứng dụng và ví dụ cụ thể.
Giả sử bạn là giám đốc bộ phận phát triển kinh doanh của một công ty dịch vụ tài chính, bảo hiểm, dưới bạn có 4 đội chuyên viên tư vấn với nhiều năm kinh nghiệm làm việc trong ngành. Bạn ưu tiên nhóm này sẽ phục vụ các khách hàng lớn, từ cá nhân đến các công ty, những khách hàng mang lại nhiều giá trị lợi nhuận nhất. Tuy nhiên tính cả khách hàng cũ và mới là khá nhiều trên dưới 300 account, và dĩ nhiên cần có sự phân công rõ ràng. Để đạt được năng suất và lợi nhuận tối đa, bạn nên phân thành các nhóm khách hàng rồi phân công theo mức độ phù hợp với những đặc điểm, năng lực của từng đội chuyên viên, và trong mỗi nhóm các khách hàng không được có sự khác biệt với nhau, cần có những điểm tương đồng. Mục đích là dễ đánh giá, dễ xác định được các phân khúc khách hàng nổi trội và quan trọng là phân bổ nguồn lực, kiểm soát, duy trì những hoạt động CRM, giữ chân khách hàng, phát triển các chiến lược marketing nhắm mục tiêu hiệu quả hơn,…
Thế nhưng vấn đề là tất cả các khách hàng đều chưa từng được phân loại, dữ liệu chưa qua xử lý thống kê, (trái với classification, dữ liệu đầu vào đều đã được phân loại) mà lại có hàng chục thuộc tính mô tả khác nhau từ tuổi, thu nhập, quê quán, hành vi,… việc tìm ra tính tương đồng của các khách hàng rồi phân nhóm là cực kỳ khó khăn, tốn nhiều chi phí thời gian.
Vậy làm cách nào chúng ta có thể phân khách hàng thành các nhóm? Xác định mỗi nhóm sẽ thể hiện đặc tính chính gì của khách hàng? Bạn sẽ phải nhờ thuật toán Clustering – phân cụm để giải quyết vấn đề trên.
Nói đến đây có thể nhiều bạn vẫn chưa hiểu vậy để BigDataUni tóm lại:
- Các bạn có nhớ đến các thuật toán phân loại CART, Logistic regression hay không? Dữ liệu đầu vào đều đã được phân loại. Ví dụ ở trên, nếu tập khách hàng đã được phân loại thành 2 nhóm: những khách hàng có khả năng ký hợp đồng tài chính (tiềm năng), những khách hàng không có khả năng ký hợp đồng tài chính (không tiềm năng). Công ty sẽ dùng thuật toán phân loại để dự báo cho những khách hàng mới sau này có tiềm năng hay không tiềm năng dựa trên những đặc điểm, insights tìm được từ tập dữ lấy đó, và công ty sẽ xây dựng các chiến dịch marketing nhắm mục tiêu tốt hơn.
- Ví dụ ngược lại, tập dữ liệu là dữ liệu mới, đã được “clean” tuy nhiên chưa được phân loại, không biết khách hàng nào là tiềm năng và khách hàng nào không, công ty phải đi tìm các đặc điểm tương đồng trong những khách hàng để phân nhóm, và từ những đặc điểm ấy kết hợp với mục đích, chiến lược kinh doanh, công ty sẽ xác định được khách hàng nào sẽ mang lại giá trị kinh doanh cao nhất. Thế nhưng trong một đống các thuộc tính cần xét, và mỗi thuộc tính (biến dữ liệu) có nhiều giá trị khác nhau, và với trên dưới 300 khách hàng, làm cách nào tìm được những khách hàng gần giống nhau? Phải dùng đến clustering
Clustering hay phân cụm được coi là phương pháp quan trọng và ứng dụng phổ biến, không những mang lại lợi ích phân tích mà nó còn hỗ trợ tốt các thuật toán khác. Nguyên nhân, nguồn dữ liệu mà mỗi công ty thu thập và khai thác ngày nay là rất nhiều, clustering cho phép chúng ta hiểu được dữ liệu nhanh chóng khi chưa cần đi sâu vào phân tích, giúp xác định được các “pattern” là các mẫu dữ liệu mà ở đó những đơn vị quan sát bên trong gần giống nhau, khai phá các quy luật, các mối quan hệ tự nhiên tiềm ẩn trong dữ liệu.
Clustering trong một số bối cảnh, dự án phân tích đặc thù, có thể đóng vai trò là công cụ triển khai Data understanding, Data exploration, và Data preparation trong Data mining.
Vậy tóm lại thuật toán Clustering (phân cụm) chính xác là gì?
Theo cách hiểu đơn giản nhất Clustering là phương pháp phân tích qua đó tập dữ liệu sẽ được phân thành nhiều cụm/ nhóm khác nhau, trong mỗi cụm/ nhóm các điểm dữ liệu hay các quan sát sẽ giống nhau, và giữa các cụm/ nhóm có sự khác biệt (các quan sát trong nhóm này khác với các quan sát còn lại ở những nhóm khác).
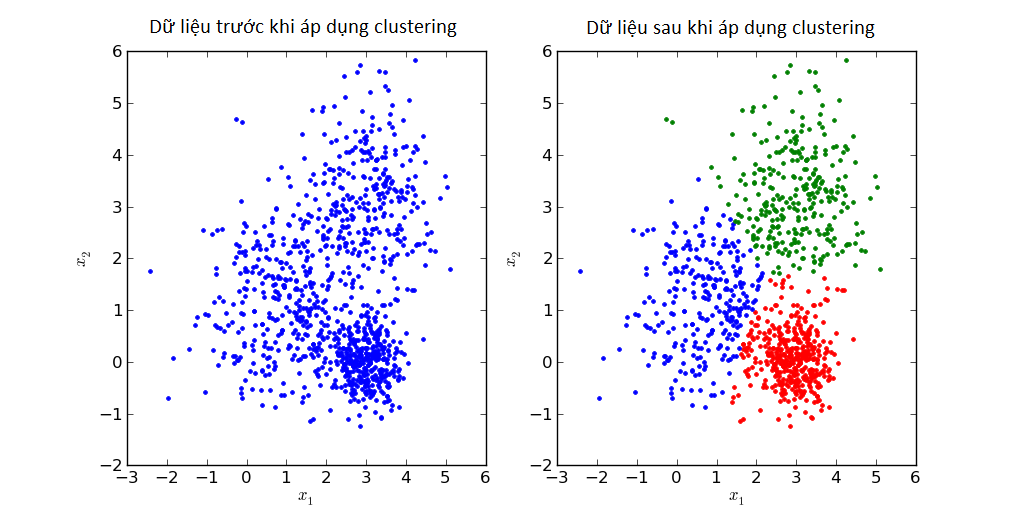
Ví dụ tập dữ liệu khách hàng như đã nói sau khi áp dụng thuật toán phân cụm, giám đốc xác định được 4 nhóm khách hàng chính: (1) nhóm khách hàng thu nhập cao & có khả năng tham gia dịch vụ, (2) nhóm khách hàng thu nhập trung bình & có khả năng tham gia dịch vụ, (3) nhóm khách hàng thu nhập trung bình & không có khả năng tham gia dịch vụ, (4) nhóm khách hàng thu nhập thấp & không có tiềm năng. Các khách hàng ở nhóm 1 phải khác biệt với các khách hàng ở những nhóm còn lại, xét tương tự nhóm (2), (3), (4). Độ chính xác cao thể hiện sự khác biệt rõ rệt và là cơ sở để phân công hiệu quả 4 đội chuyên viên tư vấn vào từng nhóm phù hợp, từ đó phát triển chiến lược marketing, CRM tốt hơn. Và dĩ nhiên chắc các bạn cũng biết nếu một số khách hàng ở nhóm bất kỳ có cùng đặc điểm với các khách hàng ở những nhóm còn lại hay được phân sai nhóm, thì hiệu quả kinh doanh có thể bị tác động. Ví dụ, nhóm (2) và (3) có cùng đặc điểm là khách hàng thu nhập trung bình, vậy nếu không xác định rõ các tiêu chí đánh giá khả năng tham gia dịch vụ thì việc phân cụm sai sẽ xảy ra.
Do đó tóm lại, các bạn nên nhớ rõ, cần nhớ 2 thứ quan trọng: “điểm giống nhau – khi xét bên trong từng nhóm”, “điểm khác biệt – khi xét giữa các nhóm”
Từ “cụm” được sử dụng phổ biến hơn từ “nhóm” thể hiện đúng ý nghĩa của phương pháp clustering. Cụm theo nghĩa tiếng Việt là những vật hay những đơn vị đứng kề nhau và có thể cùng loại ví dụ cụm dân cư tại một chung cư, các cây nhỏ, hoa, lá liền cuống với nhau. Tức khi nhắc đến từ cụm, chúng ta sẽ tự hiểu những gì có trong cụm có điểm giống nhau và gần tương đồng. Còn từ nhóm, thì không bộc lộ rõ điểm này. Nhóm có thể chứa nhiều vật, nhiều thành phần không nhất thiết giống nhau.
Vì thế clustering nên được gọi là thuật toán phân cụm thay vì thuật toán phân nhóm
Thuật toán Clustering còn có tên gọi khác là segmentation analysis, phân tích phân khúc, vì thuật toán này được ứng dụng khá nhiều trong marketing, sales, và CRM với nhiệm vụ xác định các phân khúc khách hàng để đưa ra các chiến dịch quảng cáo, bán hàng nhắm mục tiêu hiệu quả. Chúng ta sẽ tìm hiểu lại ở phần lợi ích.
Clustering được gọi unsupervised classification (phân loại không giám sát) là phương pháp trong unsupervised learning (học không giám sát) – phương pháp xây dựng các model phân tích – dựa trên tập dữ liệu “không có nhãn”, các điểm dữ liệu chưa được phân loại – mục đích tìm hiểu và trích xuất được những thông tin giá trị về đặc điểm, tính chất của những quan sát bên trong. Khác với supervised learning (học có giám sát), clustering không cố gắng phân loại (classify), không cố gắng ước lượng (estimate), hay dự báo (predict) giá trị của biến mục tiêu.
Cơ sở để phương pháp Clustering có thể được triển khai và giúp chúng ta phân cụm tối ưu chính là dựa vào các thuộc tính, các biến,… nằm trong tập dữ liệu, đặc điểm và chất lượng của dữ liệu.
Như vậy chúng ta đã tìm hiểu cơ bản phương pháp clustering là gì, tiếp theo cùng đi qua những ứng dụng, lợi ích chính mà clustering mang lại.
Một vài ứng dụng của Clustering trong một số lĩnh vực
Tương tự như các thuật toán phân loại là CART, hay Logistic regression, Clustering được ứng dụng phổ biến rất nhiều ở các lĩnh vực khác nhau từ kinh tế, y tế, đến khoa học xã hội.
Nguồn hình Javatpoint
Như trong ví dụ ban đầu chúng tôi đề cập đến, clustering sẽ giúp các công ty tăng sự hiệu quả của các hoạt động marketing và bán hàng đa mục tiêu. Ứng dụng clustering trong market segmentation hay customer segmentation thực chất đã được nhắc đến từ rất lâu (từ trước những năm 1970) bởi các chuyên gia phân tích (như Martin Christopher với tài liệu “Cluster analysis and market segmentation” năm 1969, John Saunders với tài liệu “Cluster analysis for market segmentation) nhưng được ứng dụng phổ biến trong 10 năm trở lại đây. Phần lớn nhờ vào sự phát triển của công nghệ kỹ thuật và khoa học dữ liệu.
Nhìn hình minh họa trên các bạn có thể thấy, nếu chúng ta cố gắng đi tìm khách hàng trong tập dữ liệu sao cho phù hợp và tiềm năng cho từng loại sản phẩm nhất định thực sự sẽ rất khó và dĩ nhiên không thể có đủ thời gian để xác định từng khách hàng một cho dù đã ấn định được các tiêu chí cần thiết.
Công việc sẽ dễ dàng hơn rất nhiều nếu có clustering. Clustering cho phép chúng ta phân nhóm các khách hàng trong tập dữ liệu theo nhân khẩu học, hành vi mua sắm,… kết hợp với những hiểu biết, kinh nghiệm về các yếu tố thu hút khách hàng mua hàng, các đặc điểm thể hiện khả năng khách hàng sẽ mua hàng. Từ đó tinh chỉnh những giải pháp bán hàng, marketing phù hợp cho từng nhóm khách hàng tìm được từ Clustering.
Ưu điểm của việc phân khúc khách hàng trong lĩnh vực kinh doanh nói chung không những giúp các công ty tăng được doanh số, tăng được lợi nhuận mà còn có thể tăng được trải nghiệm khách hàng, thỏa mãn nhu cầu khách hàng một cách cá nhân hóa. Hơn nữa có cơ hội giữ chân khách hàng cao hơn, mối quan hệ với khách hàng sẽ bền vững hơn, giảm tỷ lệ rời dịch vụ khi họ luôn thấy được thứ mình cần mà công ty mang lại.
Những loại dữ liệu về khách hàng có thể sử dụng clustering có thể bao gồm chủ yếu:
- Dữ liệu browsing website của khách hàng
- Dữ liệu về nhân khẩu học của khách hàng
- Dữ liệu về hành vi của khách hàng ở các kênh thương mại điện tử, social media
- Dữ liệu lịch sử các giao dịch của khách hàng
- Dữ liệu về khách hàng của bộ phận CSKH (các cuộc đối thoại, liên hệ với khách hàng được thu thập)
- Dữ liệu khách hàng theo mô hình RFM (Recency: thời gian kể từ lần cuối khách hàng mua hàng, giao dịch là khi nào; Frequency: mức độ thường xuyên mua hàng/ giao dịch của khách hàng; Monetary: số tiền khách hàng bỏ ra/ giá trị trung bình đơn hàng…)
Dữ liệu RFM sẽ được chúng tôi trình bày ở bài viết sắp tới khi trình bày ví dụ cụ thể của clustering trong marketing và bán hàng.
Việc áp dụng clustering trong marketing và bán hàng hiệu quả hay không phụ thuộc vào khả năng thu thập dữ liệu khách hàng của các công ty, chất lượng của các nguồn dữ liệụ, nền tảng công nghệ xử lý, và năng lực phân tích.
Đối với những tổ chức bán lẻ, thương mại điện tử, tài chính, ngân hàng, công nghệ truyền thông… khi triển khai những hoạt động bán hàng đa kênh, đa nền tảng, khai thác công nghệ, kỹ thuật hỗ trợ kinh doanh thì dễ dàng tiếp cận không chỉ nguồn dữ liệu khách hàng khác nhau mà còn dữ liệu về các quy trình vận hành, dữ liệu thị trường, dữ liệu đối thủ trong ngành,… vì thế việc ứng dụng Data mining hay Data analytics nói chung và phương pháp clustering nói riêng sẽ có nhiều cơ hội mang về giá trị kinh doanh, đặc biệt xây dựng những chiến lược gia tăng lợi thế cạnh tranh khi ngày nay tốc độ, sự nhanh chóng đang được ưu tiên hàng đầu.
Bên cạnh phân cụm dữ liệu khách hàng, clustering còn hỗ trợ tối ưu lợi nhuận mang lại cho các công ty. Ví dụ một công ty về dịch vụ tài chính tính cả cũ (đang tiếp tục), mới, và tiềm năng thì có hàng trăm dự án lớn nhỏ khác nhau. Với một loạt dữ liệu về thông tin dự án, chi phí bỏ ra, giá trị dự án mang lại, các KPI liên quan, những rủi ro nếu không thành công,… công ty có thể sử dụng clustering để phân nhóm những dự án. Biết được những nhóm dự án nào có giá trị lợi nhuận cao, thấp, hay trung bình, công ty có thể thúc đẩy và kiểm soát hay cân bằng tốt hơn.
Tương tự như ở các công ty bán lẻ, có hàng trăm hàng ngàn loại sản phẩm, với những dữ liệu về doanh số, dữ liệu thu thập từ nhà cung cấp, từ nhà sản xuất, từ các công ty logistics, thậm chí dữ liệu hành vi của khách hàng trên từng sản phẩm (ví dụ thu thập thông qua website thương mại điện tử),… sử dụng clustering các công ty bán lẻ có thể phân nhóm các sản phẩm, biết được mỗi nhóm sản phẩm tác động như thế nào đến lợi nhuận của công ty, từ đó tối ưu danh mục đầu tư của mình, quản lý chúng tốt hơn, và đưa ra các quyết định hợp lý.
Nói chung nếu xét trong lĩnh vực kinh doanh, một tổ chức có nguồn tài sản dữ liệu dồi dào hơn, bao quát mọi hoạt động của tổ chức, liên quan đến mọi khía cạnh thì công cụ clustering có thể được khai thác nhiều hơn.
Ngoài lĩnh vực kinh doanh clustering còn được ứng dụng trong khác ví dụ một số điển hình như:
- Trong lĩnh vực y tế, sức khỏe: clustering được ứng dụng trong tâm lý học, hỗ trợ việc cải thiện và duy trì sức khỏe, nâng cao hệ thống chăm sóc sức khỏe, và ngăn ngừa các loại bệnh. Cụ thể trong các hệ thống chăm sóc sức khỏe, clustering được dùng để xác định các nhóm dân cư, người dân, nhóm những người cần các dịch vụ chăm sóc, hay nhóm những người sẽ được lợi từ các dịch vụ y tế đặc thù ở trong cộng đồng xã hội. Đặc biệt trong thời kỳ dịch bệnh Covid-19, clustering cũng được ứng dụng để ngăn chặn dịch bệnh. Ví dụ tại Iran, clustering kết hợp hệ thống thông tin địa lý (GIS), dựa trện dữ liệu về tình hình dịch bệnh tại các khu vực, hỗ trợ nhận diện xu hướng lây lan của dịch bệnh, xác định khả năng virus có thể lây lan tới đâu từ điểm bắt đầu (nơi ghi nhận ca bệnh đầu tiên). Tổng cộng có 5 cluster đánh giá: với cluster số 0 “tình trạng nguy hiểm ở mức thấp nhất” cho đến cluster số 5 “tình trạng nguy hiểm ở mức cao nhất”, nói nôm na là nguy cơ lây lan. Mục đích của việc ứng dụng clustering là giúp tổ chức chính phủ, và tổ chức y tế tại Iran phối hợp đưa ra các giải pháp ứng phó nhanh chóng, đồng thời tăng cường giám sát các vùng có khả năng lây lan cao, cải thiện điều kiện y tế, hay đưa ra các quy định giãn cách.
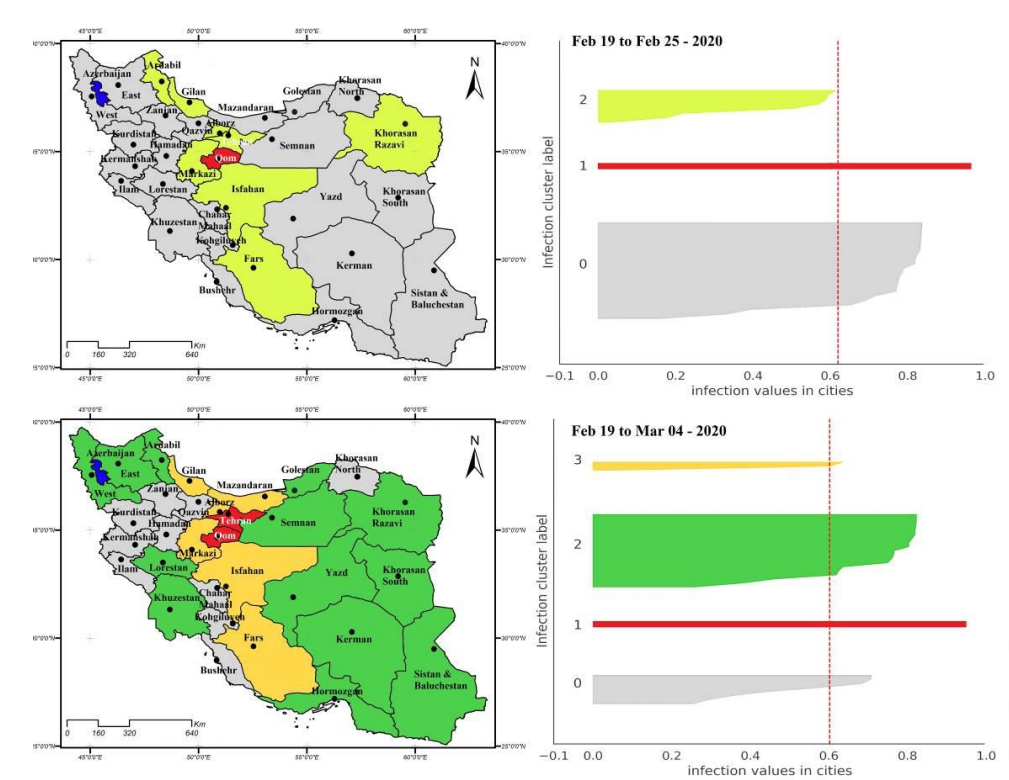
Nguồn hình: “Clustering method for spread pattern analysis of corona-virus (COVID-19) infection in Iran” của tác giả Mehdi Azarafza, Mohammad Azarafza, Haluk Akgün
- Trong lĩnh vực computer vision cụ thể là image recognition (nhận diện hình ảnh), phân cụm có thể được sử dụng để khám phá các cụm hoặc “lớp con” ví dụ trong hệ thống nhận dạng ký tự viết tay. Giả sử chúng ta có một tập dữ liệu gồm các chữ số viết tay, trong đó mỗi chữ số được gắn nhãn là 1, 2, 3, v.v. Lưu ý có thể có một khác biệt lớn trong cách mà mọi người viết cùng một chữ số. Lấy ví dụ số 2. Một số người có thể viết nó có thêm vòng tròn nhỏ ở phần dưới cùng bên trái, trong khi một số người khác thì không. Chúng ta có thể sử dụng phân cụm để xác định các lớp con cho “2”, mỗi lớp đại diện cho một biến thể về cách mà 2 có thể được viết. Khi triển khai các hệ thống nhận dạng, sử dụng các lớp con tìm được từ clustering có thể cải thiện độ chính xác trong việc nhận dạng chữ số.
- Trong lĩnh vực công nghệ thông tin cụ thể là tra cứu website. Ví dụ khi chúng ta điền từ khóa vào công cụ tìm kiếm như Google hay Bing thì sẽ nhận được hàng loạt một trăm, một ngàn, hay hàng triệu kết quả nhận được, là các website, địa chỉ URL dẫn đến trang chứa thông tin liên quan đến từ khóa. Tuy nhiên sẽ có một số website mặc dù có chứa từ khóa nhưng nó không thể hiện nội dung cần tìm. Clustering lúc này được sử dụng để tổ chức lại các kết quả tìm kiếm thành những nhóm khác nhau. Ví dụ nhóm các web chứa nhiều từ khóa trong nội dung và cả ở tên chủ đề => khả năng cung cấp thông tin người dùng cần, nhóm các web chỉ chứa từ khóa trong nội dung => khả năng thấp cung cấp đúng thông tin người dùng cần, nói chung là hỗ trợ người dùng tìm kiếm đúng thông tin mình cần chính xác và dễ dàng. Ngoài web search, clustering còn phân cụm những tài liệu trên các web thành các nhóm chủ đề khác nhau, được sử dụng phổ biến trong quá trình truy xuất thông tin trên web còn gọi là web mining.
Ứng dụng của clustering là nhiều vô kể, chúng tôi không thể gửi hết đến các bạn đặc biệt là ứng dụng của clustering trong hỗ trợ giải quyết các vấn đề về dữ liệu trước khi áp dụng các thuật toán khác trong Data mining, do bài viết có giới hạn, các bạn có thể tham khảo thêm ở những tài liệu khác. Nhưng mong rằng chỉ vài ví dụ nhỏ các bạn cũng hiểu được lợi ích của clustering và vì sao nó là một trong những thuật toán thông dụng nhất của Data mining.
Các dạng phân tích clustering quan trọng
Chúng ta cùng đi vào phần quan trọng là tìm hiểu sơ lược về các hướng tiếp cận chính trong phương pháp clustering.
Cơ chế để clustering hoạt động đó chính là cách thức xác định sự tương đồng (Similarity) và khác biệt (Dissimilarity) giữa các đối tượng quan sát (các object) trong tập dữ liệu. Trong Data mining hay Data analytics, các hệ số, thước đo dùng để tính toán tính tương đồng, giống nhau hay khác biệt là rất đa dạng ví dụ hệ số Jaccard, Sorensen – Dice, hay Simple-matching,… tuy nhiên trong phương pháp Clustering, thì chủ yếu sử dụng Distance metrics như Euclidean distance, Manhattan distance, Minkowki distance,… trong đó Euclidean distance được sử dụng phổ biến nhất.
Các hệ số tính toán mức độ Similarity được sử dụng để mô tả định lượng mức độ giống nhau của hai điểm dữ liệu hoặc mức độ giống nhau của hai cụm: hệ số càng lớn thì hai điểm dữ liệu càng giống nhau. Các thước đo, chỉ số khoảng cách được dùng để định lượng Dissimilarity thì ngược lại: khoảng cách càng lớn thì hai điểm dữ liệu hoặc hai cụm càng không giống nhau.
Công thức Enclidean:
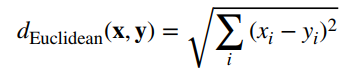
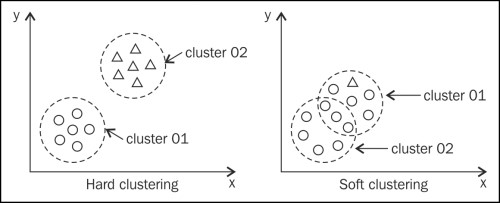
Nếu xét về tính tuyệt đối thì clustering sẽ có 2 dạng là Hard clustering và Fuzzy clustering:
- Hard clustering hiểu đơn giản là một đối tượng quan sát, một điểm dữ liệu hay một object chỉ nằm trong duy nhất 1 cluster mà thôi, tức phải xem xét sự khác biệt giữa các cluster ở mức tối đa, một object bất kỳ khi đã trong 1 cluster thì mặc nhiên nó sẽ khác với các object khác ở những cluster còn lại.
- Fuzzy clustering hay còn gọi Soft clustering thì ngược lại, một đối tượng quan sát, một điểm dữ liệu hay một object có thểm nằm trong 1 hoặc nhiều hơn 1 cluster. Các chuyên gia thường ví von Fuzzy clustering là một dạng clustering kiểu “relaxed”, kết quả từ quá trình phân cụm có thể không cần rõ ràng, phân biệt một cách tuyệt đối như Hard clustering
Nếu dựa trên cấu trúc phân cụm thì clustering có 2 dạng tổng quát:
- Hierarchical clustering: phân cụm theo cấp bậc, gọi là cấp bậc một phần là do tên gọi và một phần là do cách trực quan kết quả clustering. Như ở các ví dụ trên các bạn có thể thấy clustering thường được biểu diễn bằng các hình tròn bên trong là các object giống nhau, còn Hierarchical clustering thường được minh họa bằng biểu đồ Dendrogram. Về cách vẽ Dendrogram không dùng phần mềm phân tích chúng tôi sẽ trình bày ở bài viết phần 2 sắp tới. Các bạn cùng xem qua ví dụ biểu đồ Dendogram, phân cụm các khu vực địa lý có khả năng lây lan dịch bệnh tại Iran sau khi sử dụng clustering. Màu sắc thể hiện các khu vực nằm cùng cluster.
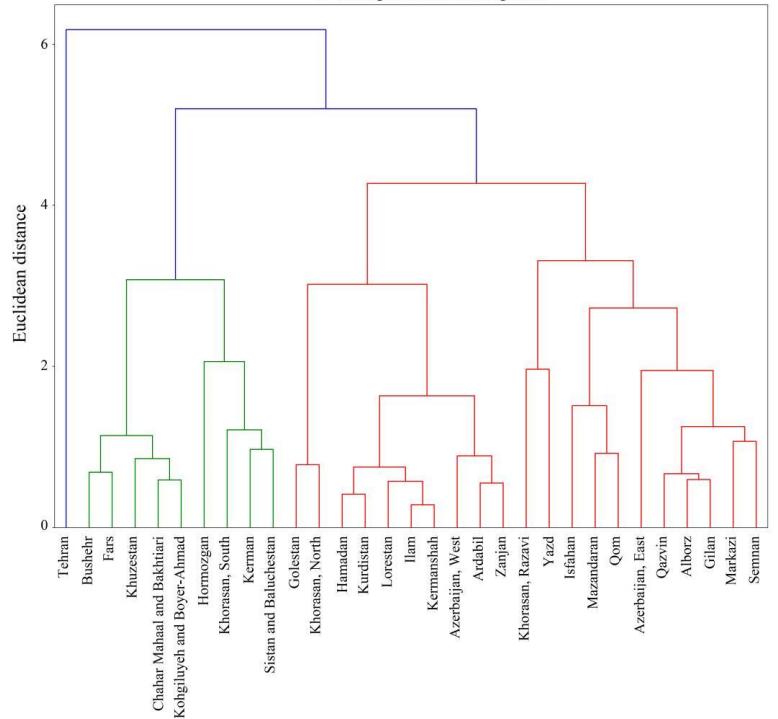
Nguồn hình: “Clustering method for spread pattern analysis of corona-virus (COVID-19) infection in Iran” của tác giả Mehdi Azarafza, Mohammad Azarafza, Haluk Akgün
Hierarchical clustering được sử dụng hiệu quả trong trường hợp chuyên gia phân tích muốn sắp xếp các phân cụm theo cấp bậc.
Hierarchical clustering có 2 dạng chính là Agglomerative (gom tụ) và Divisive (phân tách). Với Agglomerative, bắt đầu mỗi quan sát là một cụm nhỏ của riêng nó. Sau đó, trong các bước tiếp theo, hai cụm gần nhất được tổng hợp thành một cụm kết hợp mới. Bằng cách này, số lượng cụm trong tập dữ liệu sẽ giảm đi một ở mỗi bước. Cuối cùng, tất cả các cụm được kết hợp thành một cụm lớn duy nhất. Còn Dicisive, bắt đầu với tất cả các quan sát sẽ nằm trong một cụm lớn, với các quan sát khác nhau nhất sẽ được tách theo phương pháp đệ quy (recursive), thành một cụm riêng biệt, cho đến khi mỗi quan sát đại diện cho cụm riêng của nó. Agglomerative được sử dụng phổ biến hơn, và được tích hợp trong nhiều phần mềm phân tích. Để minh họa rõ hơn các bạn nhìn vào hình dưới đây, AGNES – Agglomerative Nesting – một tên gọi khác của Agglomerative clustering, tương tự DIANA – Divisive analysis cho Divisive clustering
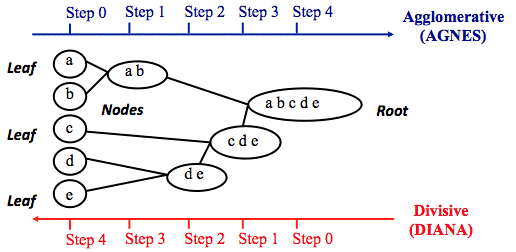
Nguồn hình: Research gate
Trong Hierarchical clutering cụ thể là Agglomerative khi triển khai chúng ta cần xem xét cách gom các quan sát thành từng cụm, và cách gom từng cụm lại thành cụm lớn mà đảm bảo tuân theo cách tính toán khoảng cách với nguyên lý khoảng cách gần thì thể hiện sự tương đồng. Có nhiều cách gom hay còn gọi linkage như Single –linkage (gom cụm theo khoảng cách ngắn nhất), Complete – linkage (gom cụm theo khoảng cách xa nhất), Average – linkage (gom cụm theo khoảng cách trung bình). Trong bài viết phần 2 chúng ta sẽ đi vào ví dụ cụ thể để rõ hơn cách hoạt động của Hierarchical clustering với dạng cơ bản nhất Single –linkage.
- Non – hierarchical clustering: những dạng phân cụm không theo quy tắc thứ bậc bao gồm các phương pháp Partitioning (k-means, k-medoids, k-medians), Density – based (phương pháp clustering dựa trên mật độ các quan sát/ object nằm gần nhau trong không gian dữ liệu), Grid-based (một dạng clustering của Density – based nhưng các cluster được xác định và thể hiện trên một cấu trúc dạng lưới). Đây là 3 dạng clustering thông dụng không theo cấp bậc. Ngoài ra còn có nhiều dạng clustering khác phức tạp hơn như Model-based clustering hay Graph-based clustering.
Trong bài viết lần này và bài viết sắp tới, chúng tôi sẽ chỉ giới thiệu đến các bạn Hierarchical clustering và Partitioning clustering nên các phương pháp khác các bạn vui lòng tham khảo ở những tài liệu khác
Partitioning clustering là phương pháp clustering có thể nói là phổ biến nhất trong số các phương pháp bên cạnh Hierarchical clustering như đã nói ở trên. Điểm khác biệt giữa Partitioning clustering so với Hierarchical đó chính là việc xác định trước có bao nhiêu cluster sẽ phải phân cho tập dữ liệu, ký hiệu là k giống với ký hiệu k trong thuật toán k láng giềng gần nhất. Với n số quan sát/ số object thì k ≤ n, tức mỗi cluster phải chứa ít nhất 1 quan sát hay 1 object. Partitioning clustering là phương pháp phân cụm “one-level” tức một cấp, các cluster không được thể hiện dưới dạng cấp bậc.
Hướng tiếp cận cơ bản nhất trong Partitioning clustering chính là tách cụm độc quyền, giống như Hard clustering, mỗi object, mỗi quan sát chỉ thuộc một cluster duy nhất. Ngoài ra, hầu hết mọi phương pháp trong Partitioning clustering đều xác định sự giống nhau giữa các object và các quan sát dựa trên việc đo lường khoảng cách, thường sử dụng công thức Euclidean.
Nói đơn giản về cách vận hành. Partitioning clustering là phương pháp clustering hướng đến việc tối ưu hóa quá trình phân cụm:
- Chọn số k các cluster cần phân, xác định tập dữ liệu cần phân ra bao nhiêu cụm là hợp lý.
- Tiếp theo xác định số k điểm dữ liệu (còn gọi là các quan sát – record hay object) là các điểm ở vị trí “trung tâm”, đại diện cho mỗi cluster, ví dụ nếu có k = 3 cluster cần phân cụm thì sẽ cần xác 3 điểm trung tâm. Các điểm trung tâm của mỗi cluster sẽ thay đổi.
Lưu ý: trong bài viết, chúng tôi có nhắc nhiều từ “các quan sát”, “các object”, các đối tượng”, thực chất nghĩa tiếng Anh là “records” – bản ghi trong dữ liệu , nghĩa giống nhau chỉ khác nhau tên gọi.
- Với mỗi record, mỗi đối tượng trong tập dữ liệu lúc này chúng ta sẽ tìm những điểm trung tâm gần nhất, sử dụng công thức Euclidean distance. Quan sát nào gần điểm trung tâm của cluster nào nhất sẽ thuộc cluster đó. Như vậy, các cluster ban đầu đã được hình thành.
- Tính toán lại các điểm trung tâm, hay gọi là xác định giá trị đại điện của các điểm trung tâm dựa trên những điểm dữ liệu, những quan sát nằm trong mỗi cluster.
Lúc này xuất hiện các phương pháp tính giá trị cho điểm đại diện cluster. Nếu giá trị đại điện của các điểm trung tâm tính dựa trên giá trị trung bình Mean của các quan sát trong cluster, chúng ta sẽ có K-means clustering. Nếu giá trị đại diện của các điểm trung tâm được tính trên giá trị trung vị Median của các quan sát trong cluster thì gọi là K-medians clustering. Nếu giá trị đại diện của các điểm trung tâm được xác định bằng cách chọn một trong các đối tượng gần điểm trung tâm hiện tại, thì gọi là K-medoids clustering. Như vậy sau khi tính toán các điểm trung tâm lúc này sẽ thay đổi so với ở bước 2, trên đồ thị chúng sẽ dịch chuyển.
- Quay lại làm giống bước 3, xác định các quan sát nào gần điểm trung tâm mới của cluster nào nhất sẽ thuộc cluster đó. Những cluster lúc này sẽ thay đổi, các quan sát thuộc cluster trước đó có thể dịch chuyển sang cluster khác. Tiếp tục chúng ta làm tương tự như bước 4, lại tính toán các điểm trung tâm mới cho các cluster mới thay đổi, rồi lặp lại bước 3 nếu những các điểm trung tâm mới của các cluster có sự thay đổi, dịch chuyển trên đồ thị.
- Quá trình lặp lại chỉ kết thúc khi giá trị đại diện trong các cluster không còn thay đổi, tức các điểm đại diện đã không còn dịch chuyển khi các quan sát trong cluster thay đổi.
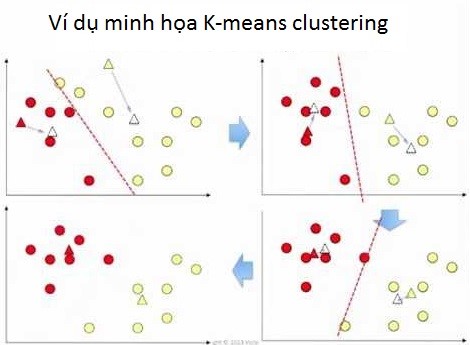
Nguồn hình: Youtube
Các bạn thử nhìn hình trên xem thử mình có hiểu phương pháp k-means clustering là gì không nhé. Ở bài viết phần 2 tới chúng ta sẽ đi vào ví dụ rõ hơn bắt đầu với Hierarchical clustering dạng Single – linkage. Đến đây là kết thúc bài viết phần 1.
Tài liệu tham khảo:
“Cluster analysis and data mining an introduction” – R.S. King
“DATA CLUSTERING Algorithms and Applications” – Charu C. Aggarwal, Chandan K. Reddy
“Data Clustering Theory, Algorithms, and Applications” – Guojun Gan, Chaoqun Ma, Jianhong Wu
“Data Mining Concepts and Techniques” – Jiawei Han, Micheline Kamber, Jian Pei
“Data mining and predictive analytics” – Daniel T. Larose
“Clustering method for spread pattern analysis of corona-virus (COVID-19) infection in Iran” – Mehdi Azarafza, Mohammad Azarafza, Haluk Akgün
Về chúng tôi, công ty BigDataUni với chuyên môn và kinh nghiệm trong lĩnh vực khai thác dữ liệu sẵn sàng hỗ trợ các công ty đối tác trong việc xây dựng và quản lý hệ thống dữ liệu một cách hợp lý, tối ưu nhất để hỗ trợ cho việc phân tích, khai thác dữ liệu và đưa ra các giải pháp. Các dịch vụ của chúng tôi bao gồm “Tư vấn và xây dựng hệ thống dữ liệu”, “Khai thác dữ liệu dựa trên các mô hình thuật toán”, “Xây dựng các chiến lược phát triển thị trường, chiến lược cạnh tranh”.